
관심있는 NLP 논문을 읽어보고 정리해보았습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[StatNLP Research Group]
- 약 1 trillion tokens을 3 epoch 동안 사전학습한 compact 1.1B 언어 모델
- 기존 open-source 언어 모델들(OPT-1.3B, Pythia-1.4B)을 능가하는 성능

1. Introduction
- 최근 NLP 분야는 언어 모델의 사이즈를 scaling up 하는 방식으로 빠르게 발전하고 있음
- 이에 따라 한정된 자원을 효율적으로 활용하여 최적의 모델 사이즈와 이에 할당해야 하는 학습 데이터의 양을 정하는 것이 중요한 이슈로 떠오르게 됨
- 초반에는 모델의 사이즈를 무식하게(?) 키우는 것이 곧 성능 향상으로 이어진다고 알려졌음
- 그러나 Chinchilla(https://arxiv.org/abs/2203.15556)와 같은 모델을 학습할 때, 사실은 모델의 capacity가 남아돈다는 것이 실험을 통해 확인됨. 즉, 동일 사이즈 모델에 대해 기존보다 더 많은 텍스트 데이터로 학습해야 효율이 더 좋다는 뜻
- 이후엔 scaling law를 통해 알려진 것보다도 더 많은 텍스트 데이터를 학습시키는 연구들도 나타나게 되었음. 이때 모델의 사이즈는 굉장히 작은(1B 수준) 편임
2. Pretraining
2.1 Pre-training data
- natural language data와 code 데이터를 적절히 혼합(7:3 비율)하여 사전 학습 데이터로 활용. 총 950 billion tokens
- SlimPajama
- 기존 1.2 trillion tokens에 달하는 RedPajama 데이터셋에 cleaning & deduplicating을 적용한 데이터셋
- Starcoderdata
- 86개의 프로그래밍 언어로 구성된 250 billion tokens 사이즈의 데이터셋
