
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Research, Brain Team]
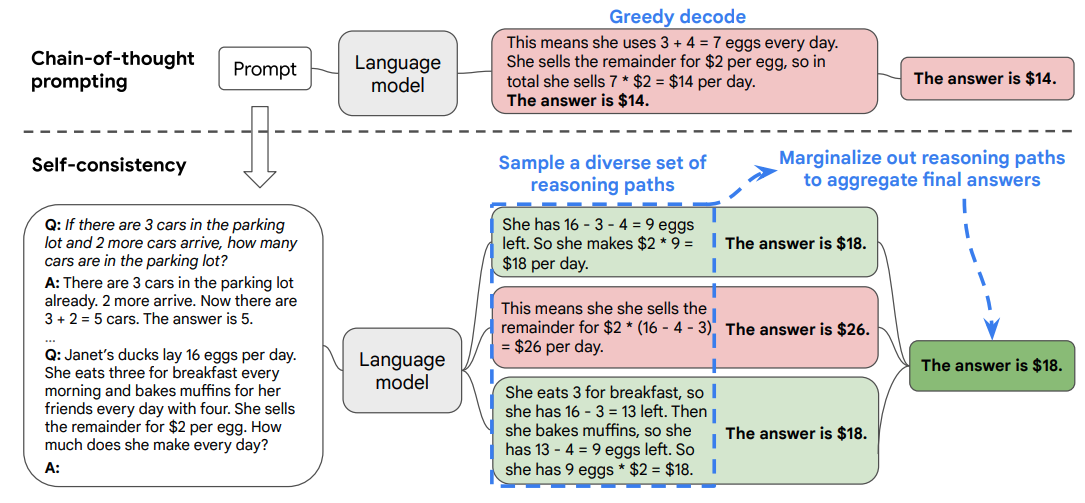
- 본 논문에서는 chain-of-thought 프롬프팅에 사용되던 단순한 greedy decoding 대신 새로운 디코딩 전략인 'self-consistency'를 제안합니다.
- 이 전략은 greedy 방식 대신 다양한 추론 경로를 샘플링한 후 가장 일관성 있는 답변을 선택하는 방식입니다. 이는 복잡한 추론 문제가 일반적으로 정확한 답을 이끌어내는 다양한 사고 방식을 허용한다는 직관을 활용합니다.
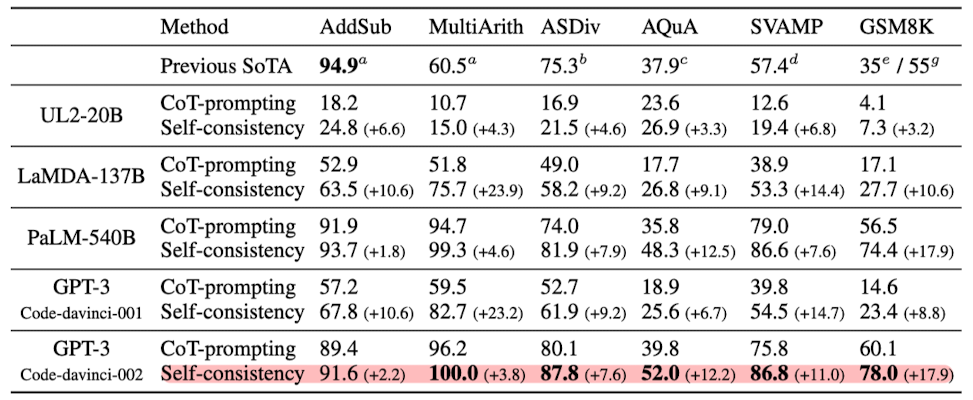
- 대규모 실증 평가를 통해, self-consistency가 chain-of-thought 프롬프팅의 성능을 GSM8K(+17.9%), SVAMP(+11.0%), AQuA(+12.2%), StrategyQA(+6.4%), ARC-challenge(+3.9%) 등의 인기 있는 산술 및 상식 추론 벤치마크에서 크게 향상시킨다는 것을 입증했습니다.
