
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
0. Abstract
[Upstage AI]
- SOLAR 10.7B 소개: 107억 개의 파라미터를 가진 대규모 언어 모델(Large Language Model, LLM).
- 주요 특징: 다양한 자연어 처리(Natural Language Processing, NLP) 작업에서 우수한 성능을 보임.
- Depth Up-Scaling(DUS) 방법 제시: LLM의 효율적인 확장을 위한 깊이 기반 스케일링과 지속적인 사전 훈련을 포함.
- DUS의 장점: 기존 대규모 LLM 스케일링 방법들과 달리 복잡한 변경 없이 효율적인 훈련 및 추론 가능.
- 실험을 통한 검증: DUS가 고성능 LLM을 확장하는 데 간단하면서도 효과적임을 입증.
- SOLAR 10.7B-Instruct: 지시사항을 따르는 능력에 특화된 버전으로 Mixtral-8x7B-Instruct를 능가.
- 공개성: Apache 2.0 라이선스 하에 공개, LLM 분야에서의 광범위한 접근 및 활용 촉진.
1. Introduction
- NLP 분야의 변화: 대규모 언어 모델(Large Language Models, LLMs) 도입으로 자연어 처리(Natural Language Processing, NLP) 분야가 크게 변모함.
- 새로운 도전: 더 큰 모델의 필요성 증가로 인해 훈련의 어려움이 생김(Kaplan et al., 2020; Hernandez et al., 2021 등).
- 기존 접근법: MoE(Mixture of Experts)를 활용한 언어 모델 확장 방법 제안(Shazeer et al., 2017; Komatsuzaki et al., 2022 등), 하지만 훈련 및 추론 프레임워크에 상당한 변경이 필요(Gale et al., 2023).
- DUS 제시: Komatsuzaki et al. (2022)에 영감을 받아, 간단하면서도 효율적인 LLM 스케일링 방법인 Depth Up-Scaling(DUS)을 제안.
- DUS의 특징: MoE 대신 깊이 방향으로 모델을 확장하는 방법으로, 추가 모듈이나 동적 구성 없이 HuggingFace(Wolf et al., 2019)와 같은 사용하기 쉬운 LLM 프레임워크와 바로 호환됨.
- DUS 적용: 모든 트랜스포머 아키텍처에 적용 가능, 간단하고 효율적인 방법으로 LLM을 확장하는 새로운 길 제시.
- SOLAR 10.7B 개발: DUS를 사용하여 107억 파라미터를 가진 SOLAR 10.7B를 개발, 기존 모델(Llama 2, Mistral 7B)보다 우수한 성능 보임.
- SOLAR 10.7B-Instruct 개발: 복잡한 지시사항을 엄격하게 준수해야 하는 작업에 특화된 모델로, Mixtral-8x7B-Instruct보다 높은 성능을 보임.
- Apache 2.0 라이선스 하의 공개: NLP 분야의 협업 및 혁신 촉진을 목표로 SOLAR 10.7B를 오픈 소스로 공개, 전 세계 연구자 및 개발자들이 모델에 더 넓게 접근하고 활용할 수 있게 함.
2. Depth Up-Scaling
- 목표: 사전 훈련된 기본 모델의 가중치를 활용하여 대규모 LLM으로 효율적으로 확장(Komatsuzaki et al., 2022 참고).
- 깊이 기반 스케일링: 기존 MoE 방법 대신 Tan과 Le (2019)에서 영감을 받은 다른 깊이 스케일링 전략 채택. 단순한 모델 확장만으로는 성능 저하 발생하므로, 확장된 모델에 지속적인 사전 훈련 적용 필요.
기본 모델
- Llama 2 아키텍처(32-layer)를 기본 모델로 선택, Mistral 7B의 사전 훈련된 가중치로 초기화.
- 기본 모델로 Llama 2 아키텍처를 사용함으로써, 커뮤니티 자원을 활용하고 새로운 수정을 통해 능력 향상 목표.
깊이 기반 스케일링
- 기본 모델의 레이어 수(n)를 설정하고, 사용 가능한 하드웨어를 고려하여 확장 모델의 목표 레이어 수(s)를 결정.
