
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft, Israel]
- LLM이 사전학습 동안 보지 못했던 정보를 추가 습득하도록 하는 방식 중 fine-tuning과 retrieval-augmented generation (RAG)를 비교
- 두 방식 중에서 RAG가 훨씬 성능이 좋은 것으로 확인됨. 심지어 base with RAG > fine-tuned with RAG
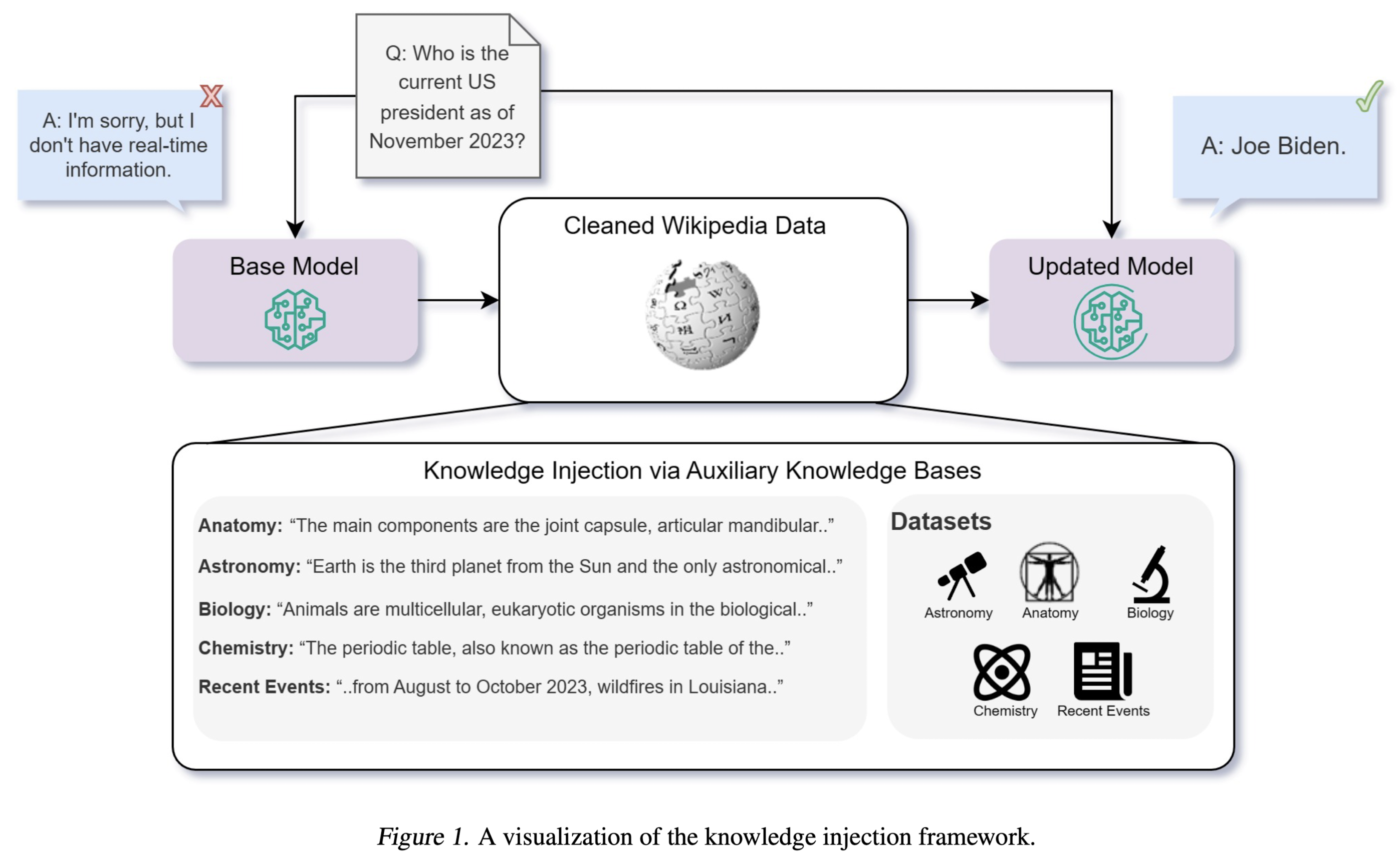
1. Introduction
- LLM은 다양한 도메인의 지식을 보유하고 있음이 잘 알려져 있으나 여전히 명확한 한계가 존재함
- static하다, 즉 새로운 정보가 업데이트 되지 않는다
- 특수한 도메인의 전문 지식은 부족하다
- 최근에는 LLM을 특정 도메인에 adapt하거나 LLM의 knowledge를 update하는 것에 관한 연구가 활발히 이뤄지고 있음
- knowledge injection
- 모델의 knoledge base를 강화하는 방법에는 fine-tuning, in-context learning (ICL), retrieval augmented generation (RAG) 등이 존재함
2. Realted Work
- Knowledge and Language Models
- 만약 모델이 fact를 알고 있다면 이것과 관련된 question에 정확히 답변할 수 있을 것임
- 질문에 대해 random guessing하는 것보다 정답지를 고를 확률이 더 높게 학습된 상태를 'know' 라고 정의


