
NLP 분야의 (지금은 분야를 막론하고 그렇지만) 전설적인 논문인 Attention Is All You Need를 읽고 간단히 정리해보았습니다.
100% 이해하는 것이 쉽지 않기도 하고.. 자세히 정리하다가는 하루가 꼬박 날아갈 가능성이 있어 핵심적인 개념들 위주로 정리하며 복습해볼 생각입니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Brain, Google Research, University of Toronto]
- 오직 attention mechanism만으로 구성된 simple network architecture, Transformer를 제안
- 영어를 다른 언어로 번역하는 태스크에서 뛰어난 일반화 성능을 보임
1 & 2. Introduction & Background
- 기존에 sequence modeling, machine translation 등의 분야에서는 RNN, LSTM, Gated RNN 등이 주류를 이루고 있었음
- sequential computation의 근본적인 한계가 존재
- Attention mechanism이 등장하며 sequence modeling에서 두각을 나타내었지만 RNN과 함께 사용되는 기조
- intra-attention이라고도 불리는 self-attention은 sequence 내 다른 position 요소 간 관계를 통해 representation을 계산
- 이 방식이 Transformer에 처음 적용된 것은 아니고, RNN과 같은 구조 없이 attention 메커니즘으로만 구성된 아키텍쳐는 최초였음
- 특히 Multi-Head Attention이라는 기법도 활용됨
