
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Abstract
- 대규모 언어 모델(Large Language Models, LLMs)은 양적 추론부터 자연어 이해에 이르기까지 복잡한 작업을 수행하는 능력을 보여주었으나, 때때로 사실이 아닌 설득력 있는 진술(환각)을 만들어내는 문제가 있음.
- 현재 대규모 모델의 과학적 발견에서의 사용을 제한하는 이러한 문제를 해결하기 위해, 사전 훈련된 LLM과 체계적인 평가자를 결합한 진화적 절차인 'FunSearch'를 소개함.
- FunSearch는 중요한 문제에서 최고의 결과를 뛰어넘는 효과를 입증하며, 대규모 LLM 기반 접근법의 한계를 확장함.
- FunSearch를 극단적 조합론의 중심 문제인 'cap set problem'에 적용해, 기존의 최고 결과를 넘어서는 새로운 구조를 발견함. 이는 LLM을 사용한 기존의 개방형 문제에 대한 첫 번째 발견임.
- 또한, FunSearch를 알고리즘 문제인 'online bin packing'에 적용하여, 널리 사용되는 기준을 개선하는 새로운 휴리스틱을 발견함.
- 대부분의 컴퓨터 검색 접근법과 달리, FunSearch는 문제의 해결책이 아닌 해결 방법을 설명하는 프로그램을 찾음.
- 발견된 프로그램은 원시 해결책보다 해석 가능성이 높아, 분야 전문가와 FunSearch 간의 피드백 루프와 실제 응용 프로그램에서의 배치를 가능하게 함.
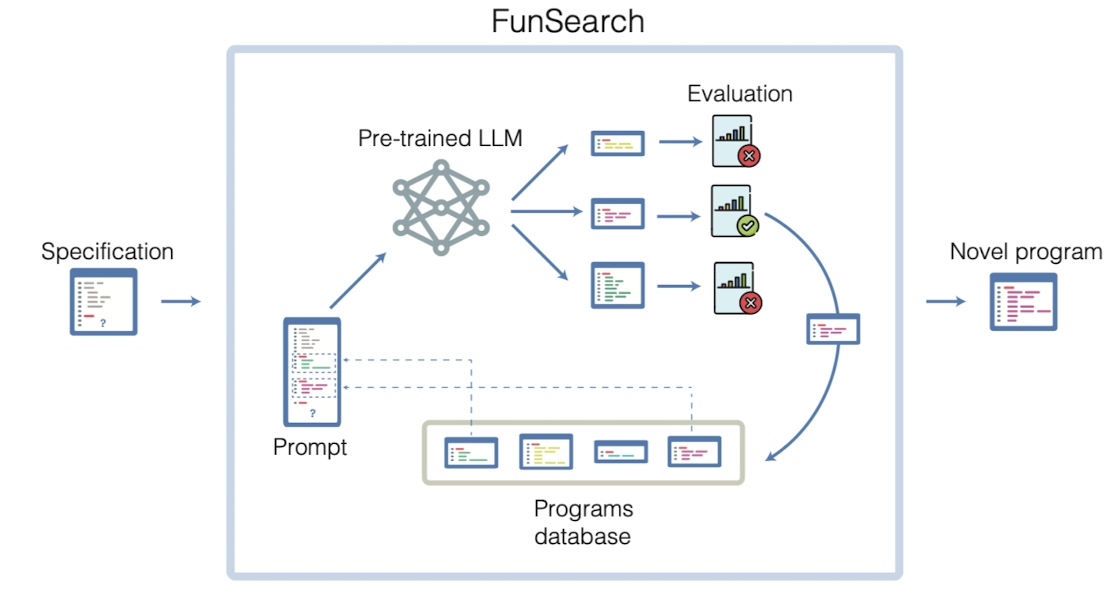
1. FunSearch
- FunSearch 개요
- 구성요소: 문제의 평가 함수(evaluate function)를 입력으로 받고, 초기 프로그램을 진화시키는 시스템. 성능은 초기 프로그램을 문제의 구조를 반영한 '스켈레톤' 형태로 작성했을 때 크게 향상됨.