1. Introduction
- 도입부 요약
- 언어 모델은 다양한 NLP 작업에서 뛰어난 성공을 거두었지만, 추론 능력의 한계는 모델 크기 증가만으로 극복하기 어렵다는 인식이 있습니다 (Rae et al., 2021; BIG-bench collaboration, 2021).
- Wei et al. (2022)은 이러한 단점을 해결하기 위해 사람의 추론 과정을 모방한 짧은 문장 시리즈를 생성하는 'chain-of-thought 프롬프팅'을 제안했습니다. 이 방법은 다단계 추론 작업에서 모델 성능을 크게 향상시킵니다.
- Self-Consistency의 도입
- 본 논문에서는 chain-of-thought 프롬프팅에 사용된 greedy 디코딩 전략을 대체할 새로운 디코딩 전략인 'self-consistency'를 소개합니다.
- Self-consistency는 복잡한 추론 작업이 여러 가지 추론 경로를 허용하며 이는 정확한 답으로 이어진다는 직관을 활용합니다.
- 이 전략은 'sample-and-marginalize' 디코딩 절차를 제안합니다: 언어 모델로부터 다양한 추론 경로를 샘플링하고, 이를 통해 가장 일관된 답을 도출합니다.
- Self-Consistency의 장점
- 추가 검증기를 훈련하거나 인간의 주석을 바탕으로 재순위를 매기는 기존 방법보다 훨씬 단순합니다.
- 완전한 비감독 학습 방식으로, 추가적인 인간의 주석, 훈련, 보조 모델, 미세 조정이 필요 없습니다.
- 여러 모델의 출력을 집계하는 전형적인 앙상블 접근법과 달리, 단일 언어 모델 위에서 작동하는 '자체 앙상블' 방식입니다.
- 성능 평가
- UL2-20B, GPT-3-175B, LaMDA-137B, PaLM-540B 등 다양한 크기의 언어 모델에 대해 평가를 진행했습니다.
- 모든 언어 모델에서 self-consistency는 chain-of-thought 프롬프팅보다 모든 작업에서 놀라운 정도로 성능이 향상되었습니다.
- 특히 PaLM-540B와 GPT-3에서는 GSM8K, SVAMP, AQuA, StrategyQA, ARC-challenge 등의 작업에서 새로운 최고 수준의 성능을 달성했습니다.
- 추가 실험에서는 기존 프롬프팅보다 chain-of-thought가 성능을 저하시킬 수 있는 NLP 작업에서도 self-consistency가 성능을 크게 향상시킬 수 있음을 보여줍니다.
2. Realted Work
- 언어 모델의 추론 작업
- 언어 모델은 산술, 논리, 상식 추론과 같은 Type 2 작업에서 어려움을 겪는 것으로 알려져 있습니다 (Evans, 2010).
- 이전 연구는 주로 추론 향상을 위한 특수 접근 방식에 중점을 두었습니다 (Andor et al., 2019; Ran et al., 2019 등).
- Self-consistency는 추가적인 감독이나 미세 조정 없이 다양한 추론 작업에 적용 가능하며 Wei et al. (2022)의 chain-of-thought 프롬프팅 접근법의 성능을 크게 향상시킵니다.
- 언어 모델에서의 샘플링과 재순위 매김
- 언어 모델에 대한 다양한 디코딩 전략이 제안되었습니다: temperature sampling, top-k sampling, nucleus sampling, minimum Bayes risk decoding, typical decoding 등.
- 다양성을 촉진하기 위한 연구도 있었습니다 (Batra et al., 2012; Li et al., 2016 등).
