
목차
최근(2023.10)에 나온 논문들을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
<LLM> Language Models Represent Space and Time (2023.10)
[MIT]
- LLM은 시공간에 대한 linear representation을 학습할 수 있다.
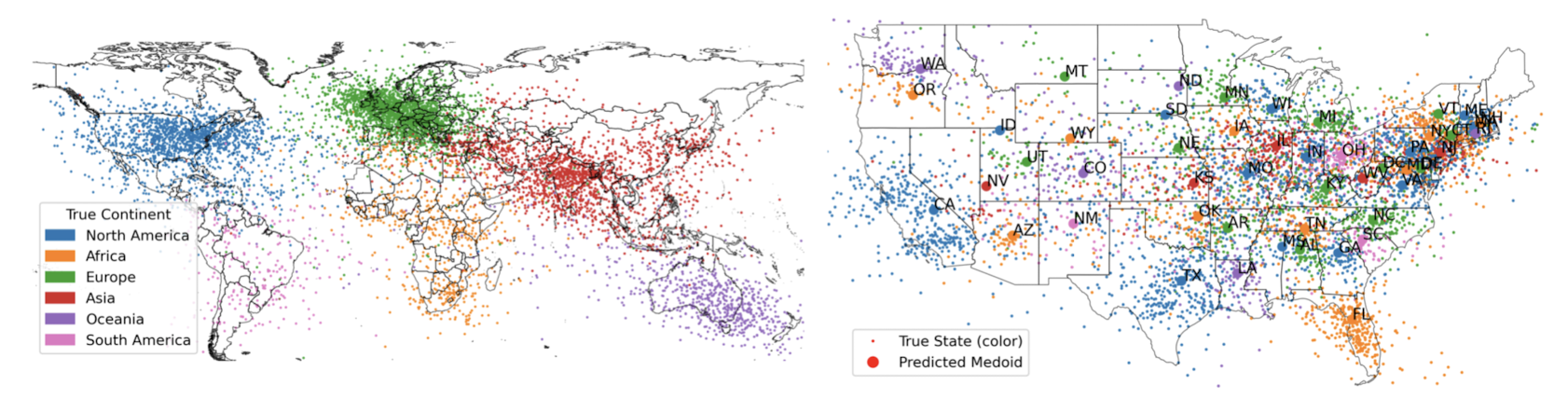
- 실험 결과에 따르면 모델이 생성하는(build) representation은 linear하다.
- 또한 모델 성능은 prompt 변화에 꽤 강건한 모습을 보인다.
- 도시나 자연적 랜드마크와 같은 다른 종류의 entity 전체를 아울러 이와 같은 경향이 나타난다.
- linear ridge regression probes
- Metric : R2 & Spearman rank correlation
- LLaMA-2 7B, 13B, 70B 모델에 대한 probes를 학습
- 특정 neuron이 entity의 시간과 공간 정보에 특히 민감하게 반응하는 것이 관측됨
- 기존 연구에서의 한계는 모델 및 학습 데이터 선정에 기인. 본 논문에서는 각각 100x, 10x 사이즈를 채택함으로써 유의미한 결과를 도출.
출처 : https://arxiv.org/abs/2310.07064
<Instruction> RA-DIT: Retrieval-Augmented Dual Instruction Tuning
[Meta]
- LLM을 재조정하여 retrieval 능력까지 갖추도록 하는 경량화 fine-tuning 방법론.
(1) LM이 retrieved infromation을 더 잘 이해할 수 있도록, (2) retriever가 더욱 relevant result를 반환할 수 있도록 update

- 사전학습된 LLaMA 모델을 사용
- dual-encoder 기반의 dense retriever, Dragon+를 사용
- LM-ft(Language Model Fine-Tuning)
- supervised fine-tuning objective
- insturction 앞에 붙는 "background" 영역을 통해 fine-tuning prompt를 증강.