- 스켈레톤의 중요성: FunSearch는 스켈레톤의 중요 부분만을 진화시키며, 이는 대체로 가장 해결하기 어려운 부분임. 고정된 스켈레톤은 프로그램 발견의 범위를 제한하지만, 중요한 부분에 대한 집중으로 전체 결과가 향상됨.
- 사전 훈련된 LLM (Pre-trained LLM)
- 역할: 프롬프트에 제시된 함수를 개선하고 평가를 위해 제출하는 창의적 핵심.
- 사용 모델: 'Codey'라는 PaLM2 모델에 기반하고 있으며, 코드에 대한 대규모 코퍼스로 파인튜닝됨.
- 샘플링 및 추론 속도: 샘플링 품질과 LLM의 추론 속도 사이의 트레이드오프가 성능을 결정함.
- 평가 (Evaluation)
- 방식: LLM에 의해 생성된 프로그램은 일련의 입력에 대해 평가되고 점수화됨.
- 점수화 방법: 다양한 입력에 대한 점수를 종합하여 프로그램의 전체 점수를 산출.
- 프로그램 데이터베이스 (Programs database)
- 기능: 올바른 프로그램의 집단을 유지하고, 프롬프트 생성을 위해 샘플링함.
- 다양성 유지: 지역 최적해에 빠지지 않기 위해 다양한 프로그램을 유지하는 것이 중요함.
- 프롬프트 (Prompt)
- 생성 방법: 데이터베이스에서 최고의 프로그램을 샘플링하여 새로운 프롬프트 생성.
- 구성: 여러 프로그램을 조합하여 LLM이 패턴을 파악하고 일반화할 수 있도록 함.
- 분산 접근 방식 (Distributed approach)
- 구성: 프로그램 데이터베이스, 샘플러, 평가자로 구성된 비동기 통신 시스템.
- 장점: 다양한 작업의 병렬 처리, 확장성, 비용 및 에너지 사용 절감.
2. Results
2.1 극단적 조합론 (Extremal Combinatorics)
- Cap Sets
- 문제 설명: Z^n3 내에서 세 벡터의 합이 0이 되지 않는 최대 크기의 벡터 집합(캡 세트) 찾기.
- FunSearch 활용: 차원 n에 대한 캡 세트의 최대 크기 발견. n = 8 차원에서 기존보다 큰 캡 세트를 발견하여 FunSearch의 효과와 확장성 입증.
- Admissible Sets
- 문제 설명: 더 큰 차원에서 캡 세트를 결합하는 방법을 설명하는 'admissible sets' 생성.
- 결과: 새로운 하한값 발견으로 캡 세트 용량의 하한선을 기존보다 개선.
2.2 빈 포장 (Bin Packing)
- 문제 설명: 다양한 크기의 아이템을 가장 적은 수의 고정 크기 빈에 포장하는 문제.
- FunSearch 활용: 기존의 첫 번째 적합(First Fit)과 최적 적합(Best Fit) 휴리스틱보다 효과적인 새로운 휴리스틱 발견.
- 성능 평가: OR-Library 빈 포장 벤치마크 및 실제 세계 스케줄링 문제를 모델링하는 Weibull 분포에서 FunSearch의 휴리스틱이 기존 방법보다 우수한 성능을 보임.
- 전략 분석: FunSearch에 의해 발견된 휴리스틱은 효율적인 빈 사용을 위해 아이템 배치에 새로운 접근법을 사용.
종합
- FunSearch의 범용성: 이론적, 수학적 결과뿐만 아니라 실제 문제 해결에도 FunSearch가 유용함을 보여줌.
- 실제 적용 가능성: FunSearch는 다양한 산업 분야에서 적용될 수 있는 잠재력을 가짐.