- 본 연구에서는 input과 output 간의 global dependencies를 유지하면서도 적은 GPU 자원과 시간을 들여 학습할 수 있는 아키텍쳐를 제안함
2. Model Architecture
입력 시퀀스는 $x = (x_{1}, x_{2}, ... , x_{n})$, 이를 continuous representation으로 만든 것이 $z = (z_{1}, z_{2}, ... , z_{n})$, decoder가 만들어내는 output sequence를 $(y_{1}, y_{2}, ... y_{m})$으로 표기합니다.

3.1. Encoder and Decoder Stacks
Encoder
- $N = 6$개의 동일한 레이어가 쌓여 있는 형태로 구성됨
- 각 layer는 두 개의 sub-layer로 구성됨
- 첫 번째는 multi-head self-attention mechanism / 두 번째는 position-wise fully connected feed-forward network
- 두 sub-layer에 residual connection + layer normalization을 적용
- 이를 위해 embedding layer를 포함한 모델의 dimension은 512
Decoder
- $N = 6$개의 동일한 레이어가 쌓여 있는 형태로 구성됨
- encoder의 두 개 sub-layer + encoder stack의 output에 대한 multi-head attention까지 총 세 개의 sub-layer로 구성
- 마찬가지로 residual connection + layer normalization 적용
- decoder stack에 포함된 sub-layer의 self-attention은 현재 시점 이후의 position에 대해 attending 하지 못하도록 하게 되어 있음