- retrieved information은 더욱 잘 활용하고 distracting content는 잘 무시할 수 있게 됨
- R-ft(Retriever Fine-Tuning)
- generalized LM-Supervised Retrieval(LSR)을 이용하여 query encoder를 업데이트
- 이를 통해 retriever는 문맥적으로 더욱 관련있는 결과를 반환할 수 있게 됨
- 이는 곧 LLM의 preference와 일치하게 된다는 것을 의미
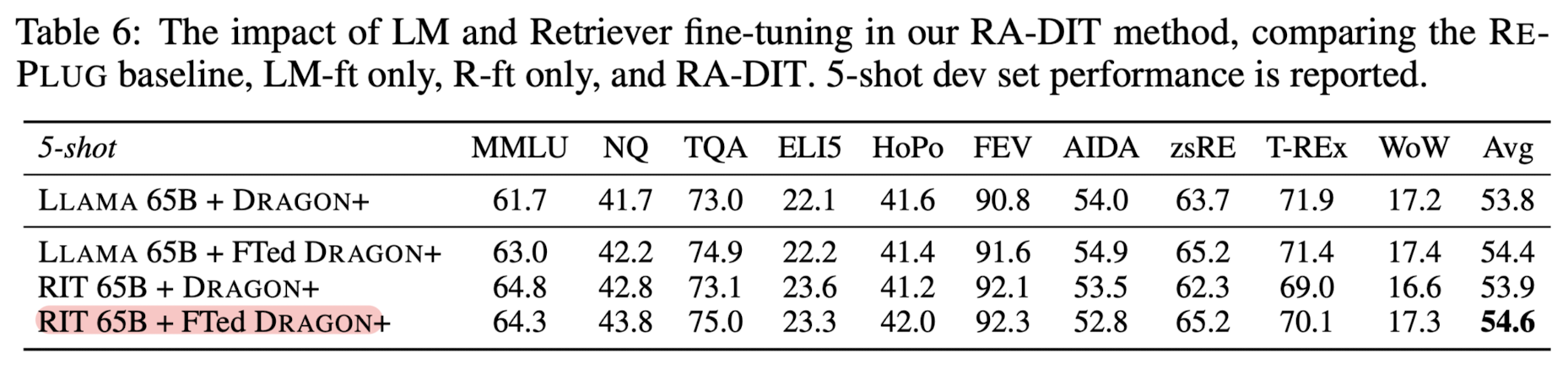
- ATLAS 11B 모델을 8개의 knowledge-intensive task에서 크게 압도
- 언어 모델과 retriever는 독립적으로 최적화되고 instruction-tuning을 통해 융합되는 것이 기존의 RALM(Retrieval-Augmented Language Model)보다 좋은 방식임
- MMLU, TriviaQA 등의 벤치마크
출처 : https://arxiv.org/abs/2310.01352
<LLM> Mistral 7B (2023.10)

[Mistral.AI]
- 뛰어난 퍼포먼스와 효율성을 보여주는 7B 파라미터 언어 모델, Mistral 7B.
