
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Tencent AI Lab]
- 여러 LLM들의 능력을 single LLM으로 전이하는 방법론을 제시
- Llama-2, MPT, OpenLLaMA, 세 모델을 사용
- source LLM들의 생성 확률 분포를 기반으로 fusion
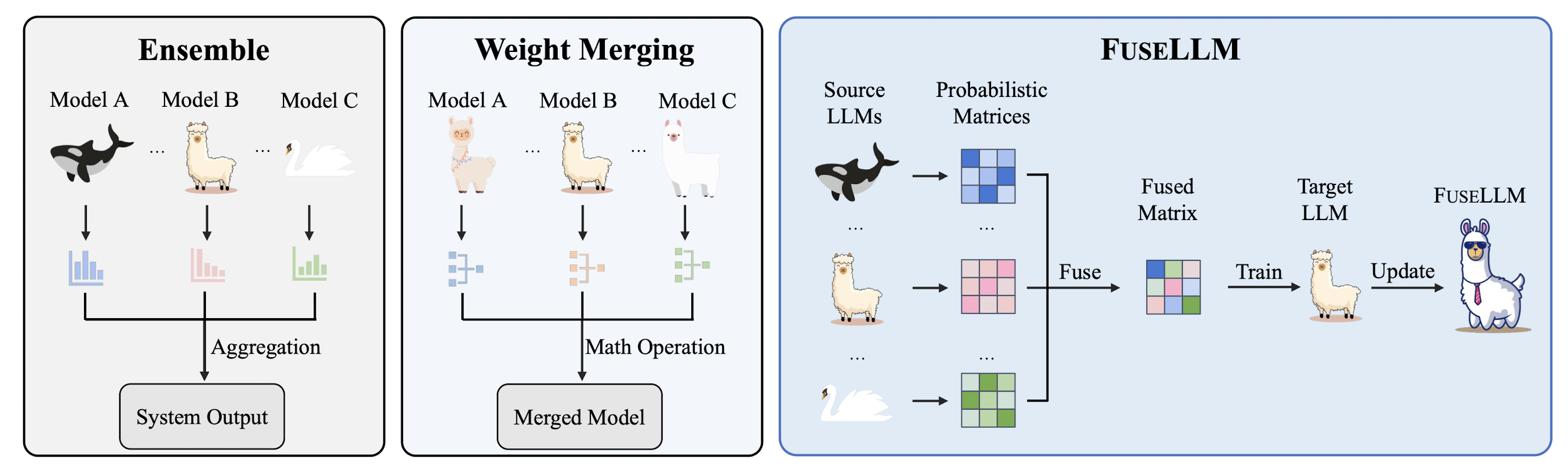
1. Introduction
LLaMA, GPT와 같은 모델을 직접 학습하는 것은 천문학적인 비용을 초래하며 환경 문제에까지 큰 영향을 준다는 것이 잘 알려져있습니다.
그래서 모델을 직접 학습하지 않고 기존 모델들의 지식을 활용하는 방법론들이 다양하게 제시되고 있습니다.
본 논문에서는 knowledge fusion of LLMs를 제시하고 있습니다.
위 그림에서 볼 수 있는 것처럼 기존에는 Ensemble, Weight Merging과 같은 방식들이 사용되고 있었습니다.
그러나 전자의 경우 하나의 output을 만들어내기 위해 여러 개의 모델이 실시간으로 추론을 진행해야 하므로 memory 및 infernece time issue를 피해갈 수 없었고, 후자의 경우 모델의 아키텍쳐가 동일하지 않으면 적용하기 어렵다는 문제점이 있었습니다.
FuseLLM의 경우 모델이 특정 토큰에 대해 갖는 확률 분포를 통합(fusion)하는 방식으로 모델의 아키텍쳐에 상관 없이 적용할 수 있는 방법론이면서도, 하나의 target model을 학습시키는 방식이라서 latency가 높지 않다는 장점을 가집니다.
2. Related Work
Model Fusion
가장 전통적으로는 모델들의 output을 합치는 ensemble 방식이 있습니다.
이는 크게 weighted averaging과 majority voting으로 구분됩니다.
이러한 방식은 여러 open-source LLMs에 대해서도 적용 가능합니다.
weight merging같은 경우 parameter level에서 모델을 fusion 하는 방식을 이릅니다.
이때 동일한 모델에 대해 다른 학습 전략을 취하거나 configurations를 변경할 수 있습니다.
