
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Abstract
[Google Research, Google DeepMind]
- 주요 내용: 복잡한 자연어 질문에 답하기 위해 다단계 추론과 외부 정보 통합이 필요합니다. 이를 위해 대규모 언어 모델(LLM)과 지식 검색을 결합한 시스템이 개발되었으나, 이들 시스템은 다양한 실패 사례를 겪고 있습니다.
- 문제점: 이러한 시스템들은 외부 지식과의 상호작용이 비차별화(non-differentiable)되기 때문에 직접 end-to-end로 훈련시켜 실패를 수정할 수 없습니다.
- 해결 방안: 이를 해결하기 위해 외부 지식에 대해 추론하고 작용할 수 있는 ReAct 스타일의 LLM 에이전트를 정의합니다.
- ReST 방법론 적용: 이 에이전트는 이전 트래젝토리에 대해 반복적으로 훈련하는 ReST 방법론을 통해 더욱 세밀하게 다듬어집니다. 이 과정에는 AI 피드백을 활용한 성장 배치 강화 학습(growing-batch reinforcement learning)이 사용됩니다.
- 결과: 처음에는 프롬프트된 큰 모델에서 시작하여 알고리즘의 두 번의 반복 후, 훨씬 적은 매개변수를 가진 소형 모델로 세분화되어, 복합적인 질문-응답 벤치마크에서 비교 가능한 성능을 달성합니다.
- 중요성: 이 연구는 다단계 추론을 필요로 하는 언어 모델의 자기 개선(self-improvement)과 자체 정제(self-distillation)에 중요한 발전을 나타냅니다.
1. Introduction
- 간단한 자연어 작업과 복잡한 작업의 차이점: 기본 질문-응답이나 요약과 같은 간단한 자연어 작업에서는 결과의 좋고 나쁨을 쉽게 판단할 수 있지만, 더 복잡한 문제에서는 결과 기반 시스템이 종종 부족합니다. 최근에는 프로세스 감독 접근법이 더 유망한 대안으로 주목받고 있습니다.
- LLM을 활용한 프로세스 기반 워크플로 개발: 인간이 이해할 수 있는 작업 분해를 통해 LLM과 함께 프로세스 기반 워크플로를 정의하는 기술, 프레임워크, 라이브러리가 폭발적으로 증가하고 있습니다.
- LLM 에이전트의 개념: 외부 도구, API, 환경과의 상호작용을 포함하는 다단계 워크플로를 LLM 에이전트라고 부릅니다. 이는 목표를 달성하기 위한 일련의 행동을 수행할 수 있는 시스템입니다.
- ReAct 방법론: ReAct 방법론은 사고-행동-관찰 라운드를 여러 번 반복하며 사고의 흐름과 행동, 관찰을 번갈아가며 진행합니다.
- 에이전트의 실패 사례와 성능 개선: 이러한 에이전트의 실패 사례를 다루고 성능과 견고성을 향상시키는 방법에 대한 질문이 제기됩니다. 결과 기반 시스템의 경우, 해결책은 일반적으로 더 많은 인간 레이블 데이터를 수집하는 것입니다. 그러나 프로세스 기반 시스템의 경우, 이러한 데이터를 수집하는 것이 훨씬 더 도전적이고 비용이 많이 듭니다.
- ReST 알고리즘 적용: 우리는 이 문제를 해결하기 위해 자기 비판, AI 피드백, 합성 데이터 생성을 통해 에이전트의 품질을 향상시키기 위해 집중합니다. 특히, 최근 제안된 강화된 자기 훈련(ReST) 알고리즘을 에이전트 설정에 적용합니다.
- 성능 측정: 검색 에이전트의 전반적인 성능은 Bamboogle 데이터셋과 우리가 직접 구축한 BamTwoogle 데이터셋을 기반으로 다양한 구성 질문에 대한 답변 능력으로 측정됩니다.
- 기여점:
- 자기 비판 기능을 갖춘 ReAct 에이전트를 구축합니다.
- Bamboogle 및 BamTwoogle 데이터셋을 기반으로 한 에이전트의 프록시 평가 메트릭을 정의합니다.
- 에이전트의 성능이 ReST 스타일의 반복적 미세 조정을 통해 효과적으로 향상될 수 있음을 보여줍니다.
- 이 과정은 인간 레이블 훈련 데이터 없이 순전히 단계별 AI 피드백을 통해 이루어집니다.
- 반복적 과정에서 생성된 합성 데이터를 사용하여 미리 훈련된 교사 에이전트와 비교할 수 있는 성능을 가진 훨씬 작은 모델로 에이전트를 정제할 수 있음을 보여줍니다.