- 13B LLaMA 2, 34B LLaMA 1 보다도 뛰어난 성능을 보여줌.
- 빠른 추론을 위한 Group-Query Attention(GQA)
- 처리 가능한 sequence 길이를 확장하기 위한 Sliding Window Attention(SWA)
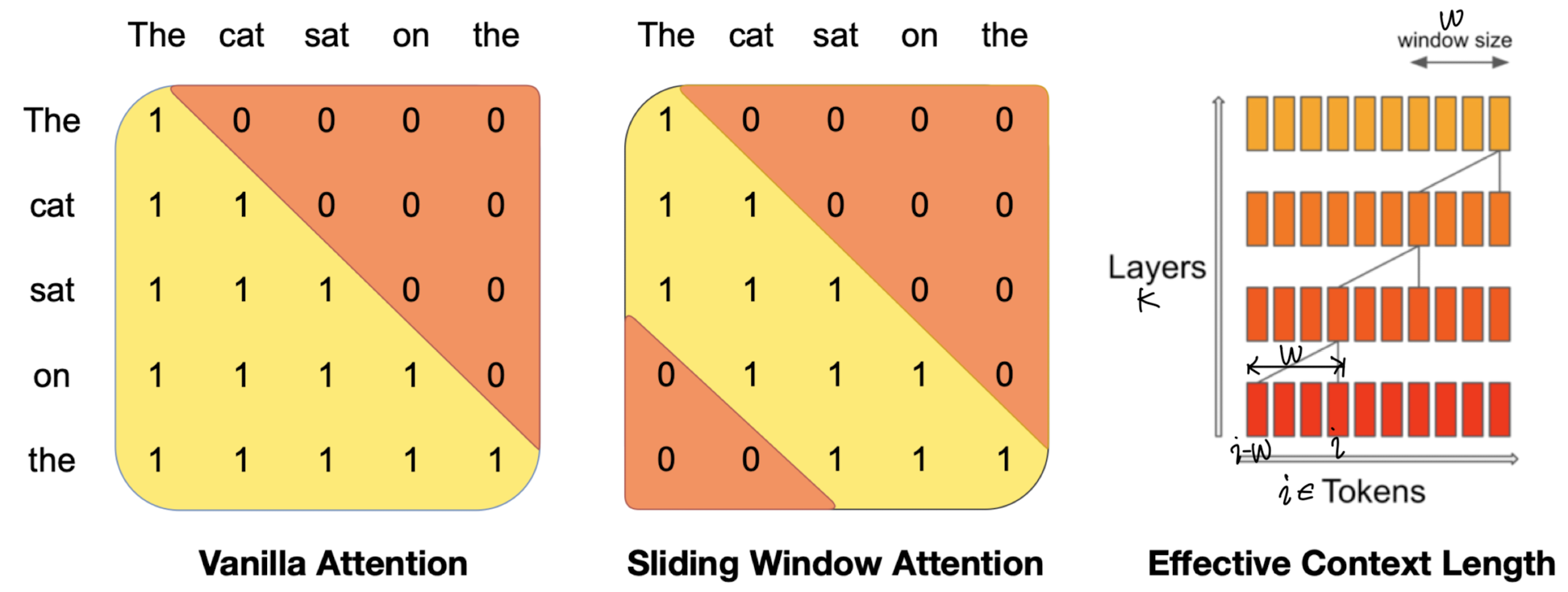
- Sliding Window Attention
- sequence 길이에 quadratic 연산량을 가지는 vanilla attention을 개선
- 최근 W개 토큰끼리 attend하는 방식
- next token을 예측할 때 cache에 저장되지 않은 token들도 영향을 줄 수 있는 방식
- k개의 attention layer를 거치게 되는 경우, 정보는 k x W 개 토큰을 거쳐감
- sequence 길이는 16K, 윈도우 사이즈는 W=4096으로 설정
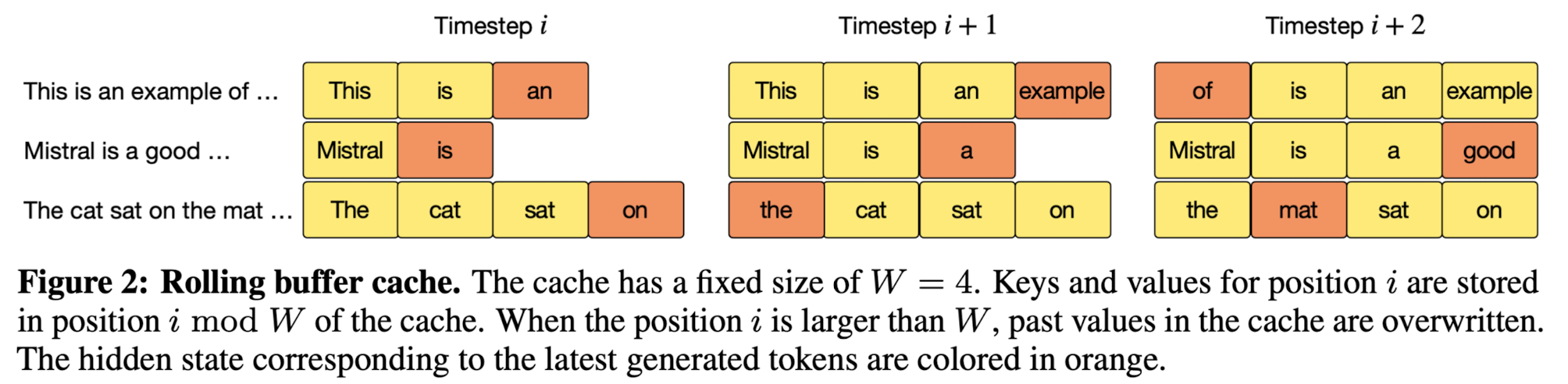
- Rolling Buffer Cache
- 윈도우 사이즈를 초과하게 되는 경우 가장 왼쪽의 토큰부터 비워주는 방식
- 가장 마지막에 생성된 토큰이 주황색으로 표시되어 있음