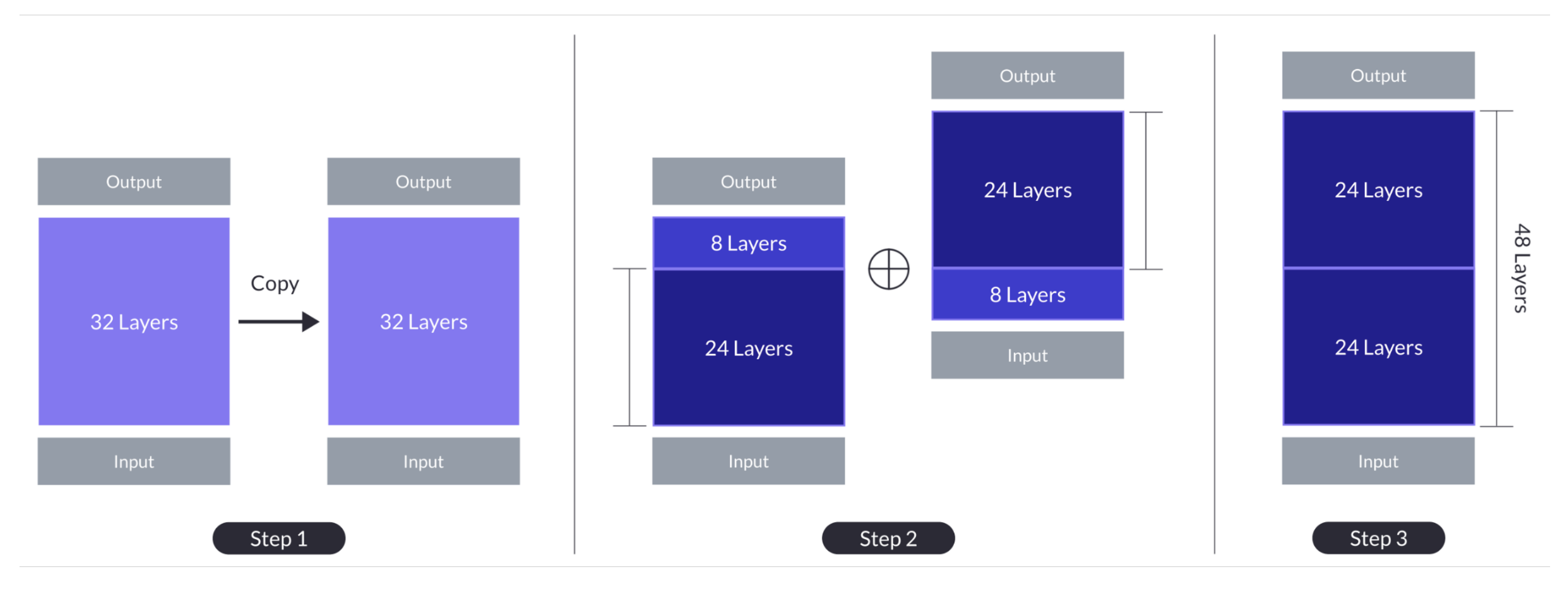
- 깊이 기반 스케일링 과정: 기본 모델을 복제 후, 원본 모델에서 마지막 m 레이어 제거 및 복제 모델에서 처음 m 레이어 제거하여 n−m 레이어의 두 모델 생성. 이 두 모델을 연결하여 s=2⋅(n−m) 레이어의 확장 모델 형성. 예: n=32, s=48, m=8인 경우 깊이 기반 스케일링 과정이 Fig. 1의 ‘Step 1: Depthwise Scaling’에 설명됨.
- 동시 개발된 커뮤니티 방법론도 ‘Step 1: Depthwise Scaling’과 유사함.
지속적인 사전 훈련
- 깊이 기반 확장 모델의 초기 성능은 기본 LLM보다 낮으나, 지속적인 사전 훈련을 통해 빠른 성능 회복 관찰(Komatsuzaki et al., 2022).
- 깊이 기반 확장 모델의 이질성 탐구: 레이어를 단순히 반복하는 대신, 중간의 2⋅m 레이어를 제거하여 이음새에서의 차이를 줄임. 이로 인해 지속적인 사전 훈련을 통해 성능을 빠르게 회복할 수 있음.
- DUS의 성공 요인: 깊이 기반 스케일링 및 지속적인 사전 훈련 단계에서의 이질성 감소. 다른 깊이 기반 스케일링 방법도 DUS에 적용 가능할 것으로 가정, 단 이질성이 지속적인 사전 훈련 단계 전에 충분히 해결되어야 함.
기타 확장 방법과의 비교
- Komatsuzaki et al. (2022)의 방법과 달리, 깊이 기반 확장 모델은 추가적인 모듈(예: 게이팅 네트워크, 동적 전문가 선택)이 필요 없음.
- 결과적으로, DUS 모델은 기존의 훈련 및 추론 프레임워크에 쉽게 통합되며, 최적의 훈련 효율성과 빠른 추론을 위한 특수 CUDA 커널이 필요 없음.