3.2. Attention
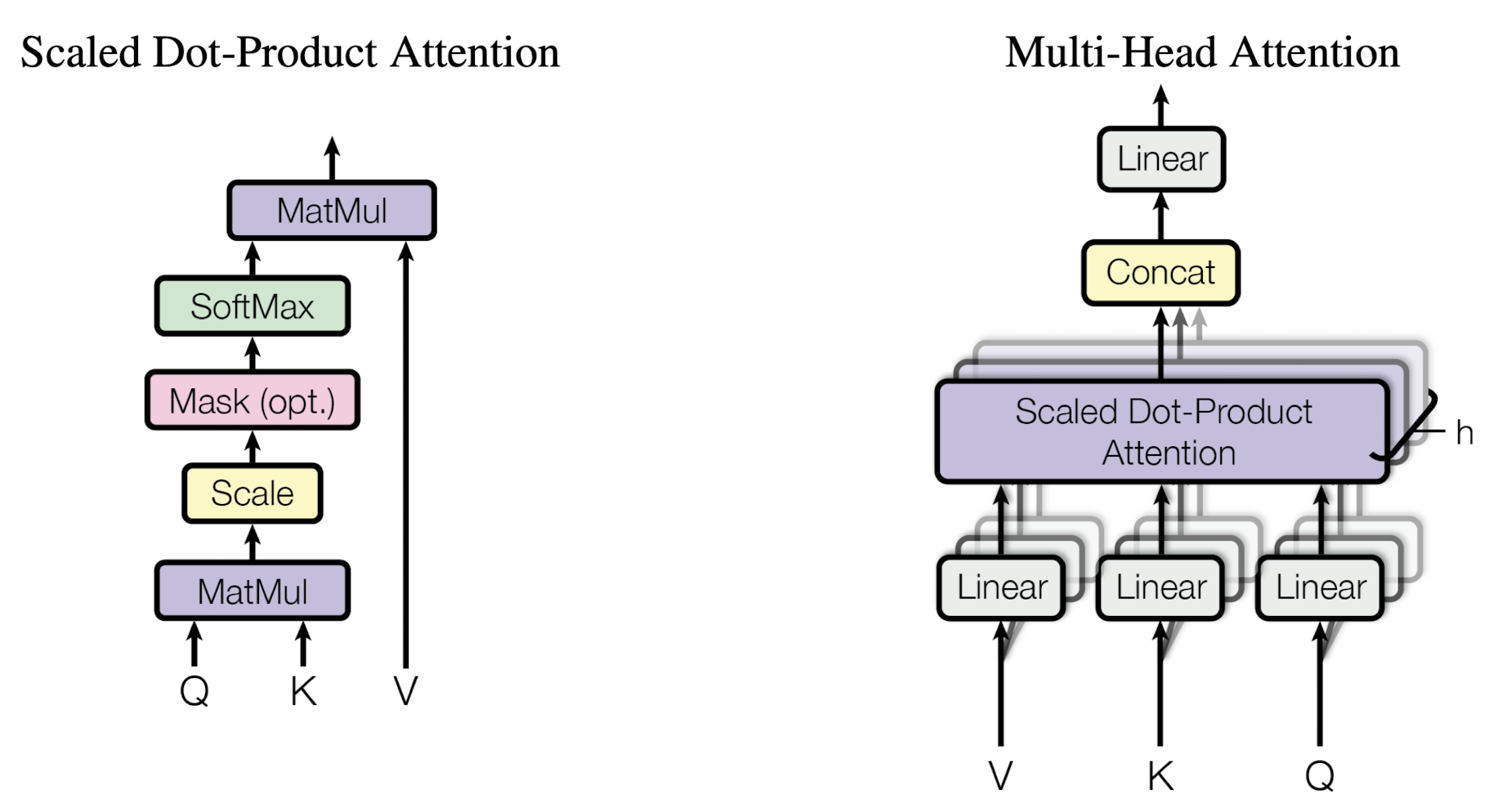
- query와 key의 내적을 통해 얻은 가중치와 value를 곱한 weighted sum이 output이 됨
- Scaled Dot-Product Attention
- query와 key의 내적 연산에 key 차원의 1/2승 만큼 나눠준다는 것을 제외하면 additive attention과 동일함
- 그러나 차원(dk)이 커짐에 따라서 softmax function이 너무나도 작은 gradient를 가질 가능성이 높아 $dk^{\frac {1}{2}}$로 나눠주는 것이 안정적이고 효율적인 연산 결과로 이어짐
- Multi-Head Attention
- query, key, value를 h번 다르게 linearly project
- project 되고 나면 concatenated
- $h = 8$로 설정하여 모델의 차원은 64가 됨 (총 8 * 64 = 512)
- Applications of Attention in our Model
- encoder-decoder attention: 이전 decoder layer로부터 query, encoder의 output으로부터 key, value →decoder가 input sequence의 모든 position에 attend하는 결과
- encoder의 self-attention: encoder 내 이전 layer의 output으로부터 query, key, value를 획득
- decoder의 self-attention: 시간 상 아직 등장하기 전의 토큰에 attend하지 못하도록 maksing (-∽)