3. Discussion
FunSearch의 효과성과 작동 원리
- LLM 활용: FunSearch 내의 LLM은 문제에 대한 맥락적 이해보다는 다양하고 문법적으로 올바른 프로그램을 제안하는 역할을 함.
- 알고리즘 스켈레톤과 진화적 접근: 알고리즘의 핵심 부분에 대한 LLM의 제안을 통해 개방형 문제에 대한 새로운 지식 발견.
- 프로그램 공간에서의 작업: 숫자 리스트가 아닌, 구조를 생성하는 프로그램을 찾음으로써 구조화된 문제에서 더 큰 인스턴스로 확장 가능.
Kolmogorov Complexity와 해석 가능성
- Kolmogorov Complexity 접근: FunSearch는 주어진 객체를 출력하는 가장 짧은 프로그램의 길이를 찾는 것과 유사함. 전통적인 탐색 방식과는 다른 유도 편향을 가짐.
- 해석 가능한 프로그램: FunSearch의 결과물은 숫자 리스트보다 읽고 이해하기 쉬움. 예를 들어, admissible set 문제에서 새로운 대칭성 발견 가능.
적용 범위와 향후 개발
- 적용 가능한 문제 유형: 효율적인 평가자, 풍부한 점수 피드백, 진화할 수 있는 부분을 제공할 수 있는 스켈레톤이 있는 문제에 가장 적합.
- 향후 개발 전망: FunSearch는 간단하고 확장 가능하며, LLM의 발전으로 더 우수한 샘플을 효율적으로 생성할 수 있을 것으로 기대됨.
- 자동 맞춤형 알고리즘의 미래: 자동화된 맞춤형 알고리즘은 곧 일반적인 실용화 단계에 도달할 것으로 전망됨.
4. Insight
최근 본 논문들을 떠올려보면, 생각보다 흔하면서도 정교하게 컨트롤하는 구도가 '생성자 vs 평가자(판별자)'인 것 같습니다.
LM을 평가자로 활용하는 것이 우수한 결과물을 만들어 내는 데 직접적인 영향을 줄 수 있음이 잘 알려지면서 이를 다양한 분야에 접목시키고 있다는 생각이 듭니다.
인공지능 모델을 활용했을 때의 장점이라면 많은 반복 작업을 최소화 할 수 있다는 것이겠죠.
반대로 단점은 이러한 반복 작업이 필수라는 것일테지만 결과물만 놓고 본다면 충분히 상쇄 가능한 것으로 보입니다.
본 논문에서는 반복 작업을 통해 '새로운' 결과물을 만들어 내고자 했고, 어느 정도 유효했다는 생각이 듭니다.
어찌보면 강화 학습과 유사한 로직으로 결과물이 생성된 것 같긴 하지만..
앞으로 다양한 분야에 이와 같은 방식을 적용하여 재밌는 결과를 얻을 수 있을 거라는 생각이 듭니다.
한편으로는 최신 정보가 계속해서 업데이트되는 것과 관련된 continual learning 등에 접목할 아이디어는 없을지 궁금해지네요.
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Abstract
- 대규모 언어 모델(Large Language Models, LLMs)은 양적 추론부터 자연어 이해에 이르기까지 복잡한 작업을 수행하는 능력을 보여주었으나, 때때로 사실이 아닌 설득력 있는 진술(환각)을 만들어내는 문제가 있음.
- 현재 대규모 모델의 과학적 발견에서의 사용을 제한하는 이러한 문제를 해결하기 위해, 사전 훈련된 LLM과 체계적인 평가자를 결합한 진화적 절차인 'FunSearch'를 소개함.
- FunSearch는 중요한 문제에서 최고의 결과를 뛰어넘는 효과를 입증하며, 대규모 LLM 기반 접근법의 한계를 확장함.