3. Training Details
SOLAR 10.7B 모델은 Depth Up-Scaling(DUS) 및 지속적인 사전 훈련 후 두 단계의 미세 조정을 거침:
1) 지시사항 튜닝(instruction tuning)과 2) 정렬 튜닝(alignment tuning).
지시사항 튜닝
- 목적: 모델이 QA 형식으로 지시사항을 따르도록 훈련(Zhang et al., 2023b).
- 데이터셋: 대부분 오픈 소스 데이터셋 사용, 수학 QA 데이터셋은 모델의 수학적 능력 강화를 위해 합성.
- 데이터셋 생성 과정: 기존 벤치마크 데이터셋(GSM8K 등)과의 중복 방지를 위해 Math 데이터셋(Hendrycks et al., 2021)만 사용하여 초기 수학 데이터 수집, MetaMath 유사 과정을 통해 질문과 답변 재구성, 'Synth. Math-Instruct'라 명명한 QA 데이터셋으로 사용.
정렬 튜닝
- 목적: 지시사항 튜닝된 모델을 더욱 인간 또는 강력한 AI(예: GPT4 OpenAI (2023)) 선호도와 일치하도록 직접적인 선호도 최적화(DPO)로 Rafailov et al. (2023)의 방법을 이용하여 미세 조정.
- 데이터셋: 주로 오픈 소스 데이터셋 사용 및 지시사항 튜닝 단계에서 언급된 'Synth. Math-Instruct' 데이터셋을 활용하여 수학 중심의 정렬 데이터셋 합성.
- 데이터셋 합성 과정: 'Synth. Math-Instruct'의 재구성된 질문-답변 쌍이 수학 능력 강화에 유리하다는 점을 활용, 재구성된 답변을 선택된 응답으로, 원본 답변을 거부된 응답으로 사용하여 {프롬프트, 선택된 응답, 거부된 응답} DPO 튜플 생성, 이를 통합하여 'Synth. Math-Alignment' 데이터셋 구성.
평가 결과
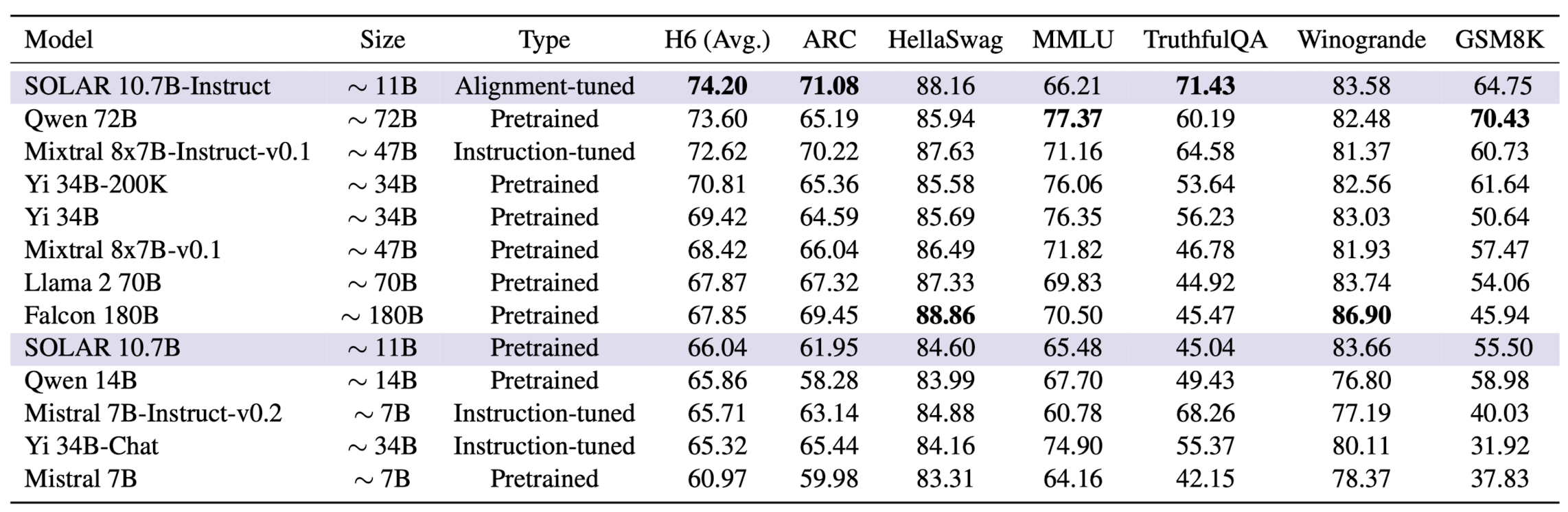
- SOLAR 10.7B와 SOLAR 10.7B-Instruct, 그리고 다른 최고 성능 모델들의 평가 결과(Table 2 참조).