- 생성 품질을 개선하기 위해 재순위 매김을 사용하는 방법도 흔히 사용됩니다. 이러한 방법들은 추가적인 재순위 매김 훈련이나 인간의 주석 수집을 필요로 하지만, self-consistency는 이러한 추가 작업을 요구하지 않습니다.
- 추론 경로 추출
- 이전 연구에서는 의미 그래프 구축, RNN을 활용한 추론 경로 검색, 인간 주석 추론 경로에 대한 미세 조정 등 특정 작업에 초점을 맞춘 접근 방식을 고려했습니다.
- 최근에는 추론 과정의 다양성이 중요하다는 인식이 있었지만, 이는 추가적인 QA 모델 훈련이나 상식 지식 그래프에서 잠재 변수 도입과 같은 작업별 훈련을 통해 활용되었습니다.
- Self-consistency는 이러한 접근법들에 비해 훨씬 간단하며 추가 훈련을 요구하지 않습니다.
- 언어 모델의 일관성
- 이전 연구에서는 언어 모델이 대화, 설명 생성, 사실 지식 추출에서 일관성 문제를 겪는 것으로 나타났습니다.
- "일관성"은 재귀 언어 모델에서 무한 길이 시퀀스를 생성하는 데 사용되기도 했습니다.
- 본 논문에서는 "일관성"을 다소 다른 개념으로 다룹니다. 즉, 다양한 추론 경로 간의 답변 일관성을 활용하여 정확도를 향상시키는 것에 초점을 맞춥니다.
3. Self-Consistency over Diverse Reasoning Paths
- 인간의 사고 다양성 활용
- 사람들은 서로 다르게 생각한다는 점에 착안하여, 언어 모델의 디코더를 통해 다양한 추론 경로를 샘플링하는 방식을 제안합니다.
- 올바른 추론 과정은 다양할지라도 최종 답변에 있어 더 높은 일치를 보인다는 가설을 설정합니다.
- Self-Consistency 방법론
- 언어 모델에 수동으로 작성된 chain-of-thought 예시를 프롬프트로 제공합니다.
- 다음으로, 언어 모델의 디코더에서 후보 출력을 샘플링하여 다양한 추론 경로를 생성합니다.
- temperature sampling, top-k sampling, nucleus sampling 등 대부분의 샘플링 알고리즘과 호환됩니다.
- 추론 경로를 마진화하여 생성된 답변 중 가장 일관된 답변을 선택합니다.
- 상세한 접근 방식
- 생성된 답변 ai는 고정된 답변 집합 A에서 나옵니다. 여기서 i는 디코더에서 샘플링된 m개의 후보 출력을 인덱스합니다.
- Self-consistency는 추가적인 잠재 변수 ri를 도입합니다. 이는 i번째 출력에서의 추론 경로를 표현하는 토큰 시퀀스입니다.
- 여러 (ri, ai)를 샘플링한 후, ri를 마진화하여 ai에 대한 다수결을 취함으로써 가장 일관된 답변을 결정합니다.
- 답변 집계 전략을 비교한 결과, "가중치 없는 합계"와 "정규화된 가중치 합계"가 유사한 정확도를 보여줍니다.
- Self-Consistency의 응용
- 고정된 답변이 있는 추론 작업에 주로 적용됩니다.
- 그러나 이론적으로 이 접근법은 여러 생성물 간의 일관성을 측정할 수 있는 좋은 지표가 있을 경우, 오픈 텍스트 생성 문제로 확장될 수 있습니다.
4. Experiments
4.1 실험 설정
- 작업 및 데이터셋
- 산술 추론, 상식 추론, 기호 추론 작업에 대해 self-consistency를 평가합니다.
- 사용된 언어 모델: UL2-20B, GPT-3-175B, LaMDA-137B, PaLM-540B.
- 실험은 훈련이나 미세 조정 없이 few-shot 설정으로 수행됩니다.
- 샘플링 계획
- 다양한 추론 경로를 샘플링하기 위해 temperature sampling, top-k 샘플링을 적용합니다.
