
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Stanford University]
GPT-4를 이용하여 Nature, ICLR 두 학회의 페이퍼를 review.
고품질 peer review를 받기 어려운 지역의 연구자들에게 유용할 것으로 보임.

배경
연구 결과에 대해 peer review를 받는 것은 해당 분야의 발전과 직접적인 관련이 있습니다.
이미 오랜 시간에 걸쳐 많은 연구자들은 서로의 연구 성과를 review하며 각 분야를 발전시켜왔습니다.
그러나 최근 (특히) 인공지능 분야에 대한 관심이 뜨겁고 실제 연구 성과들도 엄청나게 쏟아져 나오는 상황에서 고품질의 review를 제공할 수 있는 연구자가 부족한 실정입니다.
일례로 컴퓨터 공학 관련 가장 권위있는 학회인 ICLR(International Conference on Learning Representation)에 대한 submission의 수가 2018년 기준 960개였던 것이 2023년 기준 4966개입니다.
실력과 깊이를 갖춘 연구자의 수는 한정적인데 평가해야 하는 연구들은 너무나도 많기 때문에 이런 상황이 연구 분야에서는 심각한 문제로 제기되고 있습니다.
특히 이는 주변에서 고퀄리티 리뷰를 받기 힘든 지역의 연구자들에게 더욱 심각한 문제로 다가옵니다.
본 논문에서는 이러한 문제점을 극복하기 위한 방법으로 GPT-4를 paper review에 활용할 수 있는지에 대해 면밀히 확인한 내용을 담고 있습니다.
Experiments & Results
Generating Scientific Feedback using LLM
OpenAI의 GPT-4를 이용하여 실험을 진행합니다.
우선 PDF로부터 전체 논문을 parsing합니다.
그리고 GPT-4에게 전달할 paper-specific prompt를 생성합니다.
이는 논문의 '제목, 요약, 도형 및 표 제목, 주 텍스트'를 이어 붙임으로써 생성됩니다.
이를 통해 GPT-4는 'single-pass' 방식으로 피드백을 생성해냅니다.
Data
- Nature family journals
- 8,745 comments from 3,096 accepted papers
- universality and variation in human-based scientifi feedback
- ICLR
- 6,505 comments from 1,709 papers
- expert feedback on both accepted and rejected papers
- User Study and Survey
- 308 researchers from 110 US institutions
- 자신들의 paper에 대해 LLM이 생성한 피드백에 대해 utility & performance를 평가한 survey 데이터
- 메일로 survey를 요청. Gradio를 통해 paper를 제출하고 GPT-4의 피드백을 받아본 뒤 survey(20$지급)를 제출하는 형식
Retrospective Evaluation
LLM feedback significantly overlaps with human-generated feedback
위에 나타난 두 개의 데이터셋(from Nature, from ICLR)을 활용하여 human feedback과 LLM feedback 간의 중첩도를 확인합니다.
Nature의 경우 GPT-4가 생성한 comments의 57.55%가 적어도 한 명의 reviewer에 의해 제기된 적이 있었고,
각 reviewer로부터의 comment와 비교했을 때는 약 1/3(30.85%)가 중첩되었다고 합니다.
reviewer끼리의 중첩도를 확인했을 때 약 28.58% 였다고 하니 오히려 사람과 GPT-4의 review가 공통 특징을 더 많이 지니고 있는 것으로 이해할 수 있습니다.
특히 ICLR 데이터셋의 경우 rejected된 submission도 포함하고 있는데, 왜 rejected되었는지에 대한 human reviewer의 설명과 LLM의 설명이 유사한 경향을 나타낸다는 것 또한 확인이 되었습니다.
LLM could generate non-generic feedbacks
만약 LLM이 제공하는 피드백이 어떤 paper에 대해서든지 통용될 수 있는 내용으로만 구성되어 있다면 지금까지의 평가는 잘못된 것이라고 볼 수 있겠죠.
예를 들어 우리가 사주를 보러갔는데 '당신은 먼 훗날 사망할 것입니다..'라는 말을 늘어놓으면 100% 확률로 맞는 이야기긴 하니까요.
본 논문에서는 같은 journal로부터 나온 같은 카테고리 내 논문들을 섞어서 LLM의 피드백을 기존과 동일한 방식으로 비교해 보았습니다.
그 결과 사람으로부터의 피드백과 LLM으로부터의 피드백 중첩 비율이 Nature 기준 30.85% -> 0.43%로, ICLR 기준 39.23% -> 3.91%로 급락하는 것이 확인되었습니다.