- 평가 지표: 6가지 작업(H6 평균 포함)의 점수와 모델 크기(억 단위 파라미터), 훈련 단계(Pretrained, Instruction-tuned, Alignment-tuned) 표시.
- SOLAR 10.7B 기반 모델은 보라색으로 표시, H6 및 개별 작업의 최고 점수는 굵은 글씨로 표시.
4. Experiments
4.1 Experimental Details
Training Datasets
- 주요 데이터셋: 지시사항 및 정렬 튜닝 단계에 사용된 데이터셋 상세 정보는 표 1에 제시.
- 데이터 샘플링: 전체 데이터셋을 항상 사용하는 것이 아니라, 일부만 샘플링하여 사용.
- 데이터 포맷: 지시사항 데이터셋은 Alpaca 스타일의 채팅 템플릿으로 재구성. OpenOrca(FLAN에서 유도)와 같은 데이터셋은 벤치마크 데이터셋과 중복되는 데이터 필터링.
- 정렬 데이터셋: {프롬프트, 선택된 응답, 거부된 응답} 트리플릿 형식으로 전처리.

평가
- HuggingFace Open LLM Leaderboard의 6가지 평가 방법 사용: ARC, HellaSWAG, MMLU, TruthfulQA, Winogrande, GSM8K.
- H6 점수(6가지 작업의 평균 점수) 보고.
모델 결합
- 모델 결합 방법(Yadav et al., 2023)을 통해 추가 훈련 없이 성능 향상 가능.
- 지시사항 및 정렬 튜닝 단계에서 훈련된 모델들을 결합하여 성능 향상을 시도.
4.2 Main Results
- SOLAR 10.7B는 유사한 크기의 다른 사전 훈련된 모델들(예: Qwen 14B, Mistral 7B)을 능가하여 DUS의 효과를 입증.
- SOLAR 10.7B-Instruct는 더 작은 크기에도 불구하고 H6에서 가장 높은 점수를 기록, 최신 최고 성능의 오픈 소스 LLM(예: Mixtral 8x7B-Instruct-v0.1, Qwen 72B)을 능가.
- SOLAR 10.7B-Instruct의 데이터 유출 결과는 부록 C에 보고됨.
4.3 Ablation Studies
지시사항 튜닝
- 다양한 지시사항 튜닝 훈련 데이터셋에 대한 소거 연구를 표 3에 제시.
- Alpaca-GPT4, OpenOrca, Synth. Math-Instruct 데이터셋 사용 여부에 따라 H6 점수와 개별 작업 점수의 변화 분석.
- 모델 결합을 통한 성능 향상 가능성 확인.

정렬 튜닝
- DPO 단계에서 사용된 다양한 정렬 훈련 데이터셋, SFT 기반 모델, 모델 결합 전략에 대한 소거 연구 제시.
- Ultrafeedback Clean과 Synth. Math-Alignment 데이터셋의 영향 분석.
- 서로 다른 SFT 기반 모델 사용 시 성능 차이 분석.
- 모델 결합 방법(예: 평균, SLERP)에 따른 성능 차이 분석 및 최종 모델 선택.
5. Conclusion
- SOLAR 10.7B 및 그의 미세 조정된 변형인 SOLAR 10.7B-Instruct 소개: 깊이 확장된(Depth Up-Scaled, DUS) 107억 파라미터를 가진 모델.
- 성능: Llama 2, Mistral 7B, Mixtral-7B-Instruct와 같은 모델들보다 주요 NLP 작업에서 우수한 성능을 보임.
- 효율성: 계산 효율성을 유지하면서 소규모 모델로부터 고성능 LLM을 확장하는 데 DUS가 효과적임을 입증.
- 향후 전망: 더 많은 탐색을 통해 DUS를 더욱 개선하고, 효율적으로 LLM을 확장하는 새로운 방향을 제시할 수 있음.
6. Insights
이 모델이 등장한 지 얼마 되지도 않았지만 벌써 OpenLLM 리더보드가 난리가 난 듯합니다..