4.2 주요 결과
- 산술 추론
- Self-consistency는 모든 언어 모델에서 chain-of-thought 프롬프팅보다 상당히 높은 정확도를 보였습니다.
- 모델 규모가 커질수록 성능 향상이 더 두드러졌습니다.
- 거의 모든 작업에서 새로운 최고 성능을 달성했습니다.
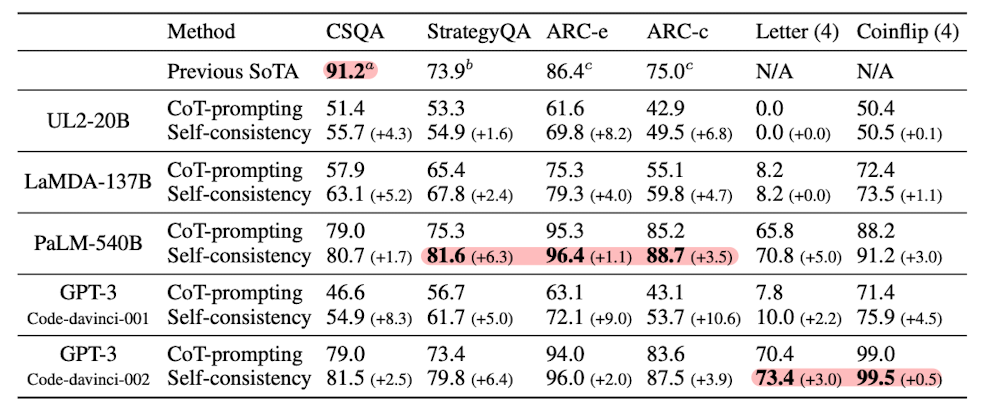
- 상식 및 기호 추론
- Self-consistency는 5개의 6개 작업에서 SoTA 결과를 달성했습니다.
- 기호 추론 작업에서도 상당한 성능 향상을 보였습니다.

4.3 Self-Consistency가 Chain-of-Thought 성능에 미치는 영향
- Chain-of-thought 프롬프팅이 성능을 저하시킬 수 있는 경우에도 self-consistency는 성능을 강화하고 표준 프롬프팅보다 우수한 결과를 보여줍니다.

4.4 다른 접근법과의 비교
- Sample-and-Rank 및 Beam Search와의 비교
- Self-consistency는 sample-and-rank 및 beam search 방식보다 우수한 성능을 보입니다.
- Beam search는 낮은 다양성을 제공하는 반면, self-consistency는 추론 경로의 다양성이 중요합니다.
- 앙상블 기반 접근법과의 비교
- Self-consistency는 기존 앙상블 기반 방법보다 더 큰 이득을 보입니다.
4.5 추가 연구
- 샘플링 전략 및 파라미터에 대한 견고성
- Self-consistency는 다양한 샘플링 전략과 파라미터에 견고합니다.
- 모델 규모가 증가함에 따라 성능이 향상됩니다.
- 불완전한 프롬프트에 대한 견고성
- Self-consistency는 불완전한 프롬프트에 대해 언어 모델의 견고성을 향상시킵니다.
- 일관성은 정확도와 높은 상관관계를 보입니다.
- 비자연어 추론 경로 및 제로샷 CoT에서의 작동
- Self-consistency는 자연어 추론 경로뿐만 아니라 수식과 같은 대체 형태의 추론 경로에서도 효과적입니다.
- 제로샷 CoT에서도 유의미한 성능 향상을 보입니다.
5. Conclusion and Discussion
- Self-Consistency의 효과
- Self-consistency는 단순하지만 효과적인 방법으로, 다양한 규모의 네 가지 대규모 언어 모델에서 산술 및 상식 추론 작업의 정확도를 크게 향상시킵니다.