2. Background: Search Agent
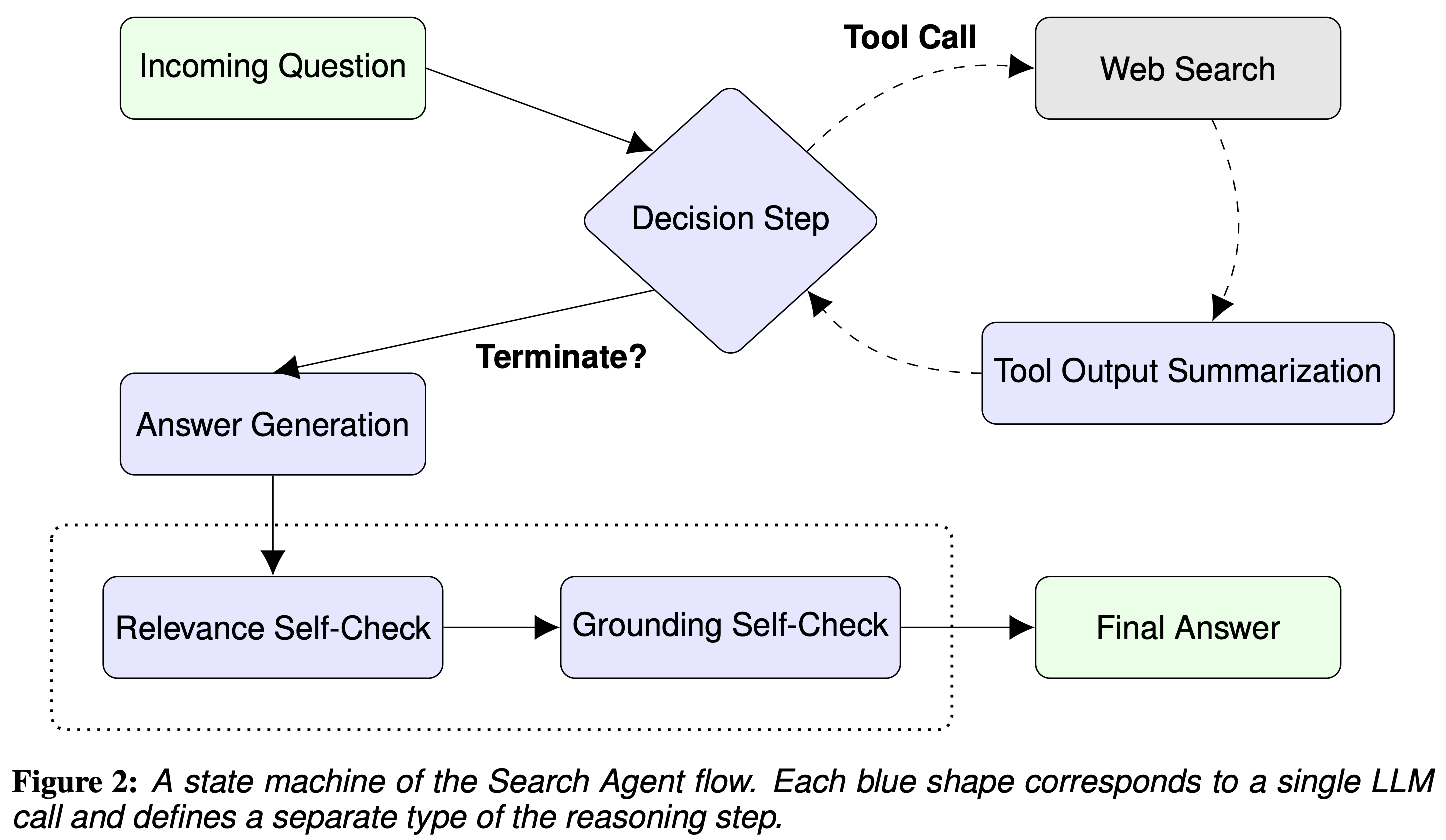
- 검색 에이전트 소개: '검색 에이전트'는 ReAct 방법론의 일종으로, Reflexion을 통합하여 사용합니다. 이는 다양한 지식 탐색형 개방형 질문에 대해 긴 형식의 명시적으로 귀속 가능한 답변을 생성하기 위해 웹 검색을 도구로 사용합니다.
- 에이전트의 작업 흐름:
- 질문 수신 및 검색 루프 실행:
- 에이전트는 추가 정보가 필요한지 결정합니다.
- 필요한 경우 검색 도구를 호출하여 받은 스니펫을 요약한 후 다시 결정 단계로 돌아갑니다.
- 필요하지 않은 경우 검색 루프를 종료합니다.
- 답변 초안 생성: 검색 루프를 통해 수집한 정보를 바탕으로 첫 번째 답변 시도(초안)을 생성합니다.
- 최종 답변 생성을 위한 자체 수정: 최종 답변을 생성하기 전에 두 번의 추가적인 자체 수정 호출을 수행합니다.
- 질문 수신 및 검색 루프 실행:
3. Methods
3.1 프롬프팅
- 검색 에이전트 프롬프트 정의: 검색 에이전트의 흐름을 위한 프롬프트를 수작업으로 정의합니다. 각 단계는 파이썬 코드 형식으로 구성됩니다.
- 코드 사용의 이유: 출력을 다른 시스템과 통합하기 쉽게 구조화된 입력과 출력이 필요합니다. 코드는 구조화된 측면과 자연 언어 측면을 결합합니다.
- 모델 선택: PaLM 2-L 모델이 이러한 작업에 가장 적합하며, 이 모델을 사용하여 프롬프트에서 추론 트래젝토리를 생성합니다.
3.2 구현 세부 사항
- 모델 및 도구 사용: 다양한 크기의 PaLM 2 모델을 사용합니다. Google Q&A API를 검색 도구로 사용하여 상위 k개 스니펫을 반환합니다.
- 샘플링과 선택: 각 단계에 대해 여러 샘플을 생성하고 가장 낮은 혼란도를 가진 샘플을 선택합니다.
3.3 입력 데이터
- 데이터셋 사용: HotpotQA, Eli5, Eli5-askH, Eli5-askS 등 네 가지 데이터셋에서 초기 질문을 제공합니다. 이들은 다양하고 도전적인 2000개의 질문을 포함합니다.
3.4 미세 조정
- 미세 조정 절차: 완성된 검색 에이전트 트래젝토리를 추론 단계로 분할하고 이 단계들로 미세 조정 혼합물을 구성합니다.