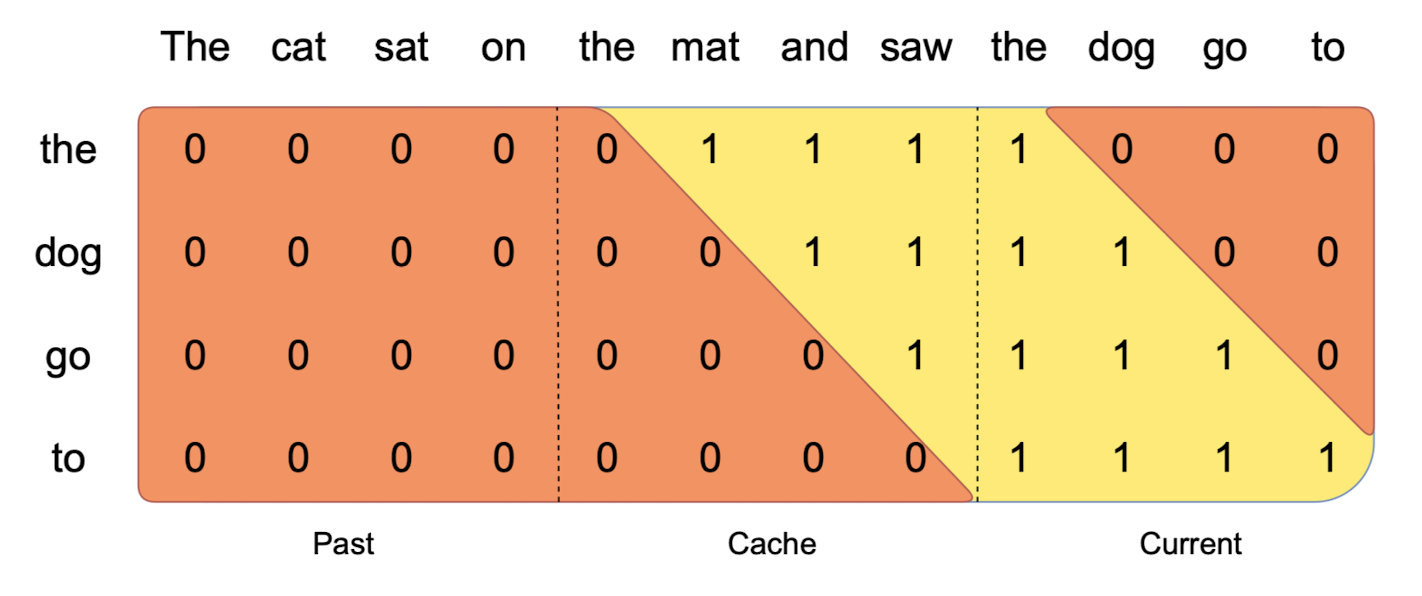
- Pre-fill and Chunking
- 메모리 사용을 제한하기 위해 긴 sequence는 'past, cache, current' 단위로 쪼개짐
- cache에는 sequence 전체가 아닌 일부 chunk만 들어가는 구조가 됨
- HuggingFace에 저장된 instruction dataset을 활용한 Instruction Finetuning 진행
- MT-Bench에서 모든 7B 모델을 넘어서고 일부는 13B 모델에도 견줄 정도의 성능
- Adversarial Attack에 강건할 수 있는 system prompt
Alaways assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.
'Paper Review' 카테고리의 다른 글
최근(2023.10)에 나온 논문들을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
<LLM> Language Models Represent Space and Time (2023.10)
[MIT]
- LLM은 시공간에 대한 linear representation을 학습할 수 있다.