- 정확도 향상 외에도, self-consistency는 언어 모델을 사용한 추론 작업에서 근거 수집, 불확실성 추정, 언어 모델 출력의 보정 향상에 유용합니다.
- Self-Consistency의 한계
- 이 방법은 추가적인 계산 비용을 발생시킵니다.
- 실제 사용에서는 비용을 줄이기 위해 적은 수의 경로(예: 5 또는 10)를 사용하는 것이 좋으며, 대부분의 경우 성능은 빠르게 포화 상태에 이릅니다.
- 향후 연구 방향
- Self-consistency를 사용하여 더 나은 감독 데이터를 생성하고, 이를 통해 모델을 미세 조정하여 단일 추론 실행에서 더 정확한 예측을 할 수 있도록 하는 것이 한 방향입니다.
- 또한, 언어 모델이 때때로 잘못되거나 비논리적인 추론 경로를 생성할 수 있으며(예: StrategyQA 예시), 모델의 근거 생성을 더 잘 뒷받침하기 위한 추가적인 작업이 필요합니다.
6. Insights
여러 결과를 sampling하고 가장 여러 번 등장한 결과를 다수결에 의해 정답으로 추출한다는 아이디어 자체는 굉장히 심플한 것 같습니다.
물론 상대적으로 비용이 굉장히 많이 든다는 문제점이 있지만 정확성 자체는 높아질 수 밖에 없는 전략처럼 보입니다.
지금에 이르러서는 다수결 투표를 LLM으로 진행할 수 있지 않을까 싶은 생각이 듭니다.
본 연구의 한계는 정답이 명확하게 정해져 있는 것에 대해만 적용 가능한 전략이라는 점인데,
LLM을 활용하면 예를 들어 번역된 문장의 score를 구한다던가 좋고 나쁨을 상대적으로 평가하여 여러 정답 후보 중에서 가장 좋은 평가를 받은 걸 추출해낼 수 있을 것 같습니다.
물론 이를 추론 과정에서 사용하는 것도 방법이겠지만 이러한 방식으로 구축한 데이터셋을 다른 모델 학습에 활용할 수도 있을 거라는 생각이 듭니다.
출처 : https://arxiv.org/abs/2203.11171
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper, we propose a new decoding strategy, self-consistency, to replace the naive greedy decoding used in chain-
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Research, Brain Team]
- 본 논문에서는 chain-of-thought 프롬프팅에 사용되던 단순한 greedy decoding 대신 새로운 디코딩 전략인 'self-consistency'를 제안합니다.
- 이 전략은 greedy 방식 대신 다양한 추론 경로를 샘플링한 후 가장 일관성 있는 답변을 선택하는 방식입니다. 이는 복잡한 추론 문제가 일반적으로 정확한 답을 이끌어내는 다양한 사고 방식을 허용한다는 직관을 활용합니다.
- 대규모 실증 평가를 통해, self-consistency가 chain-of-thought 프롬프팅의 성능을 GSM8K(+17.9%), SVAMP(+11.0%), AQuA(+12.2%), StrategyQA(+6.4%), ARC-challenge(+3.9%) 등의 인기 있는 산술 및 상식 추론 벤치마크에서 크게 향상시킨다는 것을 입증했습니다.
1. Introduction
- 도입부 요약
- 언어 모델은 다양한 NLP 작업에서 뛰어난 성공을 거두었지만, 추론 능력의 한계는 모델 크기 증가만으로 극복하기 어렵다는 인식이 있습니다 (Rae et al., 2021; BIG-bench collaboration, 2021).
- Wei et al. (2022)은 이러한 단점을 해결하기 위해 사람의 추론 과정을 모방한 짧은 문장 시리즈를 생성하는 'chain-of-thought 프롬프팅'을 제안했습니다. 이 방법은 다단계 추론 작업에서 모델 성능을 크게 향상시킵니다.