- Position-wise Feed-Forward Networks
- encoder와 decoder 둘 다 fully connected feed-forward network를 포함
- 이는 두 개의 linear transformation과 ReLU activation으로 구성
- input & output 차원은 512이고, 내부 layer는 2048 차원임
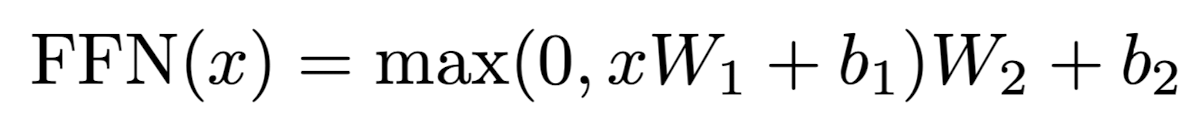
- Positional Encoding
- input embeddings에 relative / absolution position 정보를 반영할 수 있도록 positional encoding을 더함
- 모델의 dimension과 동일한 차원
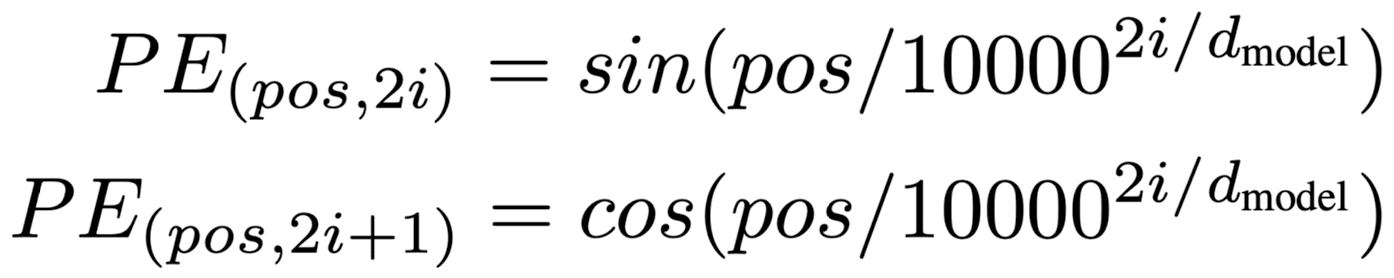
4. Why Self-Attention
- self-attention을 사용하는 이유는 크게 세 가지임
- layer 당 computational complexity가 낮음
- parallelize 할 수 있는 compuation의 amount가 큼
- network 내에서 long-range의 dependencies를 가짐

- 추가로 self-attention은 interpretable 하다는 특징을 지님
- 모델의 attention distribution을 살펴봄으로써 해석이 가능함
5. Training
- Dataset
- WMT 2014 English-German dataset: 4.5 million sentence pairs, byte-pair encoding, 37000 tokens
- WMT 2014 English-French dataset: 36M sentence pairs, 32000 word-piece vocab