- Previously Seen Knowledge
- knowledge injection의 목표는 모델의 memory를 전부 refresh하는 것이 아니라 특정 도메인에 대한 bias를 유도하는 것임
- Knolwedge and Reasoning
- 현재의 LLM 관련 knowledge evaluation framework는 imperfect
- Causes for Factual Errors
- Domain knowledge deficit: LLM은 학습 당시 접하지 못한 특정 도메인에 대한 전문 지식이 부족할 수 있다
- Outdated Information: LLM은 학습 데이터에 의해 결정된 cutoff date가 있다
- Immemorization: 학습 당시 접했으나 그와 관련된 지식을 보유하지 않고 있을 수 있다
- Forgetting: 사전 학습 이후의 추가 학습 동안 기존 지식을 잊어버릴 수 있다 (catastrophic forgetting)
- Reasoning Failure: fact와 관련된 지식을 소유하고 있음에도 불구하고 이를 적절히 활용하지 못할 수 있다
3. Injecting Knowledge to Language Models
- 일반적인 사전학습만으로는 knowledge-intensive task를 잘 처리하기에 충분하지 않을 수 있음
- 따라서 추가적인 post-processing step을 통해 사전학습 모델의 knowledge를 augment 하고자 함 => knowledge injection
3.1. Problem formulation
- corpus에 대한 온전한 접근 기회가 주어지면 이것을 auxiliary knowledge base로 활용
- knowledge base를 활용하여 생성한 답변이 기존보다 좋아야 함

3.2. Fine-Tuning
- 크게 supervised, unsupervised, reinforcement learning (RL) 방식으로 나뉨
- Supervised Fine-Tuning
- labeled input-output pair를 필요로 함
- 대표적으로 instruction tuning이 power method로 잘 알려져 있음
- instruction tuning은 특히 zero-shot과 reasoning capabilties를 향상시키는 데 큰 도움이 됨
- 그러나 이것도 모델에게 새로운 지식을 가르쳐주는 데 적합한 방식은 아님
- Reinforcement Learning
- 모델의 사전 학습 기간 이후에 RL 또는 RL-inspired optimization 전략을 적용
- reinforcement learning from human feedback (RLHF), direct preference optimization (DPO), proximal policy optimization (PPO) 방식이 잘 알려져 있음
- 이것 역시 LM의 knowledge의 폭을 넓혀주지는 못함
- Unsupervised Fine-Tuning
- 모델 학습에 필요한 추가적인 label이 존재하지 않는 방식
- 주로 continual pre-training 또는 unstructured FT라고 불림
- original LLM의 체크포인트에서 시작하여 causal auto-regressive 방식으로 학습 (predicting the next token)
- 실제 pre-training 대비 굉장히 낮은 learning rate를 사용해야 catastrophic forgetting을 방지할 수 있음
3.3. Retrieval Augmented Generation
- 외부 knowledge source를 사용함으로써 모델의 knowledge-intensive tasks 관련 능력을 확장시키는 테크닉
- input query와 관련이 가장 높은 문서를 찾아 이를 input query에 append하는 방식
- auxiliary knowledge base에 속하는 각 문서에 대한 vector representation (embedding)을 생성
4. Knowledge Base Creation
4.1. Task Selection and Rationale
- MMLU Benchmark
- MMLU 중에서 anatomy, astronomy, college biology, college chemistry 개의 task를 선정
- factual knowledge가 중요한 태스크를 heuristic하게 선정
- Current Events Task
- 현재 사건에 대한 multiple-choice question로 구성된 태스크를 생성
- August-November 2023에 발생한 USA의 사건들을 Wikipedia로부터 획득
4.2. Data Collection and Preprocessing
- Wikipedia로부터 주제별로 관련 기사를 scraping하여 auxiliary dataset을 구축
- 수집된 데이터를 clean chunk로 만들기 위해 엄격한 cleaning process를 적용
4.3. Current Events Task Creation
- GPT-4를 이용하여 specific & high-quality multiple-choice questions를 생성. 정답은 한 개만 존재
- ambiguity는 최소화하여 관련 knowledge 없이는 답변할 수 없는 질문을 생성
- 총 910개의 질문을 생성
4.4. Paraphrases Generation
- GPT-4를 이용하여 데이터셋 augmentation에 활용
- input 데이터의 paraphrased version을 생성
- 각 태스크에 대해 240개의 chunk를 뽑고, 각 chunk마다 2개의 paraphrase를 생성
- current events dataset의 경우, 각 chunk마다 10개의 paraphrase를 생성
5. Experiments and Results
- Experimental Framework
- LM-Evaluation-Harness를 사용하여 객관적인 평가를 진행
- prompt engineering으로 인한 결과물의 차이 등을 방지
- Model Selection
- Llama2-7B, Mistral-7B, Orca2-7B와 같은 popular open-source 모델을 사용
- 추가적으로 bge-large-en을 RAG를 위한 embedding model로 사용 (현 HuggingFACE MTEB 리더보드 SoTA 모델)
- vector-store로 FAISS를 사용
- Configuration Variations
- gird-search를 수행
- baseline 모델과 fine-tuned 모델의 성능, 그리고 RAG를 적용했을 때와 그렇지 않을 때를 비교
- RAG에 사용될 context의 개수를 0에서부터 5까지 확인
- 5-shot vs. 0-shot
- Training Setup
- auxiliary knowledge base를 256 사이즈로 동일하게 chunk로 분할
- <BOS>, <EOS> 스페셜 토큰을 사용하여 original chunk과 구분
- MMLU Results
- 베이스 모델을 generator로 사용하며 RAG를 적용한 것이 가장 좋은 성능일 보임
- fine-tuned with RAG가 가장 좋을 때도 있긴 했지만 일관적인 것은 아니었음
- 5-shot이 가장 좋은 결과로 이어짐