- Self-Consistency의 도입
- 본 논문에서는 chain-of-thought 프롬프팅에 사용된 greedy 디코딩 전략을 대체할 새로운 디코딩 전략인 'self-consistency'를 소개합니다.
- Self-consistency는 복잡한 추론 작업이 여러 가지 추론 경로를 허용하며 이는 정확한 답으로 이어진다는 직관을 활용합니다.
- 이 전략은 'sample-and-marginalize' 디코딩 절차를 제안합니다: 언어 모델로부터 다양한 추론 경로를 샘플링하고, 이를 통해 가장 일관된 답을 도출합니다.
- Self-Consistency의 장점
- 추가 검증기를 훈련하거나 인간의 주석을 바탕으로 재순위를 매기는 기존 방법보다 훨씬 단순합니다.
- 완전한 비감독 학습 방식으로, 추가적인 인간의 주석, 훈련, 보조 모델, 미세 조정이 필요 없습니다.
- 여러 모델의 출력을 집계하는 전형적인 앙상블 접근법과 달리, 단일 언어 모델 위에서 작동하는 '자체 앙상블' 방식입니다.
- 성능 평가
- UL2-20B, GPT-3-175B, LaMDA-137B, PaLM-540B 등 다양한 크기의 언어 모델에 대해 평가를 진행했습니다.
- 모든 언어 모델에서 self-consistency는 chain-of-thought 프롬프팅보다 모든 작업에서 놀라운 정도로 성능이 향상되었습니다.
- 특히 PaLM-540B와 GPT-3에서는 GSM8K, SVAMP, AQuA, StrategyQA, ARC-challenge 등의 작업에서 새로운 최고 수준의 성능을 달성했습니다.
- 추가 실험에서는 기존 프롬프팅보다 chain-of-thought가 성능을 저하시킬 수 있는 NLP 작업에서도 self-consistency가 성능을 크게 향상시킬 수 있음을 보여줍니다.
2. Realted Work
- 언어 모델의 추론 작업
- 언어 모델은 산술, 논리, 상식 추론과 같은 Type 2 작업에서 어려움을 겪는 것으로 알려져 있습니다 (Evans, 2010).
- 이전 연구는 주로 추론 향상을 위한 특수 접근 방식에 중점을 두었습니다 (Andor et al., 2019; Ran et al., 2019 등).
- Self-consistency는 추가적인 감독이나 미세 조정 없이 다양한 추론 작업에 적용 가능하며 Wei et al. (2022)의 chain-of-thought 프롬프팅 접근법의 성능을 크게 향상시킵니다.
- 언어 모델에서의 샘플링과 재순위 매김
- 언어 모델에 대한 다양한 디코딩 전략이 제안되었습니다: temperature sampling, top-k sampling, nucleus sampling, minimum Bayes risk decoding, typical decoding 등.
- 다양성을 촉진하기 위한 연구도 있었습니다 (Batra et al., 2012; Li et al., 2016 등).
- 생성 품질을 개선하기 위해 재순위 매김을 사용하는 방법도 흔히 사용됩니다. 이러한 방법들은 추가적인 재순위 매김 훈련이나 인간의 주석 수집을 필요로 하지만, self-consistency는 이러한 추가 작업을 요구하지 않습니다.
- 추론 경로 추출
- 이전 연구에서는 의미 그래프 구축, RNN을 활용한 추론 경로 검색, 인간 주석 추론 경로에 대한 미세 조정 등 특정 작업에 초점을 맞춘 접근 방식을 고려했습니다.
- 최근에는 추론 과정의 다양성이 중요하다는 인식이 있었지만, 이는 추가적인 QA 모델 훈련이나 상식 지식 그래프에서 잠재 변수 도입과 같은 작업별 훈련을 통해 활용되었습니다.
- Self-consistency는 이러한 접근법들에 비해 훨씬 간단하며 추가 훈련을 요구하지 않습니다.