즉, LLM이 같은 카테고리 내 논문 전반에 걸쳐 적용 가능한 보편적인 내용의 피드백을 제공한 것이 아니라 paper-specific한 피드백을 제공하고 있다는 것입니다.
Prospective User Study and Survey
본 연구에서는 단순히 과거의 논문에 대한 사람 & LLM 피드백을 비교한 결과를 제시하는 것을 넘어,
실제 연구자들에게 LLM으로 생성한 feedback을 제공하고 이것이 얼마나 유용했는지에 대해 평가한 내용을 조사했습니다.
110개의 미국 기관에 소속된 308명 연구자들을 대상으로 survey를 수행했다고 밝혔습니다.
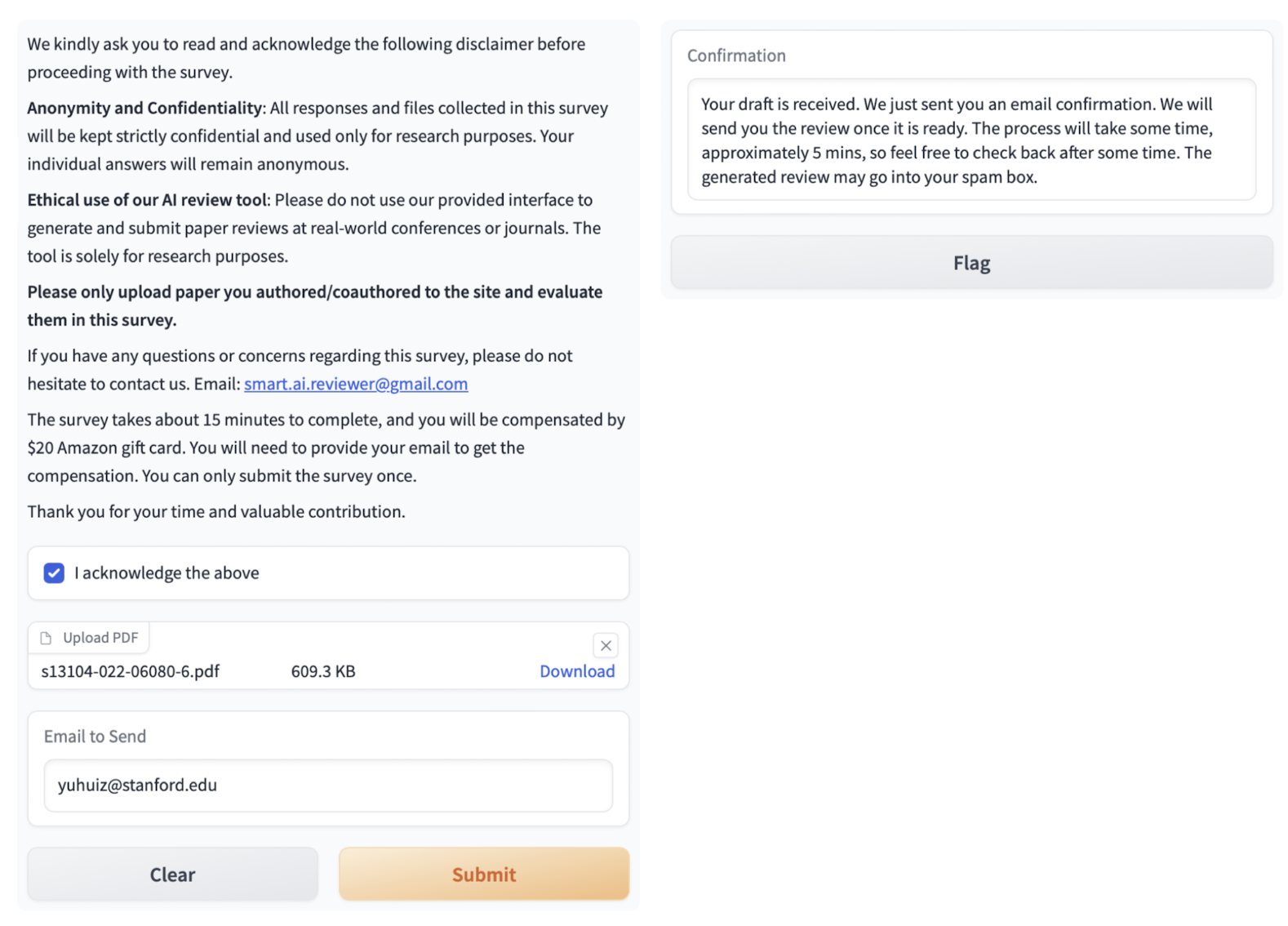
조사를 위해서 online Gradio demo를 이용했다고 하는데요, 유저들은 paper를 기존 PDF 형식으로 업로드하고 review를 전달받을 이메일을 기입하게 되어 있습니다.