3.5 순위 ”보상” 모델
- 샘플 선택 개선: 여러 샘플 중 최상의 샘플을 선택하기 위해 더 정교한 방법을 사용합니다. PaLM 2-L 모델로 샘플을 순위 매깁니다.
3.6 반복적 자기 개선
- 자기 개선 알고리즘:
- PaLM 2-L 모델로부터 추론 트래젝토리를 수집합니다.
- 이 트래젝토리를 미세 조정 혼합물로 변환하고, RM을 사용하여 재순위를 매깁니다.
- 새 모델을 이 혼합물로 미세 조정하고, 성능이 향상되었는지 확인한 후, 과정을 반복합니다.
- 자체 증류 알고리즘: 이 자기 개선 과정에서 생성된 미세 조정 데이터를 사용하여 더 작은 모델을 훈련시키면 자체 증류 알고리즘이 됩니다.
4. Evaluation
4.1 BAMBOOGLE
- Bamboogle 데이터셋 사용: Bamboogle 데이터셋은 검색 에이전트의 주요 평가 도구입니다. 이는 Google 검색으로는 답을 찾을 수 없지만 Wikipedia에서 필요한 증거를 찾을 수 있는 2단계 질문으로 구성됩니다.
- 평가 방식: 검색 에이전트가 생성하는 개방형 답변의 특성상 정확한 일치를 메트릭으로 사용하기 어렵습니다. 따라서 수동 판단 또는 PaLM 2-L “base” 모델을 사용한 자동 평가(auto-eval)를 실행합니다.
4.2 자동 평가(Auto-Eval)
- 시간 및 비용 효율성: 인간 평가보다 시간과 비용이 덜 드는 자동 평가를 도입합니다. 자동 평가는 인간 평가와 높은 상관관계를 보입니다.
- 다양한 질문에 대한 사용: 최적의 샘플링 온도 결정, 모델 크기별 체크포인트 선택, 자기 개선의 다음 단계 진행 여부, 여러 트래젝토리 사용의 성능 영향 등에 대한 질문에 답하기 위해 사용됩니다.
- 훈련 세트로 사용 안 함: Bamboogle은 훈련 세트로 사용되지 않으며, 프롬프트 조정이나 미세 조정 트래젝토리 생성을 위해 해당 질문을 사용하지 않습니다.
4.3 BAMTWOOGLE
- 과적합 방지를 위한 새로운 데이터셋: Bamboogle의 작은 크기와 검증 세트로서의 사용 때문에 과적합 위험이 있습니다. 이를 방지하기 위해 BamTwoogle 데이터셋을 도입합니다.
- BamTwoogle의 특징:
- Bamboogle에 비해 약간 더 도전적인 후속작으로, 인간 평가를 통해 발견한 Bamboogle의 단점을 해결합니다.
- 2단계 이상의 답변을 필요로 하는 질문으로 구성되어 있습니다.
- 질문은 Google 검색 결과 첫 페이지에 답이 나오지 않는 것으로 검증됩니다.
- 예상 답변은 모호하지 않고, 시간에 따라 변하지 않으며, 적절한 경우 여러 버전의 고유 명사를 고려합니다.
- Wikipedia를 사실의 출처로 선호합니다.
5. Experiments
5.1 파일럿
- 파일럿 데이터 생성: 단순화된 파일럿 데이터 500개 트래젝토리를 생성합니다. 이는 HotpotQA 및 Eli5 데이터셋에서 선택된 초기 질문을 사용합니다.
- 파일럿 미세 조정 혼합물: 최소 혼란도를 기반으로 하는 기본 행동을 사용하여 파일럿 미세 조정 혼합물을 구축합니다. 수동 검토를 통해 약 30%의 "나쁜" 예제를 필터링합니다.
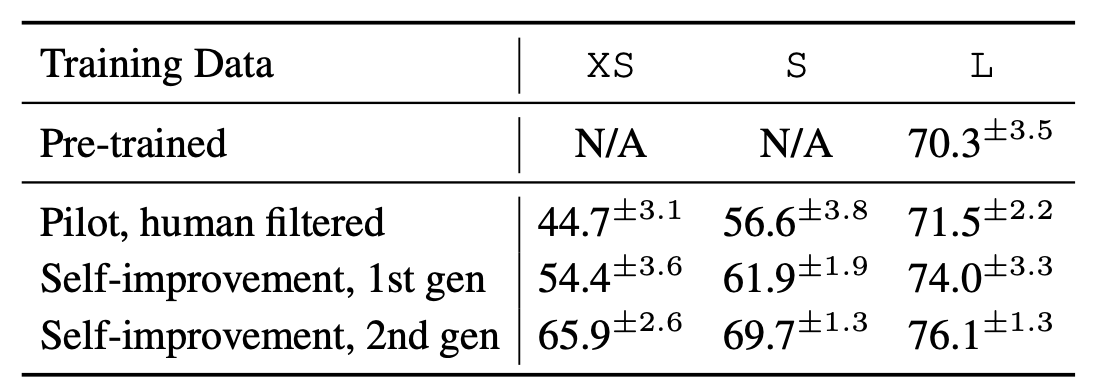
5.2 자기 개선 및 자체 증류
- 주요 결과: PaLM 2-L 모델로 시작하여 500개의 파일럿 트래젝토리와 독립적으로 2000개의 1세대 트래젝토리를 생성합니다. 이후 PaLM 2-L, PaLM 2-S, PaLM 2-XS 모델을 해당 혼합물로 미세 조정합니다.