- 언어 모델의 일관성
- 이전 연구에서는 언어 모델이 대화, 설명 생성, 사실 지식 추출에서 일관성 문제를 겪는 것으로 나타났습니다.
- "일관성"은 재귀 언어 모델에서 무한 길이 시퀀스를 생성하는 데 사용되기도 했습니다.
- 본 논문에서는 "일관성"을 다소 다른 개념으로 다룹니다. 즉, 다양한 추론 경로 간의 답변 일관성을 활용하여 정확도를 향상시키는 것에 초점을 맞춥니다.
3. Self-Consistency over Diverse Reasoning Paths
- 인간의 사고 다양성 활용
- 사람들은 서로 다르게 생각한다는 점에 착안하여, 언어 모델의 디코더를 통해 다양한 추론 경로를 샘플링하는 방식을 제안합니다.
- 올바른 추론 과정은 다양할지라도 최종 답변에 있어 더 높은 일치를 보인다는 가설을 설정합니다.
- Self-Consistency 방법론
- 언어 모델에 수동으로 작성된 chain-of-thought 예시를 프롬프트로 제공합니다.
- 다음으로, 언어 모델의 디코더에서 후보 출력을 샘플링하여 다양한 추론 경로를 생성합니다.
- temperature sampling, top-k sampling, nucleus sampling 등 대부분의 샘플링 알고리즘과 호환됩니다.
- 추론 경로를 마진화하여 생성된 답변 중 가장 일관된 답변을 선택합니다.
- 상세한 접근 방식
- 생성된 답변 ai는 고정된 답변 집합 A에서 나옵니다. 여기서 i는 디코더에서 샘플링된 m개의 후보 출력을 인덱스합니다.
- Self-consistency는 추가적인 잠재 변수 ri를 도입합니다. 이는 i번째 출력에서의 추론 경로를 표현하는 토큰 시퀀스입니다.
- 여러 (ri, ai)를 샘플링한 후, ri를 마진화하여 ai에 대한 다수결을 취함으로써 가장 일관된 답변을 결정합니다.
- 답변 집계 전략을 비교한 결과, "가중치 없는 합계"와 "정규화된 가중치 합계"가 유사한 정확도를 보여줍니다.
- Self-Consistency의 응용
- 고정된 답변이 있는 추론 작업에 주로 적용됩니다.
- 그러나 이론적으로 이 접근법은 여러 생성물 간의 일관성을 측정할 수 있는 좋은 지표가 있을 경우, 오픈 텍스트 생성 문제로 확장될 수 있습니다.
4. Experiments
4.1 실험 설정
- 작업 및 데이터셋
- 산술 추론, 상식 추론, 기호 추론 작업에 대해 self-consistency를 평가합니다.
- 사용된 언어 모델: UL2-20B, GPT-3-175B, LaMDA-137B, PaLM-540B.
- 실험은 훈련이나 미세 조정 없이 few-shot 설정으로 수행됩니다.
- 샘플링 계획
- 다양한 추론 경로를 샘플링하기 위해 temperature sampling, top-k 샘플링을 적용합니다.
4.2 주요 결과
- 산술 추론
- Self-consistency는 모든 언어 모델에서 chain-of-thought 프롬프팅보다 상당히 높은 정확도를 보였습니다.
- 모델 규모가 커질수록 성능 향상이 더 두드러졌습니다.
- 거의 모든 작업에서 새로운 최고 성능을 달성했습니다.
- 상식 및 기호 추론
- Self-consistency는 5개의 6개 작업에서 SoTA 결과를 달성했습니다.
- 기호 추론 작업에서도 상당한 성능 향상을 보였습니다.
4.3 Self-Consistency가 Chain-of-Thought 성능에 미치는 영향
- Chain-of-thought 프롬프팅이 성능을 저하시킬 수 있는 경우에도 self-consistency는 성능을 강화하고 표준 프롬프팅보다 우수한 결과를 보여줍니다.