- FunSearch를 극단적 조합론의 중심 문제인 'cap set problem'에 적용해, 기존의 최고 결과를 넘어서는 새로운 구조를 발견함. 이는 LLM을 사용한 기존의 개방형 문제에 대한 첫 번째 발견임.
- 또한, FunSearch를 알고리즘 문제인 'online bin packing'에 적용하여, 널리 사용되는 기준을 개선하는 새로운 휴리스틱을 발견함.
- 대부분의 컴퓨터 검색 접근법과 달리, FunSearch는 문제의 해결책이 아닌 해결 방법을 설명하는 프로그램을 찾음.
- 발견된 프로그램은 원시 해결책보다 해석 가능성이 높아, 분야 전문가와 FunSearch 간의 피드백 루프와 실제 응용 프로그램에서의 배치를 가능하게 함.
1. FunSearch
- FunSearch 개요
- 구성요소: 문제의 평가 함수(evaluate function)를 입력으로 받고, 초기 프로그램을 진화시키는 시스템. 성능은 초기 프로그램을 문제의 구조를 반영한 '스켈레톤' 형태로 작성했을 때 크게 향상됨.
- 스켈레톤의 중요성: FunSearch는 스켈레톤의 중요 부분만을 진화시키며, 이는 대체로 가장 해결하기 어려운 부분임. 고정된 스켈레톤은 프로그램 발견의 범위를 제한하지만, 중요한 부분에 대한 집중으로 전체 결과가 향상됨.
- 사전 훈련된 LLM (Pre-trained LLM)
- 역할: 프롬프트에 제시된 함수를 개선하고 평가를 위해 제출하는 창의적 핵심.
- 사용 모델: 'Codey'라는 PaLM2 모델에 기반하고 있으며, 코드에 대한 대규모 코퍼스로 파인튜닝됨.
- 샘플링 및 추론 속도: 샘플링 품질과 LLM의 추론 속도 사이의 트레이드오프가 성능을 결정함.
- 평가 (Evaluation)
- 방식: LLM에 의해 생성된 프로그램은 일련의 입력에 대해 평가되고 점수화됨.
- 점수화 방법: 다양한 입력에 대한 점수를 종합하여 프로그램의 전체 점수를 산출.
- 프로그램 데이터베이스 (Programs database)
- 기능: 올바른 프로그램의 집단을 유지하고, 프롬프트 생성을 위해 샘플링함.
- 다양성 유지: 지역 최적해에 빠지지 않기 위해 다양한 프로그램을 유지하는 것이 중요함.
- 프롬프트 (Prompt)
- 생성 방법: 데이터베이스에서 최고의 프로그램을 샘플링하여 새로운 프롬프트 생성.
- 구성: 여러 프로그램을 조합하여 LLM이 패턴을 파악하고 일반화할 수 있도록 함.
- 분산 접근 방식 (Distributed approach)
- 구성: 프로그램 데이터베이스, 샘플러, 평가자로 구성된 비동기 통신 시스템.
- 장점: 다양한 작업의 병렬 처리, 확장성, 비용 및 에너지 사용 절감.
2. Results
2.1 극단적 조합론 (Extremal Combinatorics)
- Cap Sets
- 문제 설명: Z^n3 내에서 세 벡터의 합이 0이 되지 않는 최대 크기의 벡터 집합(캡 세트) 찾기.
- FunSearch 활용: 차원 n에 대한 캡 세트의 최대 크기 발견. n = 8 차원에서 기존보다 큰 캡 세트를 발견하여 FunSearch의 효과와 확장성 입증.
- Admissible Sets
- 문제 설명: 더 큰 차원에서 캡 세트를 결합하는 방법을 설명하는 'admissible sets' 생성.
- 결과: 새로운 하한값 발견으로 캡 세트 용량의 하한선을 기존보다 개선.
2.2 빈 포장 (Bin Packing)
- 문제 설명: 다양한 크기의 아이템을 가장 적은 수의 고정 크기 빈에 포장하는 문제.