- 2세대 트래젝토리 생성: 1세대 데이터로 미세 조정된 PaLM 2-L 모델을 사용하여 2세대 트래젝토리를 생성하고, 각각의 모델을 새로운 2세대 혼합물로 미세 조정합니다.
- 최종 검증: 각 2세대 모델에 대해 Bamboogle과 BamTwoogle 실행에 대한 인간 평가를 수행하고, 원래 PaLM 2-L 모델과 비교합니다.
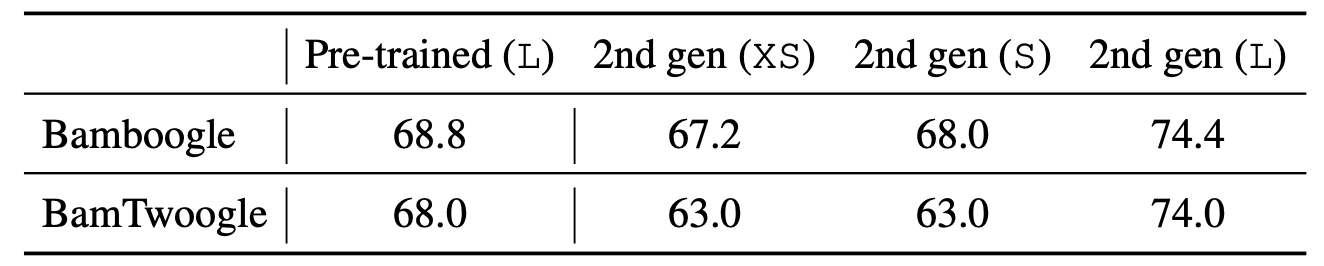
5.3 변형 실험
- 인간 필터링의 효과: 필터링된 데이터로 미세 조정할 때 성능이 약간 감소합니다. 이는 혼합물 크기의 감소와 "나쁜" 단계가 다른 미세 조정 예제에서 PAST ACTIONS 필드의 일부로 보존되기 때문일 수 있습니다.
- 질문 당 다중 트래젝토리 사용: 질문 당 1개 대신 2개의 트래젝토리를 사용하는 것이 유리합니다. 그러나 그 이상은 성능 향상에 큰 영향을 미치지 않습니다.
- 더 많은 데이터 vs 더 나은 데이터: 데이터의 질(예: 같은 데이터 크기로 1세대에서 2세대로 이동할 때 9%의 이득)이 양보다 중요합니다. 더 나은 데이터는 평가 트래젝토리의 분산도 감소시킵니다.
- 자기 비판의 효과: 에이전트의 다단계 설정을 통해 자기 비판 단계가 전체 성능에 미치는 영향을 측정할 수 있습니다. 자기 비판은 소규모이지만 측정 가능한 긍정적인 효과를 제공합니다(대부분의 모델에서 0.5-1.0% 정도).
6. Discussion
프로세스 감독
- 레이블 사용하지 않음: 트래젝토리 수집 중 훈련 데이터의 레이블을 신호로 사용하지 않습니다. 이는 프로세스 기반 접근법, 고온도 탐험, AI 피드백, 완성된 트래젝토리에 대한 상태별 미세 조정을 결합하여 가능합니다. 모델은 잘못된 최종 답변으로 이어지는 상태에서도 유용한 것을 학습할 수 있습니다.
자동 평가(Auto-Eval)
- 평가의 도전: 긴 형식의 최종 답변의 품질을 측정하고, 동일한 입력에 대한 다른 에이전트 트래젝토리 간의 불확실성을 고려해야 합니다. 이는 강력한 자동 평가의 필요성을 높이고, 여러 번의 에이전트 트래젝토리 실행과 PaLM 2-L 모델 사용으로 인한 계산 비용을 증가시킵니다.

자기 비판
- 자기 비판의 이점: 믿을 수 있는 자동 평가를 통해 에이전트의 다양한 하이퍼파라미터의 영향을 측정할 수 있습니다. 자기 비판 단계는 전체 성능에 소규모이지만 긍정적인 영향을 미칩니다. 이는 결과 기반 CoT 설정에서 자기 비판이 성능을 저하시킨다는 최근 관찰과 대조됩니다.
한계 및 미래 방향
- 연구의 한계: 수작업으로 구성된 프롬프트, 작은 평가 규모, 제한된 모델 세트, 단일 도구 사용 등 다양한 한계가 있습니다.
- 미래 연구 방향: 동일한 자기 개선 알고리즘이 다중 도구 설정에 적용되는지, 특히 미처리 도구 처리 능력이 이러한 방식으로 향상될 수 있는지 탐색할 필요가 있습니다. ReST 스타일의 반복적 훈련 하에 자기 비판이 향상되지 않는다면, 양자 모두에 대한 자기 개선을 가능하게 하는 데 필요한 변경 사항은 무엇일까요?
- 포화점 문제: 추가적인 자기 개선 반복이 여전히 중요한 이득을 가져올 수 있는지, 포화 상태는 어떤 모습인지, 더 작은 모델들이 초기 큰 모델의 성능에 의해 항상 제한될 것인지에 대한 질문이 남아 있습니다.
7. Related Work
긴 형식의 질문 답변과 웹 검색
- WebGPT의 영향: WebGPT에 이어서, 본 연구는 언어 에이전트가 웹 검색을 도구로 사용하여 검색된 내용에 대한 명시적 참조와 함께 최종 답변을 생성하는 긴 형식의 질문 답변 작업에 초점을 맞춥니다.