- 실험 결과에 따르면 모델이 생성하는(build) representation은 linear하다.
- 또한 모델 성능은 prompt 변화에 꽤 강건한 모습을 보인다.
- 도시나 자연적 랜드마크와 같은 다른 종류의 entity 전체를 아울러 이와 같은 경향이 나타난다.
- linear ridge regression probes
- Metric : R2 & Spearman rank correlation
- LLaMA-2 7B, 13B, 70B 모델에 대한 probes를 학습
- 특정 neuron이 entity의 시간과 공간 정보에 특히 민감하게 반응하는 것이 관측됨
- 기존 연구에서의 한계는 모델 및 학습 데이터 선정에 기인. 본 논문에서는 각각 100x, 10x 사이즈를 채택함으로써 유의미한 결과를 도출.
출처 : https://arxiv.org/abs/2310.07064
<Instruction> RA-DIT: Retrieval-Augmented Dual Instruction Tuning
[Meta]
- LLM을 재조정하여 retrieval 능력까지 갖추도록 하는 경량화 fine-tuning 방법론.
(1) LM이 retrieved infromation을 더 잘 이해할 수 있도록, (2) retriever가 더욱 relevant result를 반환할 수 있도록 update
- 사전학습된 LLaMA 모델을 사용
- dual-encoder 기반의 dense retriever, Dragon+를 사용
- LM-ft(Language Model Fine-Tuning)
- supervised fine-tuning objective
- insturction 앞에 붙는 "background" 영역을 통해 fine-tuning prompt를 증강.
- retrieved information은 더욱 잘 활용하고 distracting content는 잘 무시할 수 있게 됨
- R-ft(Retriever Fine-Tuning)
- generalized LM-Supervised Retrieval(LSR)을 이용하여 query encoder를 업데이트
- 이를 통해 retriever는 문맥적으로 더욱 관련있는 결과를 반환할 수 있게 됨
- 이는 곧 LLM의 preference와 일치하게 된다는 것을 의미
- ATLAS 11B 모델을 8개의 knowledge-intensive task에서 크게 압도
- 언어 모델과 retriever는 독립적으로 최적화되고 instruction-tuning을 통해 융합되는 것이 기존의 RALM(Retrieval-Augmented Language Model)보다 좋은 방식임
- MMLU, TriviaQA 등의 벤치마크
출처 : https://arxiv.org/abs/2310.01352
<LLM> Mistral 7B (2023.10)
[Mistral.AI]
- 뛰어난 퍼포먼스와 효율성을 보여주는 7B 파라미터 언어 모델, Mistral 7B.
- 13B LLaMA 2, 34B LLaMA 1 보다도 뛰어난 성능을 보여줌.
- 빠른 추론을 위한 Group-Query Attention(GQA)
- 처리 가능한 sequence 길이를 확장하기 위한 Sliding Window Attention(SWA)
- Sliding Window Attention
- sequence 길이에 quadratic 연산량을 가지는 vanilla attention을 개선
- 최근 W개 토큰끼리 attend하는 방식
- next token을 예측할 때 cache에 저장되지 않은 token들도 영향을 줄 수 있는 방식
- k개의 attention layer를 거치게 되는 경우, 정보는 k x W 개 토큰을 거쳐감
- sequence 길이는 16K, 윈도우 사이즈는 W=4096으로 설정
- Rolling Buffer Cache
- 윈도우 사이즈를 초과하게 되는 경우 가장 왼쪽의 토큰부터 비워주는 방식
- 가장 마지막에 생성된 토큰이 주황색으로 표시되어 있음
- Pre-fill and Chunking
- 메모리 사용을 제한하기 위해 긴 sequence는 'past, cache, current' 단위로 쪼개짐
- cache에는 sequence 전체가 아닌 일부 chunk만 들어가는 구조가 됨
- HuggingFace에 저장된 instruction dataset을 활용한 Instruction Finetuning 진행
- MT-Bench에서 모든 7B 모델을 넘어서고 일부는 13B 모델에도 견줄 정도의 성능
- Adversarial Attack에 강건할 수 있는 system prompt
Alaways assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.