- Hardward and Schedule
- 8 NVIDIA P100 GPUS
- 총 300,000 steps (3.5일)
- Optimizer
- Adam optimizer
- warmup_steps = 4000
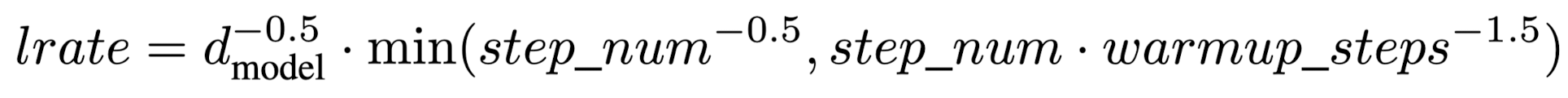
- Regularization
- Residual Dropout: 각 sub-layer의 output에 dropout을 적용. 추가로 encoder & decoder의 embedding 함에도 dropout을 적용 (0.1 비율)
- Label Smoothing: perplexity는 낮아지지만 더 높은 BLEU 스코어를 달성
6. Results
- Machine Translation
- WMT 2014 English-to-German 번역 태스크 & WMT 2014 English-to-French 번역 태스크에서 우수한 성능을 달성
- single model은 마지막 5개의 체크포인트를 평균함으로서 획득

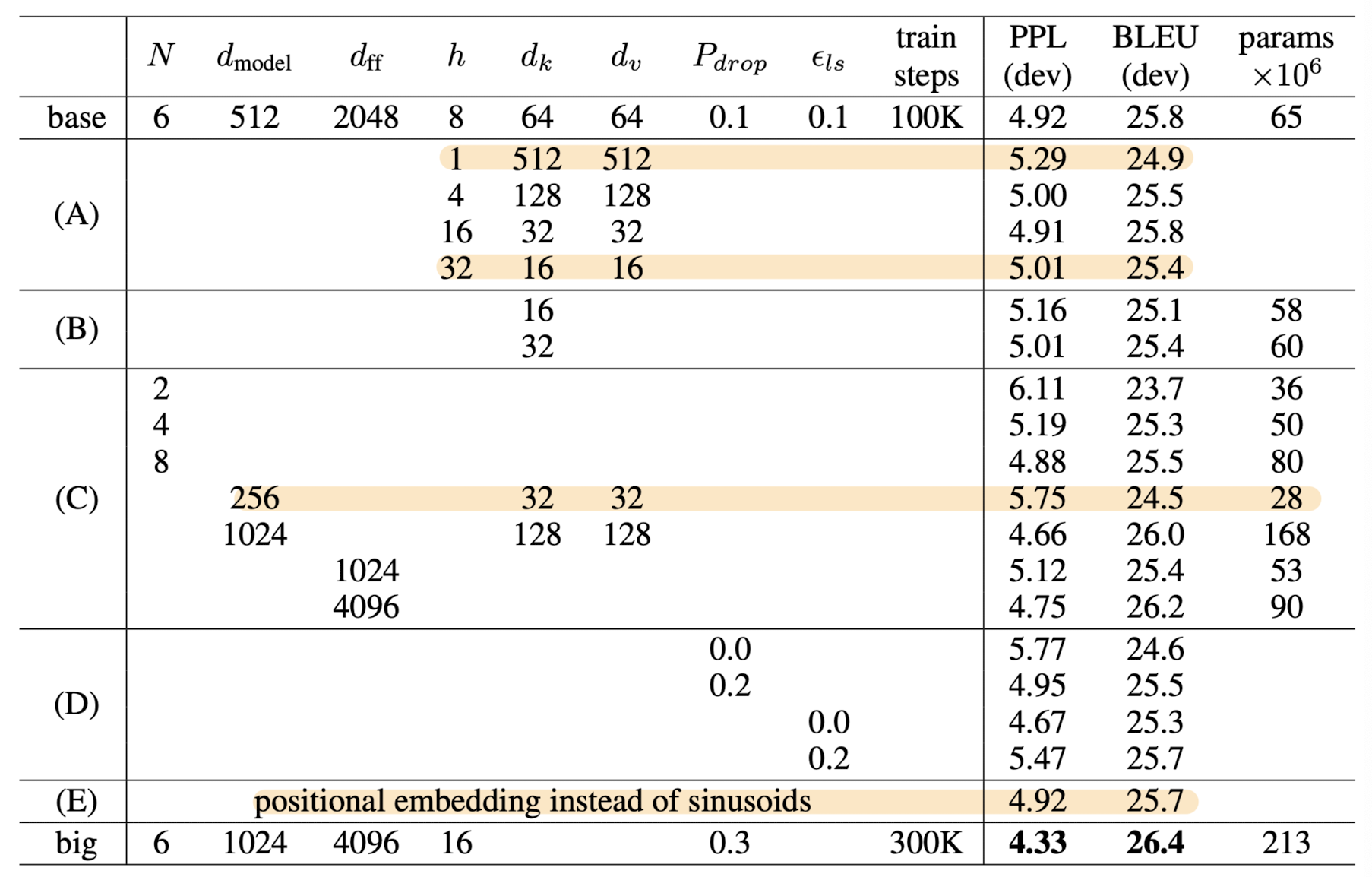
- Model Variations
- head의 개수도 적당해야 한다
- d_{k}를 줄이면 모델 성능 저하로 이어진다
- 모델의 사이즈가 커질수록 성능이 좋아진다
- dropout은 over-fitting을 방지하는데 도움을 준다
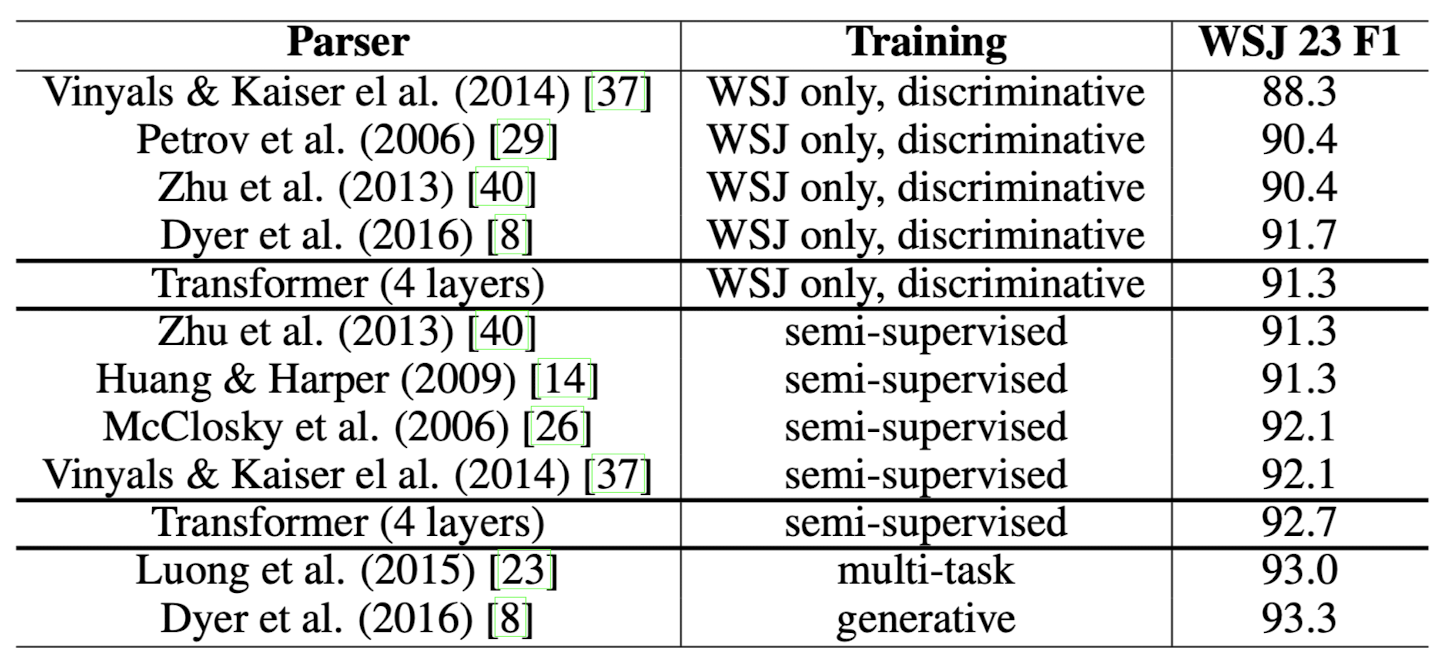
- English Constituency Parsing
6. Insights
사실 Transformer에 대해 모를 리가 있나.. 당연히 잘 알고 있지.. 라고 생각했는데 그마저도 착각이었다는 것을 최근에 알게 되었습니다.