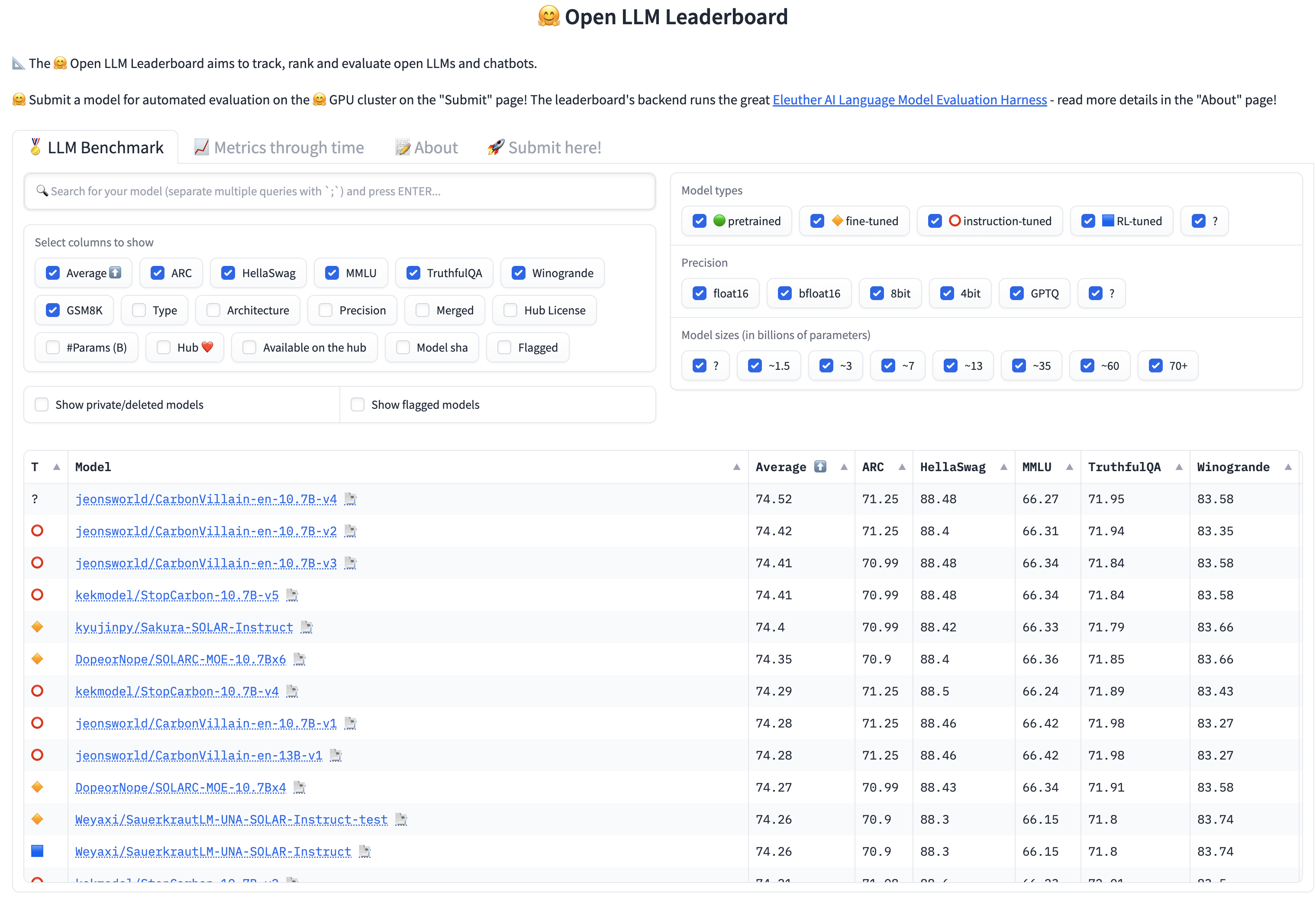
모델을 학습하지 않고도 성능 향상이 가능하다고 알려졌는데요,
그래서 모델을 합치는 방법만 알면 위 이미지처럼 여러 버전의 모델들이 리더보드를 차지해버리는 상황도 나오나 봅니다..
(링크 참고: mergekit)
모델의 뛰어남을 리더보드를 통해 입증했는데, 그 덕분에 리더보드가 난리가 나버려서 신뢰성이 더욱 떨어진 것처럼 느껴지겠네요.
아무래도 여기에서의 포인트는 '학습하지 않고'일 것입니다...
논문에서도 모델을 합칠 때 단순 평균 방식과 SLERP 방식 중 더욱 효과적인 것을 비교했는데요, 결국 ensemble이라는 거..겠죠?
물론 그렇게 간단하지는 않은데 모델을 합치는 방식 자체가 결과에 직접적인 영향을 주지는 않았다고 밝힌 것을 보면..
그냥 다른 특성(장단점)을 지니는 모델을 병합하는 것이 주는 긍정적인 효과가 크다고 해석이 가능해 보이구요.
이미 진행 중이겠지만 이러한 방식을 사방팔방 온갖 도메인에서 적용하지 않을까.. 싶네요.