위에서 언급한 것처럼 ensemble 방식은 parallel deployment of multiple models 문제를, weight merging 방식은 limited to models with identical architectures 문제를 갖고 있습니다.
Knowledge Distillation
모델 압축 기법으로 제시되었던 knowledge distillation은 처음 NLP 분야에 도입되었을 때는 분류 문제에 적용되었습니다.
지금에 이르러서는 teacher 모델과 student 모델 간의 generation distribution의 KL divergence를 줄이는 방식이 정석으로 자리 잡았습니다.
일반적으로는 student 모델의 사이즈가 teacher 모델 대비 훨씬 작아야하고, 또 teacher 모델의 성능을 넘어설 수 없다는 것이 knowledge distillation 방식의 한계이지만, 본 연구에서는 student 모델의 사이즈에 제한을 두지 않아도 되고 기존 source model의 성능을 넘어설 수 있는 방식을 제안한 것이라고 주장합니다.
3. Knowledge Fusion of LLMs
LLMs fusion의 가장 주된 목표는 여러 source LLMs에 내재된 지식을 externalize하는 것입니다.
이를 위해서 각 LLM들이 특정 텍스트에 대해 어떤 확률 분포를 갖는지를 출력하도록 만듭니다.
여기에 사용되는 모델의 notation은 $\{M^{s}_{j}\}^{K}_{j=1}$로 표현됩니다.
- causal language modeling (CLM)의 objective는 다음과 같습니다.
- $L_{CLM}=-\mathbb{E}_{t \sim C}\left [ \sum_{i} \log p_{\theta}(t_{i}|t_{<i}) \right ] $
- 위 sequence 수준의 likelihood를 token-level로 decompose한 식은 아래와 같습니다.
- 이때는 sequential distribution format으로 바꿔야 하는데 $\mathbb{R}^{N \times V}$의 행렬로 표현됩니다.
- 여기서 $V$는 vocab size를 뜻합니다. 정답의 경우 one-hot label matrix, $O_{t} \in \{0,1\}^{N \times V}$가 됩니다.
- 결과적으로 $L_{CLM}=-\mathbb{E}_{t \sim C} \left [ \mathbb{D}(P^{\theta}_{t},O_{t}) \right ]$로 이해할 수 있고 KL divergence를 최소화하는 objective가 됩니다.
- LLMs Fusion
- 모델을 합치기 이전에는 lightweight continual training을 진행해야 합니다. 이때 pre-training dataset을 반영하는 raw text corpus를 사용했다고 언급되어 있는데 자세한 내용은 나와있지 않습니다.
- 실제 실험은 위 continual training까지 적용한 것과, 이후 fusion을 수행한 것 두 가지를 나눠서 비교합니다.
- K개의 source 모델에 대한 확률 분포를 구하고 이를 Fusion하게 되면 Fusion에 대한 loss 역시 다음과 같은 식으로 정리됩니다.
- $L_{Fusion}=-\mathbb{E}_{t \sim C} \left [ \mathbb{D}(Q_{t},P_{t}) \right ]$
- 결과적으로는 CLM 수식과 합쳐져 $L=\lambda L_{CLM}+(1- \lambda)L_{Fusion}$으로 objective가 정리됩니다.
- Token Alignment
- 실험에 사용된 세 개의 LLM들은 서로 다른 vocab을 갖고 있으므로 이를 일치시키는 작업이 필요합니다. 토큰에 대한 확률 분포를 구하더라도 다른 의미를 지니게 되기 때문입니다.
- 기존에 사용되던 EM (Exact Match) constraint를 MinED (Minimum Edit Distance)로 대체했다고 합니다.
- Fusion Strategies
- 위 내용을 하나로 합치게 되면, 각 source LLM이 갖는 확률 분포를 구하고, MinED를 통해 토큰 간 align을 진행한 뒤, MinCE 또는 AvgCE를 적용하여 Fuse를 진행합니다. 알고리즘은 다음과 같습니다.

4. Experiments
Setup
- Dataset for continual trainnig: MiniPile 데이터셋을 사용합니다.
- Fusion function: minimum cross-entropy (MinCE)를 사용합니다.