업로드하는 paper는 GPT-4의 학습 기간을 벗어난 2021년 9월 이후 제출한 것으로 한정됩니다.
Researchers find LLM feedback helpful
50.3%의 연구자들이 LLM의 피드백을 유용하다고 생각한다고 응답했고, 7.1%는 아주 유용하다고 생각한다고 응답했습니다.
일부(20.4%)는 사람의 피드백보다도 유용하다고 답한 결과가 놀랍습니다.
심지어 이 survey에 참여한 연구자 중 50.5%에 달하는 연구자가 이후에 이 시스템을 또 사용할 의향이 있다고 밝혔습니다.
이는 앞으로의 발전에 대한 기대감에 기인한 수치라고도 볼 수 있겠네요.
LLM could generate novel feedback not mentioned by humans
LLM은 human reveiwer이 간과하거나 놓쳤던 포인트에 대해서 적절히 지적해주기도 했다고 합니다.
그렇게 생각했다고 느낀 연구자의 비율이 65.3%에 달한다고 하니 LLM이 예상보다도 훨씬 paper-specific한 피드백을 생성해낸다고 유추해볼 수 있겠습니다.
개인적 감상
굉장히 시의적절한 논문이라는 생각이 듭니다.
아주 최근에 지인이 학회에 논문을 제출하고 이에 대한 rebuttal을 받고 이에 대한 응답을 제출하는 등의 과정을 멀리서 지켜볼 수 있었는데요, 요즘엔 워낙 많은 사람들이 AI 업계에 뛰어들고 또 연구 성과를 제출하다보니 심각한 문제가 될 수 있다는 생각을 했습니다.
어쩌면 길이가 짧지 않은, 그리고 pdf와 같은 형식의 파일을 언어 모델이 해석할 수 있도록 하는 연구가 여기에 활용될 것은 아주 당연한 수순이었는지 모르겠습니다.
다만 이러한 접근 방식이 결국 기존의 문제를 해결해줄 수 있는지는 잘 모르겠습니다.
인공지능 모델이 반환하는 결과에 대해서는 항상 신뢰도의 문제가 존재하는데, 그럼 결국 다시 그 모델을 검증하기 위한 과정을 거쳐야 될지도 모르는 일이구요.
물론 모델의 성능이 누구나 납득 가능한 수준이라면 이를 참고용으로 활용하는 것도 큰 도움이 될 수 있겠지만,
일종의 실험 효과처럼 배경 지식이 들어간 상태에서는 객관적인 판단과 사고를 하기가 쉽지 않으니 오히려 LLM의 피드백이 방해 요소로 작용할 수도 있지 않을까 싶은 생각이 들었습니다.
또한 아직까지 이미지, 그래프, 도표 등의 자료를 전혀 해석하지 못한다는 점이 치명적인 단점으로 다가오는 것 같습니다.
사실 파싱된 텍스트만을 가지고 논문 내용을 이해한다는 것은 사실상 불가능에 가까운데,
결국엔 관련 자료들을 이해하지 못하다보니 사람의 피드백에서와 달리 LLM의 피드백에서는 ablation study에 대한 강조가 덜할 수밖에 없지 않았나 싶습니다.
이 부분을 해결하면 언어 모델의 활용도가 비약적으로 상승하지 않을까 싶은 생각도 듭니다.
출처 : https://arxiv.org/abs/2310.01783
Can large language models provide useful feedback on research papers? A large-scale empirical analysis
Expert feedback lays the foundation of rigorous research. However, the rapid growth of scholarly production and intricate knowledge specialization challenge the conventional scientific feedback mechanisms. High-quality peer reviews are increasingly difficu
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Stanford University]
GPT-4를 이용하여 Nature, ICLR 두 학회의 페이퍼를 review.
고품질 peer review를 받기 어려운 지역의 연구자들에게 유용할 것으로 보임.