이게 정말 인공지능 모델의 발전 방향이 맞을까, 의문이 드는 상황입니다 🤔
출처 : https://arxiv.org/abs/2312.15166
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for sca
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
0. Abstract
[Upstage AI]
- SOLAR 10.7B 소개: 107억 개의 파라미터를 가진 대규모 언어 모델(Large Language Model, LLM).
- 주요 특징: 다양한 자연어 처리(Natural Language Processing, NLP) 작업에서 우수한 성능을 보임.
- Depth Up-Scaling(DUS) 방법 제시: LLM의 효율적인 확장을 위한 깊이 기반 스케일링과 지속적인 사전 훈련을 포함.
- DUS의 장점: 기존 대규모 LLM 스케일링 방법들과 달리 복잡한 변경 없이 효율적인 훈련 및 추론 가능.
- 실험을 통한 검증: DUS가 고성능 LLM을 확장하는 데 간단하면서도 효과적임을 입증.
- SOLAR 10.7B-Instruct: 지시사항을 따르는 능력에 특화된 버전으로 Mixtral-8x7B-Instruct를 능가.
- 공개성: Apache 2.0 라이선스 하에 공개, LLM 분야에서의 광범위한 접근 및 활용 촉진.
1. Introduction
- NLP 분야의 변화: 대규모 언어 모델(Large Language Models, LLMs) 도입으로 자연어 처리(Natural Language Processing, NLP) 분야가 크게 변모함.
- 새로운 도전: 더 큰 모델의 필요성 증가로 인해 훈련의 어려움이 생김(Kaplan et al., 2020; Hernandez et al., 2021 등).
- 기존 접근법: MoE(Mixture of Experts)를 활용한 언어 모델 확장 방법 제안(Shazeer et al., 2017; Komatsuzaki et al., 2022 등), 하지만 훈련 및 추론 프레임워크에 상당한 변경이 필요(Gale et al., 2023).
- DUS 제시: Komatsuzaki et al. (2022)에 영감을 받아, 간단하면서도 효율적인 LLM 스케일링 방법인 Depth Up-Scaling(DUS)을 제안.
- DUS의 특징: MoE 대신 깊이 방향으로 모델을 확장하는 방법으로, 추가 모듈이나 동적 구성 없이 HuggingFace(Wolf et al., 2019)와 같은 사용하기 쉬운 LLM 프레임워크와 바로 호환됨.
- DUS 적용: 모든 트랜스포머 아키텍처에 적용 가능, 간단하고 효율적인 방법으로 LLM을 확장하는 새로운 길 제시.
- SOLAR 10.7B 개발: DUS를 사용하여 107억 파라미터를 가진 SOLAR 10.7B를 개발, 기존 모델(Llama 2, Mistral 7B)보다 우수한 성능 보임.
- SOLAR 10.7B-Instruct 개발: 복잡한 지시사항을 엄격하게 준수해야 하는 작업에 특화된 모델로, Mixtral-8x7B-Instruct보다 높은 성능을 보임.
- Apache 2.0 라이선스 하의 공개: NLP 분야의 협업 및 혁신 촉진을 목표로 SOLAR 10.7B를 오픈 소스로 공개, 전 세계 연구자 및 개발자들이 모델에 더 넓게 접근하고 활용할 수 있게 함.
2. Depth Up-Scaling
- 목표: 사전 훈련된 기본 모델의 가중치를 활용하여 대규모 LLM으로 효율적으로 확장(Komatsuzaki et al., 2022 참고).
- 깊이 기반 스케일링: 기존 MoE 방법 대신 Tan과 Le (2019)에서 영감을 받은 다른 깊이 스케일링 전략 채택. 단순한 모델 확장만으로는 성능 저하 발생하므로, 확장된 모델에 지속적인 사전 훈련 적용 필요.
기본 모델
- Llama 2 아키텍처(32-layer)를 기본 모델로 선택, Mistral 7B의 사전 훈련된 가중치로 초기화.
- 기본 모델로 Llama 2 아키텍처를 사용함으로써, 커뮤니티 자원을 활용하고 새로운 수정을 통해 능력 향상 목표.
깊이 기반 스케일링
- 기본 모델의 레이어 수(n)를 설정하고, 사용 가능한 하드웨어를 고려하여 확장 모델의 목표 레이어 수(s)를 결정.
- 깊이 기반 스케일링 과정: 기본 모델을 복제 후, 원본 모델에서 마지막 m 레이어 제거 및 복제 모델에서 처음 m 레이어 제거하여 n−m 레이어의 두 모델 생성. 이 두 모델을 연결하여 s=2⋅(n−m) 레이어의 확장 모델 형성. 예: n=32, s=48, m=8인 경우 깊이 기반 스케일링 과정이 Fig. 1의 ‘Step 1: Depthwise Scaling’에 설명됨.