너무나도 자주 쓰이고 입에 쉽게 오르내리다 보니 가볍고 친숙하게 다가왔나 봅니다..
조금 놀랐던 것은 self-attention입니다.
원래 self-attention이 그냥 attention과 다른 점이 무엇이냐, 라는 질문에 답하지 못했을 때도 놀라긴 했었지만 이러한 방식이 이미 많이 활용되고 있었다는 사실도 신기했습니다.
지금에 이르러서는 transformer 기반 모델들이 sequence 길이에 quadratic한 복잡도를 가지는 것이 상당한 문제지만..
당시에는 RNN, CNN 대비 효율적이었다는 것이 가장 이해하기 어려운 포인트인 것 같기도 하고요.
확실히 입력 길이와 모델 차원수 등을 계산해서 비교해볼 필요가 있는 것 같습니다.
트랜스포머하면 사전학습의 근간이라고 할 수도 있겠으나 첫 연구에서는 단 두 개의 번역 태스크만으로 성능을 평가했다는 점도 흥미로웠습니다.
출처 : https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
'Paper Review' 카테고리의 다른 글
NLP 분야의 (지금은 분야를 막론하고 그렇지만) 전설적인 논문인 Attention Is All You Need를 읽고 간단히 정리해보았습니다.
100% 이해하는 것이 쉽지 않기도 하고.. 자세히 정리하다가는 하루가 꼬박 날아갈 가능성이 있어 핵심적인 개념들 위주로 정리하며 복습해볼 생각입니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Brain, Google Research, University of Toronto]
- 오직 attention mechanism만으로 구성된 simple network architecture, Transformer를 제안
- 영어를 다른 언어로 번역하는 태스크에서 뛰어난 일반화 성능을 보임
1 & 2. Introduction & Background
- 기존에 sequence modeling, machine translation 등의 분야에서는 RNN, LSTM, Gated RNN 등이 주류를 이루고 있었음
- sequential computation의 근본적인 한계가 존재
- Attention mechanism이 등장하며 sequence modeling에서 두각을 나타내었지만 RNN과 함께 사용되는 기조
- intra-attention이라고도 불리는 self-attention은 sequence 내 다른 position 요소 간 관계를 통해 representation을 계산
- 이 방식이 Transformer에 처음 적용된 것은 아니고, RNN과 같은 구조 없이 attention 메커니즘으로만 구성된 아키텍쳐는 최초였음
- 특히 Multi-Head Attention이라는 기법도 활용됨
- 본 연구에서는 input과 output 간의 global dependencies를 유지하면서도 적은 GPU 자원과 시간을 들여 학습할 수 있는 아키텍쳐를 제안함
2. Model Architecture
입력 시퀀스는
3.1. Encoder and Decoder Stacks
Encoder
- 각 layer는 두 개의 sub-layer로 구성됨
- 첫 번째는 multi-head self-attention mechanism / 두 번째는 position-wise fully connected feed-forward network
- 두 sub-layer에 residual connection + layer normalization을 적용
- 이를 위해 embedding layer를 포함한 모델의 dimension은 512
Decoder
- encoder의 두 개 sub-layer + encoder stack의 output에 대한 multi-head attention까지 총 세 개의 sub-layer로 구성
- 마찬가지로 residual connection + layer normalization 적용
- decoder stack에 포함된 sub-layer의 self-attention은 현재 시점 이후의 position에 대해 attending 하지 못하도록 하게 되어 있음
3.2. Attention
- query와 key의 내적을 통해 얻은 가중치와 value를 곱한 weighted sum이 output이 됨
- Scaled Dot-Product Attention
- query와 key의 내적 연산에 key 차원의 1/2승 만큼 나눠준다는 것을 제외하면 additive attention과 동일함
- 그러나 차원(dk)이 커짐에 따라서 softmax function이 너무나도 작은 gradient를 가질 가능성이 높아
- Multi-Head Attention
- query, key, value를 h번 다르게 linearly project
- project 되고 나면 concatenated