- 인간 참여 최소화: WebGPT는 많은 수의 인간 시연에서 모방 학습과 강화 학습에 중점을 두지만, 본 연구는 인간 참여를 최소화하려고 합니다. 훈련의 일부로 사용되는 유일한 레이블이 있는 시연은 에이전트의 추론 단계를 위한 프롬프트의 몇 가지 예시입니다.
언어 에이전트와 프롬프팅
- 수작업 프롬프트: 언어 에이전트를 수작업으로 설계된 몇 가지 프롬프트로 설정하는 것이 가장 일반적인 관행입니다. 하지만 DSP와 같은 예외도 있으며, 이는 최적화 목적으로 레이블이 있는 훈련 예제를 사용하여 프롬프트를 자동으로 조정합니다.
미세 조정과 자기 개선
- 미세 조정의 비교: 에이전트의 미세 조정은 드물게 수행되며, 본 연구의 미세 조정 설정은 FireAct와 가장 유사하지만, 인간 레이블을 훈련이나 데이터 필터링에 사용하지 않는다는 주요 차이가 있습니다. 대신, AI 피드백으로부터의 자기 개선을 통해 합성 데이터를 구축합니다.
- 자기 개선 관련 연구: STAR, ReST, ReSTEM, RAFT 등의 연구와 비교할 때, 본 연구는 답변의 정확성을 신호로 사용하지 않으며, 인간 선호도에 기반한 적절한 보상 모델이 없습니다. 또한, 이들 연구는 결과 기반 시스템을 대상으로 하지만 본 연구는 프로세스 기반 시스템에 초점을 맞춥니다.
8. Insight
개인적인 생각으로 이 논문에서의 키포인트는 'AI를 활용한 자동화'인 것 같습니다.
제가 잘 찾아보지 못한 것일 수도 있지만 최근에는 LLM이 어떤 결과물에 대해서 평가한 것을 사람의 것과 비교하는 경우가 많이 줄어들었다는 생각을 하고 있었습니다.
예를 들어 CoT 과정에서 발생하는 Rationale이 타당한지 혹은 그렇지 않은지를 판단할 때 GPT-4를 사용한다고 하면, 그 결과물이 사람의 것과 유사하다는 근거를 바탕으로 GPT-4를 사용할 수 있게 되는 것이죠.
그런데 최근에는 그러한 근거 없이 LLM을 활용한 것의 결과가 좋았다, 는 내용이 대부분이었던 것 같습니다.
이 논문에서는 많은 양은 아니지만 사람이 직접 데이터셋을 추가 생성하기도 하고(100개를 직접 제작한 것이 BamTwoogle이라고 밝혔습니다) 그에 대한 모델의 반환 결과를 사람이 직접 평가했다는 내용이 담겨 있습니다.
이는 분명히 scaling 가능하지 않은 방식이므로, 해당 과정을 모델의 작업으로 대체한 뒤 그 성과를 사람의 것과 비교하는 논리를 세운 것이 아주 타당하다고 느꼈습니다. (용인 가능한 - 엄밀히 말하면 엄청나게 효율적 - 수준의 trade-off가 발생)
출처 : https://arxiv.org/abs/2312.10003
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
Answering complex natural language questions often necessitates multi-step reasoning and integrating external information. Several systems have combined knowledge retrieval with a large language model (LLM) to answer such questions. These systems, however,
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Abstract
[Google Research, Google DeepMind]
- 주요 내용: 복잡한 자연어 질문에 답하기 위해 다단계 추론과 외부 정보 통합이 필요합니다. 이를 위해 대규모 언어 모델(LLM)과 지식 검색을 결합한 시스템이 개발되었으나, 이들 시스템은 다양한 실패 사례를 겪고 있습니다.
- 문제점: 이러한 시스템들은 외부 지식과의 상호작용이 비차별화(non-differentiable)되기 때문에 직접 end-to-end로 훈련시켜 실패를 수정할 수 없습니다.
- 해결 방안: 이를 해결하기 위해 외부 지식에 대해 추론하고 작용할 수 있는 ReAct 스타일의 LLM 에이전트를 정의합니다.
- ReST 방법론 적용: 이 에이전트는 이전 트래젝토리에 대해 반복적으로 훈련하는 ReST 방법론을 통해 더욱 세밀하게 다듬어집니다. 이 과정에는 AI 피드백을 활용한 성장 배치 강화 학습(growing-batch reinforcement learning)이 사용됩니다.
- 결과: 처음에는 프롬프트된 큰 모델에서 시작하여 알고리즘의 두 번의 반복 후, 훨씬 적은 매개변수를 가진 소형 모델로 세분화되어, 복합적인 질문-응답 벤치마크에서 비교 가능한 성능을 달성합니다.
- 중요성: 이 연구는 다단계 추론을 필요로 하는 언어 모델의 자기 개선(self-improvement)과 자체 정제(self-distillation)에 중요한 발전을 나타냅니다.
1. Introduction
- 간단한 자연어 작업과 복잡한 작업의 차이점: 기본 질문-응답이나 요약과 같은 간단한 자연어 작업에서는 결과의 좋고 나쁨을 쉽게 판단할 수 있지만, 더 복잡한 문제에서는 결과 기반 시스템이 종종 부족합니다. 최근에는 프로세스 감독 접근법이 더 유망한 대안으로 주목받고 있습니다.
- LLM을 활용한 프로세스 기반 워크플로 개발: 인간이 이해할 수 있는 작업 분해를 통해 LLM과 함께 프로세스 기반 워크플로를 정의하는 기술, 프레임워크, 라이브러리가 폭발적으로 증가하고 있습니다.