- 코드와 더불어 깃허브 issues, text-code pair 데이터도 포함되어 있음
- SlimPajama와의 중복을 피하기 위해서 SlimPajama에서 코드 관련 데이터를 제외했음
2.2 Architecture
- Transformer 기반의 decoder-only 모델인 Llama 2의 아키텍쳐를 채택

- Positional embedding: RoPE (Rotary Positional Embedding)
- RMSNorm: transformer sub-layer 마다 input 전에 normalize
- SwiGLU: Swish와 Gated Linear Unit을 합친 SwiGLU를 채택
- Grouped-query Attention: 32 heads for query attention, 4 gropus of key-value heads
2.3 Speed Optimizations
- Fully Sharded Data Paraellel (FSDP)
- Flash Attention 2
- xFormers: xFormers의 SwiGLU 모듈을 original SwiGLU 모듈과 융합. 덕분에 1.1 model을 40GB GPU RAM에 fit
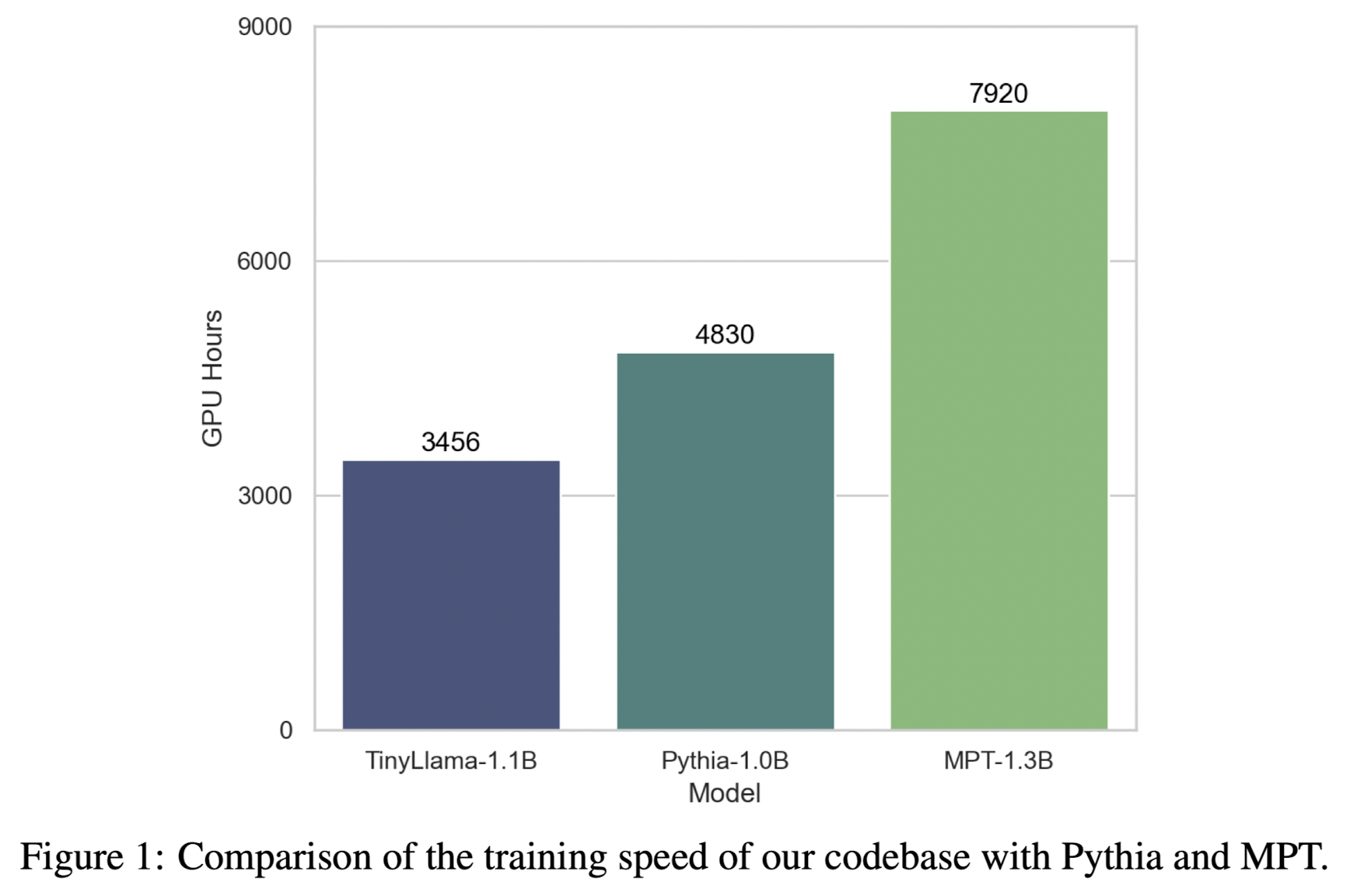
- Performance Analysis and Comparison with Other Models
- A100-40G GPU에서 초당 24,000 토큰 처리 가능
- 300B 토큰에 대해 3,456 A100 GPU hours 필요
2.4 Training
- lit-gpt
- AdamW optimizer
- 2,000 warmup steps
- gradient clipping: 1.0
- weight decay: 0.1
- 2M tokens batch size
- 16 A100-40G GPUs
3. Results
Baseline models