배경
연구 결과에 대해 peer review를 받는 것은 해당 분야의 발전과 직접적인 관련이 있습니다.
이미 오랜 시간에 걸쳐 많은 연구자들은 서로의 연구 성과를 review하며 각 분야를 발전시켜왔습니다.
그러나 최근 (특히) 인공지능 분야에 대한 관심이 뜨겁고 실제 연구 성과들도 엄청나게 쏟아져 나오는 상황에서 고품질의 review를 제공할 수 있는 연구자가 부족한 실정입니다.
일례로 컴퓨터 공학 관련 가장 권위있는 학회인 ICLR(International Conference on Learning Representation)에 대한 submission의 수가 2018년 기준 960개였던 것이 2023년 기준 4966개입니다.
실력과 깊이를 갖춘 연구자의 수는 한정적인데 평가해야 하는 연구들은 너무나도 많기 때문에 이런 상황이 연구 분야에서는 심각한 문제로 제기되고 있습니다.
특히 이는 주변에서 고퀄리티 리뷰를 받기 힘든 지역의 연구자들에게 더욱 심각한 문제로 다가옵니다.
본 논문에서는 이러한 문제점을 극복하기 위한 방법으로 GPT-4를 paper review에 활용할 수 있는지에 대해 면밀히 확인한 내용을 담고 있습니다.
Experiments & Results
Generating Scientific Feedback using LLM
OpenAI의 GPT-4를 이용하여 실험을 진행합니다.
우선 PDF로부터 전체 논문을 parsing합니다.
그리고 GPT-4에게 전달할 paper-specific prompt를 생성합니다.
이는 논문의 '제목, 요약, 도형 및 표 제목, 주 텍스트'를 이어 붙임으로써 생성됩니다.
이를 통해 GPT-4는 'single-pass' 방식으로 피드백을 생성해냅니다.
Data
- Nature family journals
- 8,745 comments from 3,096 accepted papers
- universality and variation in human-based scientifi feedback
- ICLR
- 6,505 comments from 1,709 papers
- expert feedback on both accepted and rejected papers
- User Study and Survey
- 308 researchers from 110 US institutions
- 자신들의 paper에 대해 LLM이 생성한 피드백에 대해 utility & performance를 평가한 survey 데이터
- 메일로 survey를 요청. Gradio를 통해 paper를 제출하고 GPT-4의 피드백을 받아본 뒤 survey(20$지급)를 제출하는 형식
Retrospective Evaluation
LLM feedback significantly overlaps with human-generated feedback
위에 나타난 두 개의 데이터셋(from Nature, from ICLR)을 활용하여 human feedback과 LLM feedback 간의 중첩도를 확인합니다.
Nature의 경우 GPT-4가 생성한 comments의 57.55%가 적어도 한 명의 reviewer에 의해 제기된 적이 있었고,
각 reviewer로부터의 comment와 비교했을 때는 약 1/3(30.85%)가 중첩되었다고 합니다.
reviewer끼리의 중첩도를 확인했을 때 약 28.58% 였다고 하니 오히려 사람과 GPT-4의 review가 공통 특징을 더 많이 지니고 있는 것으로 이해할 수 있습니다.
특히 ICLR 데이터셋의 경우 rejected된 submission도 포함하고 있는데, 왜 rejected되었는지에 대한 human reviewer의 설명과 LLM의 설명이 유사한 경향을 나타낸다는 것 또한 확인이 되었습니다.
LLM could generate non-generic feedbacks
만약 LLM이 제공하는 피드백이 어떤 paper에 대해서든지 통용될 수 있는 내용으로만 구성되어 있다면 지금까지의 평가는 잘못된 것이라고 볼 수 있겠죠.
예를 들어 우리가 사주를 보러갔는데 '당신은 먼 훗날 사망할 것입니다..'라는 말을 늘어놓으면 100% 확률로 맞는 이야기긴 하니까요.
본 논문에서는 같은 journal로부터 나온 같은 카테고리 내 논문들을 섞어서 LLM의 피드백을 기존과 동일한 방식으로 비교해 보았습니다.
그 결과 사람으로부터의 피드백과 LLM으로부터의 피드백 중첩 비율이 Nature 기준 30.85% -> 0.43%로, ICLR 기준 39.23% -> 3.91%로 급락하는 것이 확인되었습니다.
즉, LLM이 같은 카테고리 내 논문 전반에 걸쳐 적용 가능한 보편적인 내용의 피드백을 제공한 것이 아니라 paper-specific한 피드백을 제공하고 있다는 것입니다.