- LLM 에이전트의 개념: 외부 도구, API, 환경과의 상호작용을 포함하는 다단계 워크플로를 LLM 에이전트라고 부릅니다. 이는 목표를 달성하기 위한 일련의 행동을 수행할 수 있는 시스템입니다.
- ReAct 방법론: ReAct 방법론은 사고-행동-관찰 라운드를 여러 번 반복하며 사고의 흐름과 행동, 관찰을 번갈아가며 진행합니다.
- 에이전트의 실패 사례와 성능 개선: 이러한 에이전트의 실패 사례를 다루고 성능과 견고성을 향상시키는 방법에 대한 질문이 제기됩니다. 결과 기반 시스템의 경우, 해결책은 일반적으로 더 많은 인간 레이블 데이터를 수집하는 것입니다. 그러나 프로세스 기반 시스템의 경우, 이러한 데이터를 수집하는 것이 훨씬 더 도전적이고 비용이 많이 듭니다.
- ReST 알고리즘 적용: 우리는 이 문제를 해결하기 위해 자기 비판, AI 피드백, 합성 데이터 생성을 통해 에이전트의 품질을 향상시키기 위해 집중합니다. 특히, 최근 제안된 강화된 자기 훈련(ReST) 알고리즘을 에이전트 설정에 적용합니다.
- 성능 측정: 검색 에이전트의 전반적인 성능은 Bamboogle 데이터셋과 우리가 직접 구축한 BamTwoogle 데이터셋을 기반으로 다양한 구성 질문에 대한 답변 능력으로 측정됩니다.
- 기여점:
- 자기 비판 기능을 갖춘 ReAct 에이전트를 구축합니다.
- Bamboogle 및 BamTwoogle 데이터셋을 기반으로 한 에이전트의 프록시 평가 메트릭을 정의합니다.
- 에이전트의 성능이 ReST 스타일의 반복적 미세 조정을 통해 효과적으로 향상될 수 있음을 보여줍니다.
- 이 과정은 인간 레이블 훈련 데이터 없이 순전히 단계별 AI 피드백을 통해 이루어집니다.
- 반복적 과정에서 생성된 합성 데이터를 사용하여 미리 훈련된 교사 에이전트와 비교할 수 있는 성능을 가진 훨씬 작은 모델로 에이전트를 정제할 수 있음을 보여줍니다.
2. Background: Search Agent
- 검색 에이전트 소개: '검색 에이전트'는 ReAct 방법론의 일종으로, Reflexion을 통합하여 사용합니다. 이는 다양한 지식 탐색형 개방형 질문에 대해 긴 형식의 명시적으로 귀속 가능한 답변을 생성하기 위해 웹 검색을 도구로 사용합니다.
- 에이전트의 작업 흐름:
- 질문 수신 및 검색 루프 실행:
- 에이전트는 추가 정보가 필요한지 결정합니다.
- 필요한 경우 검색 도구를 호출하여 받은 스니펫을 요약한 후 다시 결정 단계로 돌아갑니다.
- 필요하지 않은 경우 검색 루프를 종료합니다.
- 답변 초안 생성: 검색 루프를 통해 수집한 정보를 바탕으로 첫 번째 답변 시도(초안)을 생성합니다.
- 최종 답변 생성을 위한 자체 수정: 최종 답변을 생성하기 전에 두 번의 추가적인 자체 수정 호출을 수행합니다.
- 질문 수신 및 검색 루프 실행:
3. Methods
3.1 프롬프팅
- 검색 에이전트 프롬프트 정의: 검색 에이전트의 흐름을 위한 프롬프트를 수작업으로 정의합니다. 각 단계는 파이썬 코드 형식으로 구성됩니다.
- 코드 사용의 이유: 출력을 다른 시스템과 통합하기 쉽게 구조화된 입력과 출력이 필요합니다. 코드는 구조화된 측면과 자연 언어 측면을 결합합니다.
- 모델 선택: PaLM 2-L 모델이 이러한 작업에 가장 적합하며, 이 모델을 사용하여 프롬프트에서 추론 트래젝토리를 생성합니다.
3.2 구현 세부 사항
- 모델 및 도구 사용: 다양한 크기의 PaLM 2 모델을 사용합니다. Google Q&A API를 검색 도구로 사용하여 상위 k개 스니펫을 반환합니다.
- 샘플링과 선택: 각 단계에 대해 여러 샘플을 생성하고 가장 낮은 혼란도를 가진 샘플을 선택합니다.
3.3 입력 데이터
- 데이터셋 사용: HotpotQA, Eli5, Eli5-askH, Eli5-askS 등 네 가지 데이터셋에서 초기 질문을 제공합니다. 이들은 다양하고 도전적인 2000개의 질문을 포함합니다.
3.4 미세 조정
- 미세 조정 절차: 완성된 검색 에이전트 트래젝토리를 추론 단계로 분할하고 이 단계들로 미세 조정 혼합물을 구성합니다.
3.5 순위 ”보상” 모델
- 샘플 선택 개선: 여러 샘플 중 최상의 샘플을 선택하기 위해 더 정교한 방법을 사용합니다. PaLM 2-L 모델로 샘플을 순위 매깁니다.
3.6 반복적 자기 개선
- 자기 개선 알고리즘:
- PaLM 2-L 모델로부터 추론 트래젝토리를 수집합니다.
- 이 트래젝토리를 미세 조정 혼합물로 변환하고, RM을 사용하여 재순위를 매깁니다.
- 새 모델을 이 혼합물로 미세 조정하고, 성능이 향상되었는지 확인한 후, 과정을 반복합니다.