- OPT-1.3B, Pythia-1.0B, Pythia-1.4B
Commonsense reasoning tasks
- Language Model Evaluation Harness framework를 사용
- zero-shot 세팅에서 평가

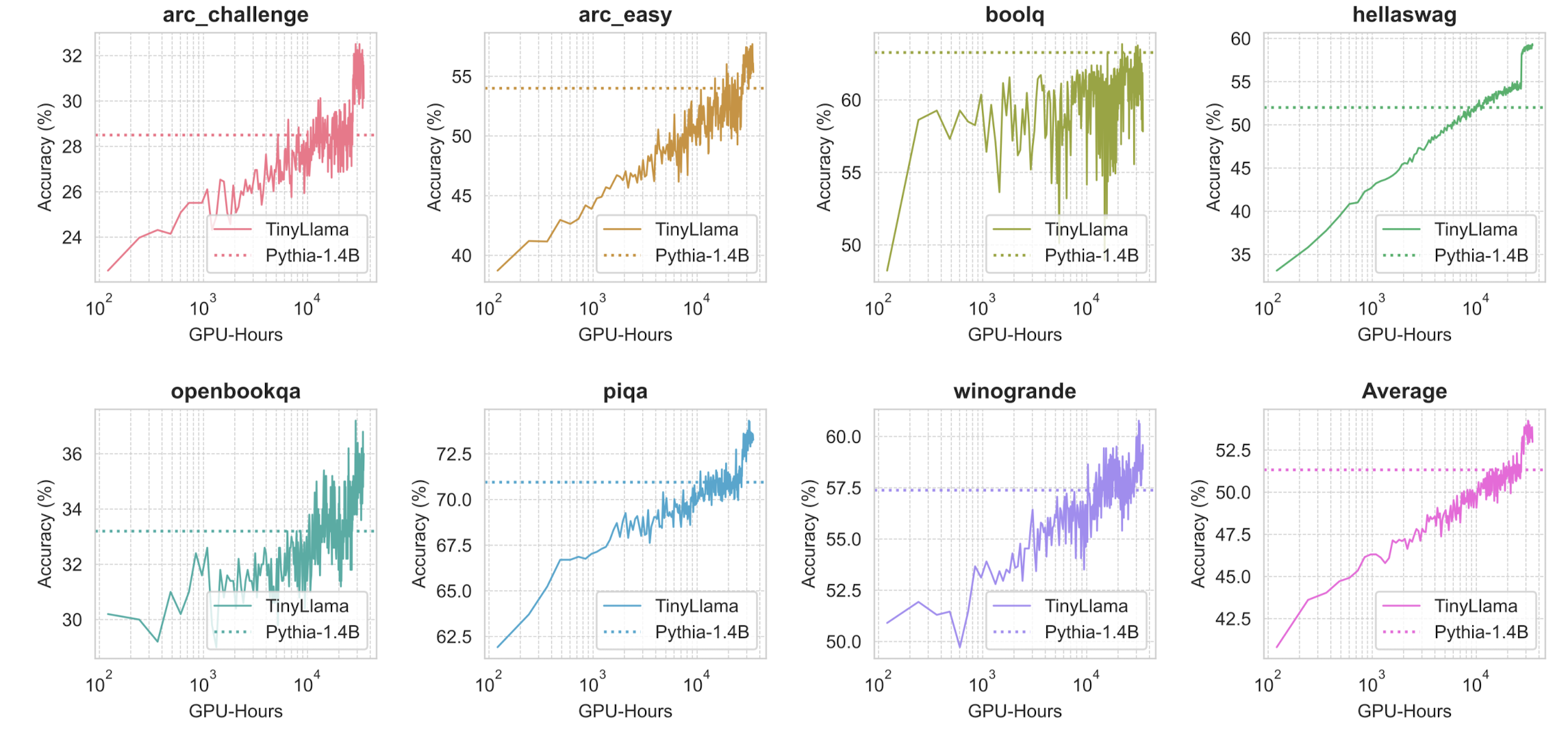
Evolution of performance during training
Problem-solving evaluation

4. Insights
개인적으로는 이거 학습한 거 뭐 어쩌라고...? 싶은 느낌이 많이 드는 논문이었습니다.
사실 빠져있는 요소도 굉장히 많고, 모델만 공개하기엔 좀 애매해서 학습한 스펙을 공개한 Technical Report의 일부같은 느낌..
요즘에는 on-device 형태로 활용 가능한 모델을 개발하는 것도 활발한 연구 분야 중 하나로 알고 있는데요,
연구에서 보여주고자 한 것이 작은 모델의 general한 능력인가 싶어 의문이 들기도 했습니다.
정리하자면,
1. 작은 언어 모델(sLLM)도 in-context learning 능력을 획득할 수 있다, 즉 'generalization이 가능하다'는 것을 보여주고 싶었다면 그 방향성 자체가 잘못된 것이 아닐까 싶습니다.
마지막 실험 결과인 problem-solving evaluation을 확인해보면 오히려 code 관련 평가(HumanEval)에서 좋은 결과를 거둔 것을 알 수 있습니다.
처음부터 특정 태스크나 도메인 특화로 보고 연구를 진행했으면 더 좋았을 것 같습니다.
2. 모델 사이즈를 scaling하면서 실험을 진행했어야 된다고 생각합니다.
1.1B 사이즈의 모델을 학습시킨 것으로 밝혔는데, 이러한 학습 전략(더 많은 데이터로 동일 사이즈 모델 학습)이 유효한 것인지는 타모델과의 비교가 아닌 자체적인 비교를 통해 확인했어야 합니다.
특히 ablation study 자체가 없어서 놀라웠습니다.