- 동시 개발된 커뮤니티 방법론도 ‘Step 1: Depthwise Scaling’과 유사함.
지속적인 사전 훈련
- 깊이 기반 확장 모델의 초기 성능은 기본 LLM보다 낮으나, 지속적인 사전 훈련을 통해 빠른 성능 회복 관찰(Komatsuzaki et al., 2022).
- 깊이 기반 확장 모델의 이질성 탐구: 레이어를 단순히 반복하는 대신, 중간의 2⋅m 레이어를 제거하여 이음새에서의 차이를 줄임. 이로 인해 지속적인 사전 훈련을 통해 성능을 빠르게 회복할 수 있음.
- DUS의 성공 요인: 깊이 기반 스케일링 및 지속적인 사전 훈련 단계에서의 이질성 감소. 다른 깊이 기반 스케일링 방법도 DUS에 적용 가능할 것으로 가정, 단 이질성이 지속적인 사전 훈련 단계 전에 충분히 해결되어야 함.
기타 확장 방법과의 비교
- Komatsuzaki et al. (2022)의 방법과 달리, 깊이 기반 확장 모델은 추가적인 모듈(예: 게이팅 네트워크, 동적 전문가 선택)이 필요 없음.
- 결과적으로, DUS 모델은 기존의 훈련 및 추론 프레임워크에 쉽게 통합되며, 최적의 훈련 효율성과 빠른 추론을 위한 특수 CUDA 커널이 필요 없음.
3. Training Details
SOLAR 10.7B 모델은 Depth Up-Scaling(DUS) 및 지속적인 사전 훈련 후 두 단계의 미세 조정을 거침:
1) 지시사항 튜닝(instruction tuning)과 2) 정렬 튜닝(alignment tuning).
지시사항 튜닝
- 목적: 모델이 QA 형식으로 지시사항을 따르도록 훈련(Zhang et al., 2023b).
- 데이터셋: 대부분 오픈 소스 데이터셋 사용, 수학 QA 데이터셋은 모델의 수학적 능력 강화를 위해 합성.
- 데이터셋 생성 과정: 기존 벤치마크 데이터셋(GSM8K 등)과의 중복 방지를 위해 Math 데이터셋(Hendrycks et al., 2021)만 사용하여 초기 수학 데이터 수집, MetaMath 유사 과정을 통해 질문과 답변 재구성, 'Synth. Math-Instruct'라 명명한 QA 데이터셋으로 사용.
정렬 튜닝
- 목적: 지시사항 튜닝된 모델을 더욱 인간 또는 강력한 AI(예: GPT4 OpenAI (2023)) 선호도와 일치하도록 직접적인 선호도 최적화(DPO)로 Rafailov et al. (2023)의 방법을 이용하여 미세 조정.
- 데이터셋: 주로 오픈 소스 데이터셋 사용 및 지시사항 튜닝 단계에서 언급된 'Synth. Math-Instruct' 데이터셋을 활용하여 수학 중심의 정렬 데이터셋 합성.
- 데이터셋 합성 과정: 'Synth. Math-Instruct'의 재구성된 질문-답변 쌍이 수학 능력 강화에 유리하다는 점을 활용, 재구성된 답변을 선택된 응답으로, 원본 답변을 거부된 응답으로 사용하여 {프롬프트, 선택된 응답, 거부된 응답} DPO 튜플 생성, 이를 통합하여 'Synth. Math-Alignment' 데이터셋 구성.
평가 결과
- SOLAR 10.7B와 SOLAR 10.7B-Instruct, 그리고 다른 최고 성능 모델들의 평가 결과(Table 2 참조).
- 평가 지표: 6가지 작업(H6 평균 포함)의 점수와 모델 크기(억 단위 파라미터), 훈련 단계(Pretrained, Instruction-tuned, Alignment-tuned) 표시.
- SOLAR 10.7B 기반 모델은 보라색으로 표시, H6 및 개별 작업의 최고 점수는 굵은 글씨로 표시.
4. Experiments
4.1 Experimental Details
Training Datasets
- 주요 데이터셋: 지시사항 및 정렬 튜닝 단계에 사용된 데이터셋 상세 정보는 표 1에 제시.
- 데이터 샘플링: 전체 데이터셋을 항상 사용하는 것이 아니라, 일부만 샘플링하여 사용.
- 데이터 포맷: 지시사항 데이터셋은 Alpaca 스타일의 채팅 템플릿으로 재구성. OpenOrca(FLAN에서 유도)와 같은 데이터셋은 벤치마크 데이터셋과 중복되는 데이터 필터링.