- FunSearch 활용: 기존의 첫 번째 적합(First Fit)과 최적 적합(Best Fit) 휴리스틱보다 효과적인 새로운 휴리스틱 발견.
- 성능 평가: OR-Library 빈 포장 벤치마크 및 실제 세계 스케줄링 문제를 모델링하는 Weibull 분포에서 FunSearch의 휴리스틱이 기존 방법보다 우수한 성능을 보임.
- 전략 분석: FunSearch에 의해 발견된 휴리스틱은 효율적인 빈 사용을 위해 아이템 배치에 새로운 접근법을 사용.
종합
- FunSearch의 범용성: 이론적, 수학적 결과뿐만 아니라 실제 문제 해결에도 FunSearch가 유용함을 보여줌.
- 실제 적용 가능성: FunSearch는 다양한 산업 분야에서 적용될 수 있는 잠재력을 가짐.
3. Discussion
FunSearch의 효과성과 작동 원리
- LLM 활용: FunSearch 내의 LLM은 문제에 대한 맥락적 이해보다는 다양하고 문법적으로 올바른 프로그램을 제안하는 역할을 함.
- 알고리즘 스켈레톤과 진화적 접근: 알고리즘의 핵심 부분에 대한 LLM의 제안을 통해 개방형 문제에 대한 새로운 지식 발견.
- 프로그램 공간에서의 작업: 숫자 리스트가 아닌, 구조를 생성하는 프로그램을 찾음으로써 구조화된 문제에서 더 큰 인스턴스로 확장 가능.
Kolmogorov Complexity와 해석 가능성
- Kolmogorov Complexity 접근: FunSearch는 주어진 객체를 출력하는 가장 짧은 프로그램의 길이를 찾는 것과 유사함. 전통적인 탐색 방식과는 다른 유도 편향을 가짐.
- 해석 가능한 프로그램: FunSearch의 결과물은 숫자 리스트보다 읽고 이해하기 쉬움. 예를 들어, admissible set 문제에서 새로운 대칭성 발견 가능.
적용 범위와 향후 개발
- 적용 가능한 문제 유형: 효율적인 평가자, 풍부한 점수 피드백, 진화할 수 있는 부분을 제공할 수 있는 스켈레톤이 있는 문제에 가장 적합.
- 향후 개발 전망: FunSearch는 간단하고 확장 가능하며, LLM의 발전으로 더 우수한 샘플을 효율적으로 생성할 수 있을 것으로 기대됨.
- 자동 맞춤형 알고리즘의 미래: 자동화된 맞춤형 알고리즘은 곧 일반적인 실용화 단계에 도달할 것으로 전망됨.
4. Insight
최근 본 논문들을 떠올려보면, 생각보다 흔하면서도 정교하게 컨트롤하는 구도가 '생성자 vs 평가자(판별자)'인 것 같습니다.
LM을 평가자로 활용하는 것이 우수한 결과물을 만들어 내는 데 직접적인 영향을 줄 수 있음이 잘 알려지면서 이를 다양한 분야에 접목시키고 있다는 생각이 듭니다.
인공지능 모델을 활용했을 때의 장점이라면 많은 반복 작업을 최소화 할 수 있다는 것이겠죠.
반대로 단점은 이러한 반복 작업이 필수라는 것일테지만 결과물만 놓고 본다면 충분히 상쇄 가능한 것으로 보입니다.
본 논문에서는 반복 작업을 통해 '새로운' 결과물을 만들어 내고자 했고, 어느 정도 유효했다는 생각이 듭니다.
어찌보면 강화 학습과 유사한 로직으로 결과물이 생성된 것 같긴 하지만..
앞으로 다양한 분야에 이와 같은 방식을 적용하여 재밌는 결과를 얻을 수 있을 거라는 생각이 듭니다.
한편으로는 최신 정보가 계속해서 업데이트되는 것과 관련된 continual learning 등에 접목할 아이디어는 없을지 궁금해지네요.