출처 : https://arxiv.org/abs/2401.02385
TinyLlama: An Open-Source Small Language Model
We present TinyLlama, a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 정리해보았습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[StatNLP Research Group]
- 약 1 trillion tokens을 3 epoch 동안 사전학습한 compact 1.1B 언어 모델
- 기존 open-source 언어 모델들(OPT-1.3B, Pythia-1.4B)을 능가하는 성능
1. Introduction
- 최근 NLP 분야는 언어 모델의 사이즈를 scaling up 하는 방식으로 빠르게 발전하고 있음
- 이에 따라 한정된 자원을 효율적으로 활용하여 최적의 모델 사이즈와 이에 할당해야 하는 학습 데이터의 양을 정하는 것이 중요한 이슈로 떠오르게 됨
- 초반에는 모델의 사이즈를 무식하게(?) 키우는 것이 곧 성능 향상으로 이어진다고 알려졌음
- 그러나 Chinchilla(https://arxiv.org/abs/2203.15556)와 같은 모델을 학습할 때, 사실은 모델의 capacity가 남아돈다는 것이 실험을 통해 확인됨. 즉, 동일 사이즈 모델에 대해 기존보다 더 많은 텍스트 데이터로 학습해야 효율이 더 좋다는 뜻
- 이후엔 scaling law를 통해 알려진 것보다도 더 많은 텍스트 데이터를 학습시키는 연구들도 나타나게 되었음. 이때 모델의 사이즈는 굉장히 작은(1B 수준) 편임
2. Pretraining
2.1 Pre-training data
- natural language data와 code 데이터를 적절히 혼합(7:3 비율)하여 사전 학습 데이터로 활용. 총 950 billion tokens
- SlimPajama
- 기존 1.2 trillion tokens에 달하는 RedPajama 데이터셋에 cleaning & deduplicating을 적용한 데이터셋
- Starcoderdata
- 86개의 프로그래밍 언어로 구성된 250 billion tokens 사이즈의 데이터셋
- 코드와 더불어 깃허브 issues, text-code pair 데이터도 포함되어 있음
- SlimPajama와의 중복을 피하기 위해서 SlimPajama에서 코드 관련 데이터를 제외했음
2.2 Architecture
- Transformer 기반의 decoder-only 모델인 Llama 2의 아키텍쳐를 채택
- Positional embedding: RoPE (Rotary Positional Embedding)
- RMSNorm: transformer sub-layer 마다 input 전에 normalize
- SwiGLU: Swish와 Gated Linear Unit을 합친 SwiGLU를 채택
- Grouped-query Attention: 32 heads for query attention, 4 gropus of key-value heads
2.3 Speed Optimizations
- Fully Sharded Data Paraellel (FSDP)
- Flash Attention 2
- xFormers: xFormers의 SwiGLU 모듈을 original SwiGLU 모듈과 융합. 덕분에 1.1 model을 40GB GPU RAM에 fit
- Performance Analysis and Comparison with Other Models
- A100-40G GPU에서 초당 24,000 토큰 처리 가능
- 300B 토큰에 대해 3,456 A100 GPU hours 필요
2.4 Training
- lit-gpt
- AdamW optimizer
- 2,000 warmup steps
- gradient clipping: 1.0
- weight decay: 0.1
- 2M tokens batch size
- 16 A100-40G GPUs
3. Results
Baseline models
- OPT-1.3B, Pythia-1.0B, Pythia-1.4B
Commonsense reasoning tasks
- Language Model Evaluation Harness framework를 사용
- zero-shot 세팅에서 평가
Evolution of performance during training
Problem-solving evaluation
4. Insights
개인적으로는 이거 학습한 거 뭐 어쩌라고...? 싶은 느낌이 많이 드는 논문이었습니다.
사실 빠져있는 요소도 굉장히 많고, 모델만 공개하기엔 좀 애매해서 학습한 스펙을 공개한 Technical Report의 일부같은 느낌..
요즘에는 on-device 형태로 활용 가능한 모델을 개발하는 것도 활발한 연구 분야 중 하나로 알고 있는데요,
연구에서 보여주고자 한 것이 작은 모델의 general한 능력인가 싶어 의문이 들기도 했습니다.
정리하자면,
1. 작은 언어 모델(sLLM)도 in-context learning 능력을 획득할 수 있다, 즉 'generalization이 가능하다'는 것을 보여주고 싶었다면 그 방향성 자체가 잘못된 것이 아닐까 싶습니다.
마지막 실험 결과인 problem-solving evaluation을 확인해보면 오히려 code 관련 평가(HumanEval)에서 좋은 결과를 거둔 것을 알 수 있습니다.
처음부터 특정 태스크나 도메인 특화로 보고 연구를 진행했으면 더 좋았을 것 같습니다.
2. 모델 사이즈를 scaling하면서 실험을 진행했어야 된다고 생각합니다.
1.1B 사이즈의 모델을 학습시킨 것으로 밝혔는데, 이러한 학습 전략(더 많은 데이터로 동일 사이즈 모델 학습)이 유효한 것인지는 타모델과의 비교가 아닌 자체적인 비교를 통해 확인했어야 합니다.
특히 ablation study 자체가 없어서 놀라웠습니다.
출처 : https://arxiv.org/abs/2401.02385
TinyLlama: An Open-Source Small Language Model
We present TinyLlama, a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g
arxiv.org