- 자체 증류 알고리즘: 이 자기 개선 과정에서 생성된 미세 조정 데이터를 사용하여 더 작은 모델을 훈련시키면 자체 증류 알고리즘이 됩니다.
4. Evaluation
4.1 BAMBOOGLE
- Bamboogle 데이터셋 사용: Bamboogle 데이터셋은 검색 에이전트의 주요 평가 도구입니다. 이는 Google 검색으로는 답을 찾을 수 없지만 Wikipedia에서 필요한 증거를 찾을 수 있는 2단계 질문으로 구성됩니다.
- 평가 방식: 검색 에이전트가 생성하는 개방형 답변의 특성상 정확한 일치를 메트릭으로 사용하기 어렵습니다. 따라서 수동 판단 또는 PaLM 2-L “base” 모델을 사용한 자동 평가(auto-eval)를 실행합니다.
4.2 자동 평가(Auto-Eval)
- 시간 및 비용 효율성: 인간 평가보다 시간과 비용이 덜 드는 자동 평가를 도입합니다. 자동 평가는 인간 평가와 높은 상관관계를 보입니다.
- 다양한 질문에 대한 사용: 최적의 샘플링 온도 결정, 모델 크기별 체크포인트 선택, 자기 개선의 다음 단계 진행 여부, 여러 트래젝토리 사용의 성능 영향 등에 대한 질문에 답하기 위해 사용됩니다.
- 훈련 세트로 사용 안 함: Bamboogle은 훈련 세트로 사용되지 않으며, 프롬프트 조정이나 미세 조정 트래젝토리 생성을 위해 해당 질문을 사용하지 않습니다.
4.3 BAMTWOOGLE
- 과적합 방지를 위한 새로운 데이터셋: Bamboogle의 작은 크기와 검증 세트로서의 사용 때문에 과적합 위험이 있습니다. 이를 방지하기 위해 BamTwoogle 데이터셋을 도입합니다.
- BamTwoogle의 특징:
- Bamboogle에 비해 약간 더 도전적인 후속작으로, 인간 평가를 통해 발견한 Bamboogle의 단점을 해결합니다.
- 2단계 이상의 답변을 필요로 하는 질문으로 구성되어 있습니다.
- 질문은 Google 검색 결과 첫 페이지에 답이 나오지 않는 것으로 검증됩니다.
- 예상 답변은 모호하지 않고, 시간에 따라 변하지 않으며, 적절한 경우 여러 버전의 고유 명사를 고려합니다.
- Wikipedia를 사실의 출처로 선호합니다.
5. Experiments
5.1 파일럿
- 파일럿 데이터 생성: 단순화된 파일럿 데이터 500개 트래젝토리를 생성합니다. 이는 HotpotQA 및 Eli5 데이터셋에서 선택된 초기 질문을 사용합니다.
- 파일럿 미세 조정 혼합물: 최소 혼란도를 기반으로 하는 기본 행동을 사용하여 파일럿 미세 조정 혼합물을 구축합니다. 수동 검토를 통해 약 30%의 "나쁜" 예제를 필터링합니다.
5.2 자기 개선 및 자체 증류
- 주요 결과: PaLM 2-L 모델로 시작하여 500개의 파일럿 트래젝토리와 독립적으로 2000개의 1세대 트래젝토리를 생성합니다. 이후 PaLM 2-L, PaLM 2-S, PaLM 2-XS 모델을 해당 혼합물로 미세 조정합니다.
- 2세대 트래젝토리 생성: 1세대 데이터로 미세 조정된 PaLM 2-L 모델을 사용하여 2세대 트래젝토리를 생성하고, 각각의 모델을 새로운 2세대 혼합물로 미세 조정합니다.
- 최종 검증: 각 2세대 모델에 대해 Bamboogle과 BamTwoogle 실행에 대한 인간 평가를 수행하고, 원래 PaLM 2-L 모델과 비교합니다.
5.3 변형 실험
- 인간 필터링의 효과: 필터링된 데이터로 미세 조정할 때 성능이 약간 감소합니다. 이는 혼합물 크기의 감소와 "나쁜" 단계가 다른 미세 조정 예제에서 PAST ACTIONS 필드의 일부로 보존되기 때문일 수 있습니다.
- 질문 당 다중 트래젝토리 사용: 질문 당 1개 대신 2개의 트래젝토리를 사용하는 것이 유리합니다. 그러나 그 이상은 성능 향상에 큰 영향을 미치지 않습니다.
- 더 많은 데이터 vs 더 나은 데이터: 데이터의 질(예: 같은 데이터 크기로 1세대에서 2세대로 이동할 때 9%의 이득)이 양보다 중요합니다. 더 나은 데이터는 평가 트래젝토리의 분산도 감소시킵니다.
- 자기 비판의 효과: 에이전트의 다단계 설정을 통해 자기 비판 단계가 전체 성능에 미치는 영향을 측정할 수 있습니다. 자기 비판은 소규모이지만 측정 가능한 긍정적인 효과를 제공합니다(대부분의 모델에서 0.5-1.0% 정도).
6. Discussion
프로세스 감독
- 레이블 사용하지 않음: 트래젝토리 수집 중 훈련 데이터의 레이블을 신호로 사용하지 않습니다. 이는 프로세스 기반 접근법, 고온도 탐험, AI 피드백, 완성된 트래젝토리에 대한 상태별 미세 조정을 결합하여 가능합니다. 모델은 잘못된 최종 답변으로 이어지는 상태에서도 유용한 것을 학습할 수 있습니다.