- Current Events Reuslts
- 여러 개의 paraphrase에 대해 fine-tuning하는 것이 꽤나 큰 성능 향상으로 이어지는 것이 확인됨
- 여기서도 fine-tuned 모델에 RAG를 곁들이면 성능이 저하됨

- Fine-Tuning vs. RAG
- fine-tuning 대비 RAG의 장점이 확실하게 확인됨

6. The Importance of Repetition
- current events에 대해서 일반적인 fine-tuning은 Llama2의 성능을 향상시키지 못했을 뿐만 아니라 오히려 훨씬 떨어뜨리는 결과로 이어짐
- Data Augmentation
- 생성형 모델을 augmentation에 활용하는 것이 모델 성능 향상에 큰 영향을 줌
- Monotonic Improvement
- 모델의 정확도와 paraphrase의 개수가 직접적인 상관관계를 보임
- 즉, paraphrase augmentation이 긍정적인 영향을 준다는 뜻
- Learning New Information
- 전체 데이터셋에 대한 iteration이 끝날 때마다 trianing loss가 급혁히 떨어지는 현상이 발생
- 이에 대해 knowledge를 모델이 습득하기 위해서는 관련 정보가 여러 번 노출되어야 한다고 주장
7. Insights
아무래도 가장 큰 궁금증은 다른 fine-tuning 방식과 비교하면 어떨까...입니다.
일반적으로 fine-tuning하면 떠올리는 것이 supervised 방식일텐데 왜 굳이 continual pre-training 방식과 비교했는지에 대해서는 명확한 설명이 제시되지 않은 것 같습니다.
catastrophic forgetting을 방지하기 위해 낮은 learning rate을 사용한다는 것도 처음 알게 되긴 했는데,
그런 식이라면 애초에 사전학습을 진행할 때도 learning rate을 지속적으로 낮춰줘야 처음 습득한 지식이나 정보가 휘발되지 않을 것 같기도 하고..
데이터가 사전학습의 초,중,후반부 중에서 언제 학습되었는지에 따라 해당 지식에 대해 기억하고 있는 정도에 차이가 생기는지도 확인해보면 재밌을 것 같은 주제라는 생각이 들었습니다.
출처 : https://arxiv.org/abs/2312.05934
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
Large language models (LLMs) encapsulate a vast amount of factual information within their pre-trained weights, as evidenced by their ability to answer diverse questions across different domains. However, this knowledge is inherently limited, relying heavi
arxiv.org