- 정렬 데이터셋: {프롬프트, 선택된 응답, 거부된 응답} 트리플릿 형식으로 전처리.
평가
- HuggingFace Open LLM Leaderboard의 6가지 평가 방법 사용: ARC, HellaSWAG, MMLU, TruthfulQA, Winogrande, GSM8K.
- H6 점수(6가지 작업의 평균 점수) 보고.
모델 결합
- 모델 결합 방법(Yadav et al., 2023)을 통해 추가 훈련 없이 성능 향상 가능.
- 지시사항 및 정렬 튜닝 단계에서 훈련된 모델들을 결합하여 성능 향상을 시도.
4.2 Main Results
- SOLAR 10.7B는 유사한 크기의 다른 사전 훈련된 모델들(예: Qwen 14B, Mistral 7B)을 능가하여 DUS의 효과를 입증.
- SOLAR 10.7B-Instruct는 더 작은 크기에도 불구하고 H6에서 가장 높은 점수를 기록, 최신 최고 성능의 오픈 소스 LLM(예: Mixtral 8x7B-Instruct-v0.1, Qwen 72B)을 능가.
- SOLAR 10.7B-Instruct의 데이터 유출 결과는 부록 C에 보고됨.
4.3 Ablation Studies
지시사항 튜닝
- 다양한 지시사항 튜닝 훈련 데이터셋에 대한 소거 연구를 표 3에 제시.
- Alpaca-GPT4, OpenOrca, Synth. Math-Instruct 데이터셋 사용 여부에 따라 H6 점수와 개별 작업 점수의 변화 분석.
- 모델 결합을 통한 성능 향상 가능성 확인.
정렬 튜닝
- DPO 단계에서 사용된 다양한 정렬 훈련 데이터셋, SFT 기반 모델, 모델 결합 전략에 대한 소거 연구 제시.
- Ultrafeedback Clean과 Synth. Math-Alignment 데이터셋의 영향 분석.
- 서로 다른 SFT 기반 모델 사용 시 성능 차이 분석.
- 모델 결합 방법(예: 평균, SLERP)에 따른 성능 차이 분석 및 최종 모델 선택.
5. Conclusion
- SOLAR 10.7B 및 그의 미세 조정된 변형인 SOLAR 10.7B-Instruct 소개: 깊이 확장된(Depth Up-Scaled, DUS) 107억 파라미터를 가진 모델.
- 성능: Llama 2, Mistral 7B, Mixtral-7B-Instruct와 같은 모델들보다 주요 NLP 작업에서 우수한 성능을 보임.
- 효율성: 계산 효율성을 유지하면서 소규모 모델로부터 고성능 LLM을 확장하는 데 DUS가 효과적임을 입증.
- 향후 전망: 더 많은 탐색을 통해 DUS를 더욱 개선하고, 효율적으로 LLM을 확장하는 새로운 방향을 제시할 수 있음.
6. Insights
이 모델이 등장한 지 얼마 되지도 않았지만 벌써 OpenLLM 리더보드가 난리가 난 듯합니다..
모델을 학습하지 않고도 성능 향상이 가능하다고 알려졌는데요,
그래서 모델을 합치는 방법만 알면 위 이미지처럼 여러 버전의 모델들이 리더보드를 차지해버리는 상황도 나오나 봅니다..
(링크 참고: mergekit)
모델의 뛰어남을 리더보드를 통해 입증했는데, 그 덕분에 리더보드가 난리가 나버려서 신뢰성이 더욱 떨어진 것처럼 느껴지겠네요.
아무래도 여기에서의 포인트는 '학습하지 않고'일 것입니다...
논문에서도 모델을 합칠 때 단순 평균 방식과 SLERP 방식 중 더욱 효과적인 것을 비교했는데요, 결국 ensemble이라는 거..겠죠?
물론 그렇게 간단하지는 않은데 모델을 합치는 방식 자체가 결과에 직접적인 영향을 주지는 않았다고 밝힌 것을 보면..
그냥 다른 특성(장단점)을 지니는 모델을 병합하는 것이 주는 긍정적인 효과가 크다고 해석이 가능해 보이구요.
이미 진행 중이겠지만 이러한 방식을 사방팔방 온갖 도메인에서 적용하지 않을까.. 싶네요.
이게 정말 인공지능 모델의 발전 방향이 맞을까, 의문이 드는 상황입니다 🤔
출처 : https://arxiv.org/abs/2312.15166
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
We introduce SOLAR 10.7B, a large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. Inspired by recent efforts to efficiently up-scale LLMs, we present a method for sca
arxiv.org