자동 평가(Auto-Eval)
- 평가의 도전: 긴 형식의 최종 답변의 품질을 측정하고, 동일한 입력에 대한 다른 에이전트 트래젝토리 간의 불확실성을 고려해야 합니다. 이는 강력한 자동 평가의 필요성을 높이고, 여러 번의 에이전트 트래젝토리 실행과 PaLM 2-L 모델 사용으로 인한 계산 비용을 증가시킵니다.
자기 비판
- 자기 비판의 이점: 믿을 수 있는 자동 평가를 통해 에이전트의 다양한 하이퍼파라미터의 영향을 측정할 수 있습니다. 자기 비판 단계는 전체 성능에 소규모이지만 긍정적인 영향을 미칩니다. 이는 결과 기반 CoT 설정에서 자기 비판이 성능을 저하시킨다는 최근 관찰과 대조됩니다.
한계 및 미래 방향
- 연구의 한계: 수작업으로 구성된 프롬프트, 작은 평가 규모, 제한된 모델 세트, 단일 도구 사용 등 다양한 한계가 있습니다.
- 미래 연구 방향: 동일한 자기 개선 알고리즘이 다중 도구 설정에 적용되는지, 특히 미처리 도구 처리 능력이 이러한 방식으로 향상될 수 있는지 탐색할 필요가 있습니다. ReST 스타일의 반복적 훈련 하에 자기 비판이 향상되지 않는다면, 양자 모두에 대한 자기 개선을 가능하게 하는 데 필요한 변경 사항은 무엇일까요?
- 포화점 문제: 추가적인 자기 개선 반복이 여전히 중요한 이득을 가져올 수 있는지, 포화 상태는 어떤 모습인지, 더 작은 모델들이 초기 큰 모델의 성능에 의해 항상 제한될 것인지에 대한 질문이 남아 있습니다.
7. Related Work
긴 형식의 질문 답변과 웹 검색
- WebGPT의 영향: WebGPT에 이어서, 본 연구는 언어 에이전트가 웹 검색을 도구로 사용하여 검색된 내용에 대한 명시적 참조와 함께 최종 답변을 생성하는 긴 형식의 질문 답변 작업에 초점을 맞춥니다.
- 인간 참여 최소화: WebGPT는 많은 수의 인간 시연에서 모방 학습과 강화 학습에 중점을 두지만, 본 연구는 인간 참여를 최소화하려고 합니다. 훈련의 일부로 사용되는 유일한 레이블이 있는 시연은 에이전트의 추론 단계를 위한 프롬프트의 몇 가지 예시입니다.
언어 에이전트와 프롬프팅
- 수작업 프롬프트: 언어 에이전트를 수작업으로 설계된 몇 가지 프롬프트로 설정하는 것이 가장 일반적인 관행입니다. 하지만 DSP와 같은 예외도 있으며, 이는 최적화 목적으로 레이블이 있는 훈련 예제를 사용하여 프롬프트를 자동으로 조정합니다.
미세 조정과 자기 개선
- 미세 조정의 비교: 에이전트의 미세 조정은 드물게 수행되며, 본 연구의 미세 조정 설정은 FireAct와 가장 유사하지만, 인간 레이블을 훈련이나 데이터 필터링에 사용하지 않는다는 주요 차이가 있습니다. 대신, AI 피드백으로부터의 자기 개선을 통해 합성 데이터를 구축합니다.
- 자기 개선 관련 연구: STAR, ReST, ReSTEM, RAFT 등의 연구와 비교할 때, 본 연구는 답변의 정확성을 신호로 사용하지 않으며, 인간 선호도에 기반한 적절한 보상 모델이 없습니다. 또한, 이들 연구는 결과 기반 시스템을 대상으로 하지만 본 연구는 프로세스 기반 시스템에 초점을 맞춥니다.
8. Insight
개인적인 생각으로 이 논문에서의 키포인트는 'AI를 활용한 자동화'인 것 같습니다.
제가 잘 찾아보지 못한 것일 수도 있지만 최근에는 LLM이 어떤 결과물에 대해서 평가한 것을 사람의 것과 비교하는 경우가 많이 줄어들었다는 생각을 하고 있었습니다.
예를 들어 CoT 과정에서 발생하는 Rationale이 타당한지 혹은 그렇지 않은지를 판단할 때 GPT-4를 사용한다고 하면, 그 결과물이 사람의 것과 유사하다는 근거를 바탕으로 GPT-4를 사용할 수 있게 되는 것이죠.
그런데 최근에는 그러한 근거 없이 LLM을 활용한 것의 결과가 좋았다, 는 내용이 대부분이었던 것 같습니다.
이 논문에서는 많은 양은 아니지만 사람이 직접 데이터셋을 추가 생성하기도 하고(100개를 직접 제작한 것이 BamTwoogle이라고 밝혔습니다) 그에 대한 모델의 반환 결과를 사람이 직접 평가했다는 내용이 담겨 있습니다.
이는 분명히 scaling 가능하지 않은 방식이므로, 해당 과정을 모델의 작업으로 대체한 뒤 그 성과를 사람의 것과 비교하는 논리를 세운 것이 아주 타당하다고 느꼈습니다. (용인 가능한 - 엄밀히 말하면 엄청나게 효율적 - 수준의 trade-off가 발생)
출처 : https://arxiv.org/abs/2312.10003
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
Answering complex natural language questions often necessitates multi-step reasoning and integrating external information. Several systems have combined knowledge retrieval with a large language model (LLM) to answer such questions. These systems, however,
arxiv.org