4.4 다른 접근법과의 비교
- Sample-and-Rank 및 Beam Search와의 비교
- Self-consistency는 sample-and-rank 및 beam search 방식보다 우수한 성능을 보입니다.
- Beam search는 낮은 다양성을 제공하는 반면, self-consistency는 추론 경로의 다양성이 중요합니다.
- 앙상블 기반 접근법과의 비교
- Self-consistency는 기존 앙상블 기반 방법보다 더 큰 이득을 보입니다.
4.5 추가 연구
- 샘플링 전략 및 파라미터에 대한 견고성
- Self-consistency는 다양한 샘플링 전략과 파라미터에 견고합니다.
- 모델 규모가 증가함에 따라 성능이 향상됩니다.
- 불완전한 프롬프트에 대한 견고성
- Self-consistency는 불완전한 프롬프트에 대해 언어 모델의 견고성을 향상시킵니다.
- 일관성은 정확도와 높은 상관관계를 보입니다.
- 비자연어 추론 경로 및 제로샷 CoT에서의 작동
- Self-consistency는 자연어 추론 경로뿐만 아니라 수식과 같은 대체 형태의 추론 경로에서도 효과적입니다.
- 제로샷 CoT에서도 유의미한 성능 향상을 보입니다.
5. Conclusion and Discussion
- Self-Consistency의 효과
- Self-consistency는 단순하지만 효과적인 방법으로, 다양한 규모의 네 가지 대규모 언어 모델에서 산술 및 상식 추론 작업의 정확도를 크게 향상시킵니다.
- 정확도 향상 외에도, self-consistency는 언어 모델을 사용한 추론 작업에서 근거 수집, 불확실성 추정, 언어 모델 출력의 보정 향상에 유용합니다.
- Self-Consistency의 한계
- 이 방법은 추가적인 계산 비용을 발생시킵니다.
- 실제 사용에서는 비용을 줄이기 위해 적은 수의 경로(예: 5 또는 10)를 사용하는 것이 좋으며, 대부분의 경우 성능은 빠르게 포화 상태에 이릅니다.
- 향후 연구 방향
- Self-consistency를 사용하여 더 나은 감독 데이터를 생성하고, 이를 통해 모델을 미세 조정하여 단일 추론 실행에서 더 정확한 예측을 할 수 있도록 하는 것이 한 방향입니다.
- 또한, 언어 모델이 때때로 잘못되거나 비논리적인 추론 경로를 생성할 수 있으며(예: StrategyQA 예시), 모델의 근거 생성을 더 잘 뒷받침하기 위한 추가적인 작업이 필요합니다.
6. Insights
여러 결과를 sampling하고 가장 여러 번 등장한 결과를 다수결에 의해 정답으로 추출한다는 아이디어 자체는 굉장히 심플한 것 같습니다.
물론 상대적으로 비용이 굉장히 많이 든다는 문제점이 있지만 정확성 자체는 높아질 수 밖에 없는 전략처럼 보입니다.
지금에 이르러서는 다수결 투표를 LLM으로 진행할 수 있지 않을까 싶은 생각이 듭니다.
본 연구의 한계는 정답이 명확하게 정해져 있는 것에 대해만 적용 가능한 전략이라는 점인데,
LLM을 활용하면 예를 들어 번역된 문장의 score를 구한다던가 좋고 나쁨을 상대적으로 평가하여 여러 정답 후보 중에서 가장 좋은 평가를 받은 걸 추출해낼 수 있을 것 같습니다.
물론 이를 추론 과정에서 사용하는 것도 방법이겠지만 이러한 방식으로 구축한 데이터셋을 다른 모델 학습에 활용할 수도 있을 거라는 생각이 듭니다.
출처 : https://arxiv.org/abs/2203.11171
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper, we propose a new decoding strategy, self-consistency, to replace the naive greedy decoding used in chain-
arxiv.org