- Applications of Attention in our Model
- encoder-decoder attention: 이전 decoder layer로부터 query, encoder의 output으로부터 key, value →decoder가 input sequence의 모든 position에 attend하는 결과
- encoder의 self-attention: encoder 내 이전 layer의 output으로부터 query, key, value를 획득
- decoder의 self-attention: 시간 상 아직 등장하기 전의 토큰에 attend하지 못하도록 maksing (-∽)
- Position-wise Feed-Forward Networks
- encoder와 decoder 둘 다 fully connected feed-forward network를 포함
- 이는 두 개의 linear transformation과 ReLU activation으로 구성
- input & output 차원은 512이고, 내부 layer는 2048 차원임
- Positional Encoding
- input embeddings에 relative / absolution position 정보를 반영할 수 있도록 positional encoding을 더함
- 모델의 dimension과 동일한 차원
4. Why Self-Attention
- self-attention을 사용하는 이유는 크게 세 가지임
- layer 당 computational complexity가 낮음
- parallelize 할 수 있는 compuation의 amount가 큼
- network 내에서 long-range의 dependencies를 가짐
- 추가로 self-attention은 interpretable 하다는 특징을 지님
- 모델의 attention distribution을 살펴봄으로써 해석이 가능함
5. Training
- Dataset
- WMT 2014 English-German dataset: 4.5 million sentence pairs, byte-pair encoding, 37000 tokens
- WMT 2014 English-French dataset: 36M sentence pairs, 32000 word-piece vocab
- Hardward and Schedule
- 8 NVIDIA P100 GPUS
- 총 300,000 steps (3.5일)
- Optimizer
- Adam optimizer
- warmup_steps = 4000
- Regularization
- Residual Dropout: 각 sub-layer의 output에 dropout을 적용. 추가로 encoder & decoder의 embedding 함에도 dropout을 적용 (0.1 비율)
- Label Smoothing: perplexity는 낮아지지만 더 높은 BLEU 스코어를 달성
6. Results
- Machine Translation
- WMT 2014 English-to-German 번역 태스크 & WMT 2014 English-to-French 번역 태스크에서 우수한 성능을 달성
- single model은 마지막 5개의 체크포인트를 평균함으로서 획득
- Model Variations
- head의 개수도 적당해야 한다
- d_{k}를 줄이면 모델 성능 저하로 이어진다
- 모델의 사이즈가 커질수록 성능이 좋아진다
- dropout은 over-fitting을 방지하는데 도움을 준다
- English Constituency Parsing
6. Insights
사실 Transformer에 대해 모를 리가 있나.. 당연히 잘 알고 있지.. 라고 생각했는데 그마저도 착각이었다는 것을 최근에 알게 되었습니다.
너무나도 자주 쓰이고 입에 쉽게 오르내리다 보니 가볍고 친숙하게 다가왔나 봅니다..
조금 놀랐던 것은 self-attention입니다.
원래 self-attention이 그냥 attention과 다른 점이 무엇이냐, 라는 질문에 답하지 못했을 때도 놀라긴 했었지만 이러한 방식이 이미 많이 활용되고 있었다는 사실도 신기했습니다.
지금에 이르러서는 transformer 기반 모델들이 sequence 길이에 quadratic한 복잡도를 가지는 것이 상당한 문제지만..
당시에는 RNN, CNN 대비 효율적이었다는 것이 가장 이해하기 어려운 포인트인 것 같기도 하고요.
확실히 입력 길이와 모델 차원수 등을 계산해서 비교해볼 필요가 있는 것 같습니다.
트랜스포머하면 사전학습의 근간이라고 할 수도 있겠으나 첫 연구에서는 단 두 개의 번역 태스크만으로 성능을 평가했다는 점도 흥미로웠습니다.
출처 : https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org