Prospective User Study and Survey
본 연구에서는 단순히 과거의 논문에 대한 사람 & LLM 피드백을 비교한 결과를 제시하는 것을 넘어,
실제 연구자들에게 LLM으로 생성한 feedback을 제공하고 이것이 얼마나 유용했는지에 대해 평가한 내용을 조사했습니다.
110개의 미국 기관에 소속된 308명 연구자들을 대상으로 survey를 수행했다고 밝혔습니다.
조사를 위해서 online Gradio demo를 이용했다고 하는데요, 유저들은 paper를 기존 PDF 형식으로 업로드하고 review를 전달받을 이메일을 기입하게 되어 있습니다.
업로드하는 paper는 GPT-4의 학습 기간을 벗어난 2021년 9월 이후 제출한 것으로 한정됩니다.
Researchers find LLM feedback helpful
50.3%의 연구자들이 LLM의 피드백을 유용하다고 생각한다고 응답했고, 7.1%는 아주 유용하다고 생각한다고 응답했습니다.
일부(20.4%)는 사람의 피드백보다도 유용하다고 답한 결과가 놀랍습니다.
심지어 이 survey에 참여한 연구자 중 50.5%에 달하는 연구자가 이후에 이 시스템을 또 사용할 의향이 있다고 밝혔습니다.
이는 앞으로의 발전에 대한 기대감에 기인한 수치라고도 볼 수 있겠네요.
LLM could generate novel feedback not mentioned by humans
LLM은 human reveiwer이 간과하거나 놓쳤던 포인트에 대해서 적절히 지적해주기도 했다고 합니다.
그렇게 생각했다고 느낀 연구자의 비율이 65.3%에 달한다고 하니 LLM이 예상보다도 훨씬 paper-specific한 피드백을 생성해낸다고 유추해볼 수 있겠습니다.
개인적 감상
굉장히 시의적절한 논문이라는 생각이 듭니다.
아주 최근에 지인이 학회에 논문을 제출하고 이에 대한 rebuttal을 받고 이에 대한 응답을 제출하는 등의 과정을 멀리서 지켜볼 수 있었는데요, 요즘엔 워낙 많은 사람들이 AI 업계에 뛰어들고 또 연구 성과를 제출하다보니 심각한 문제가 될 수 있다는 생각을 했습니다.
어쩌면 길이가 짧지 않은, 그리고 pdf와 같은 형식의 파일을 언어 모델이 해석할 수 있도록 하는 연구가 여기에 활용될 것은 아주 당연한 수순이었는지 모르겠습니다.
다만 이러한 접근 방식이 결국 기존의 문제를 해결해줄 수 있는지는 잘 모르겠습니다.
인공지능 모델이 반환하는 결과에 대해서는 항상 신뢰도의 문제가 존재하는데, 그럼 결국 다시 그 모델을 검증하기 위한 과정을 거쳐야 될지도 모르는 일이구요.
물론 모델의 성능이 누구나 납득 가능한 수준이라면 이를 참고용으로 활용하는 것도 큰 도움이 될 수 있겠지만,
일종의 실험 효과처럼 배경 지식이 들어간 상태에서는 객관적인 판단과 사고를 하기가 쉽지 않으니 오히려 LLM의 피드백이 방해 요소로 작용할 수도 있지 않을까 싶은 생각이 들었습니다.
또한 아직까지 이미지, 그래프, 도표 등의 자료를 전혀 해석하지 못한다는 점이 치명적인 단점으로 다가오는 것 같습니다.
사실 파싱된 텍스트만을 가지고 논문 내용을 이해한다는 것은 사실상 불가능에 가까운데,
결국엔 관련 자료들을 이해하지 못하다보니 사람의 피드백에서와 달리 LLM의 피드백에서는 ablation study에 대한 강조가 덜할 수밖에 없지 않았나 싶습니다.
이 부분을 해결하면 언어 모델의 활용도가 비약적으로 상승하지 않을까 싶은 생각도 듭니다.
출처 : https://arxiv.org/abs/2310.01783
Can large language models provide useful feedback on research papers? A large-scale empirical analysis
Expert feedback lays the foundation of rigorous research. However, the rapid growth of scholarly production and intricate knowledge specialization challenge the conventional scientific feedback mechanisms. High-quality peer reviews are increasingly difficu
arxiv.org