- 8 NVIDIA A100 GPUs (40GB), FlashAttention, HuggingFace Transformers
- Evaluation
- Big-Bench Hard (BBH): few-shot chain-of-thought (CoT) prompts, exact match (EM) accuracy
- Common Sense (CS): likelihood-based zero-shot evaluation, accuracy
- MultiPL-E (ME): zero-shot code generation, pass@1
- Baselines
- original LLMs: Llama-2 7B, OpenLLaMA 7B, MPT 7B
- Llama-2 CLM
Results
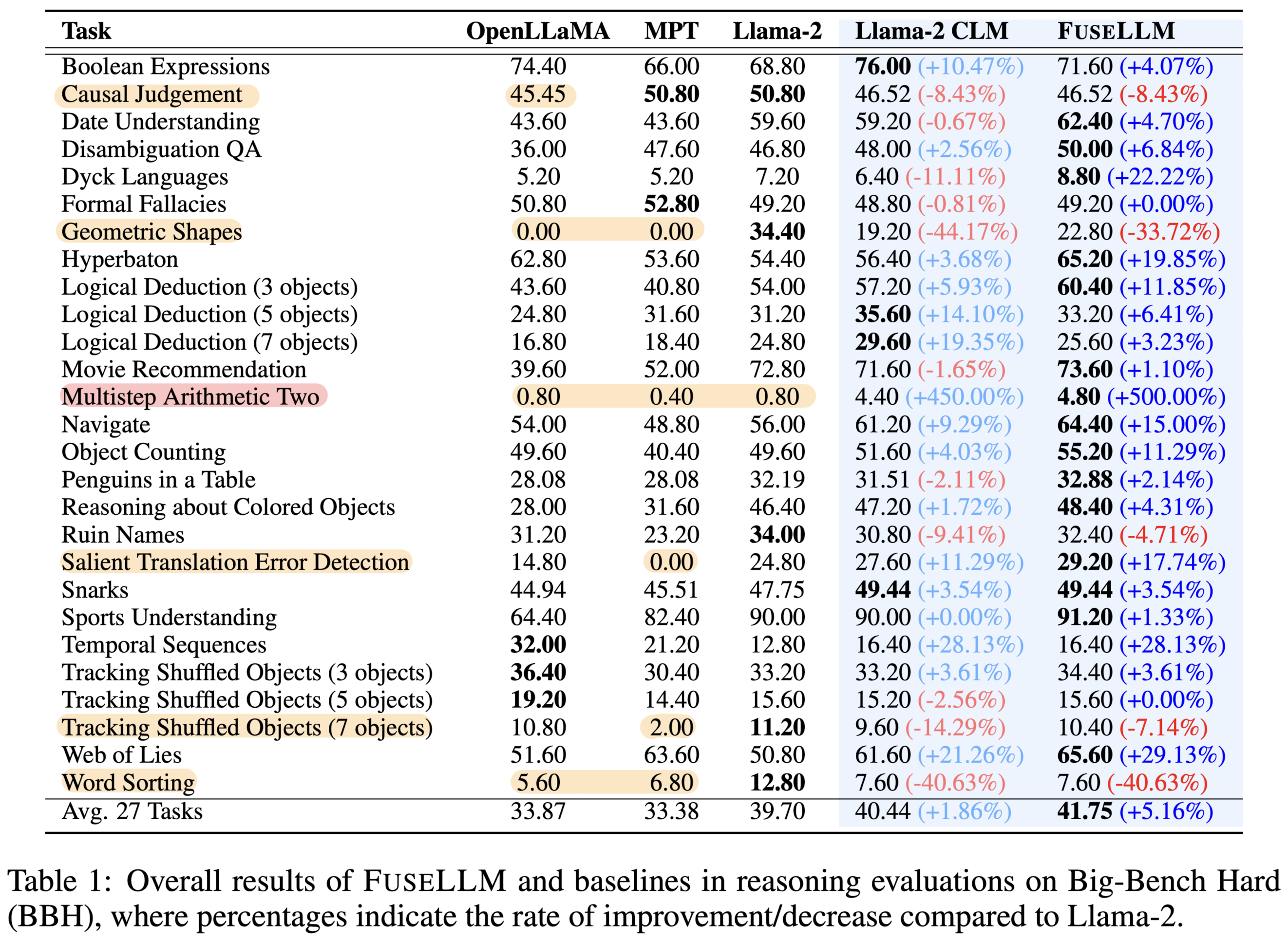
BBH에 대한 결과를 정리한 표입니다.
일반적으로는 CLM 만으로도 성능이 향상되기도 하고, 특히 FuseLLM은 전반적으로 기존 모델들 대비 뛰어난 성능을 보인다는 것을 알 수 있습니다.
다만, backbone이 되는 모델 Llama-2가 약세를 보이거나, 그 외 두 개의 모델이 약세를 보이는 경우 FuseLLM 또한 좋은 성능을 발휘하지 못한다는 것이 특징입니다.
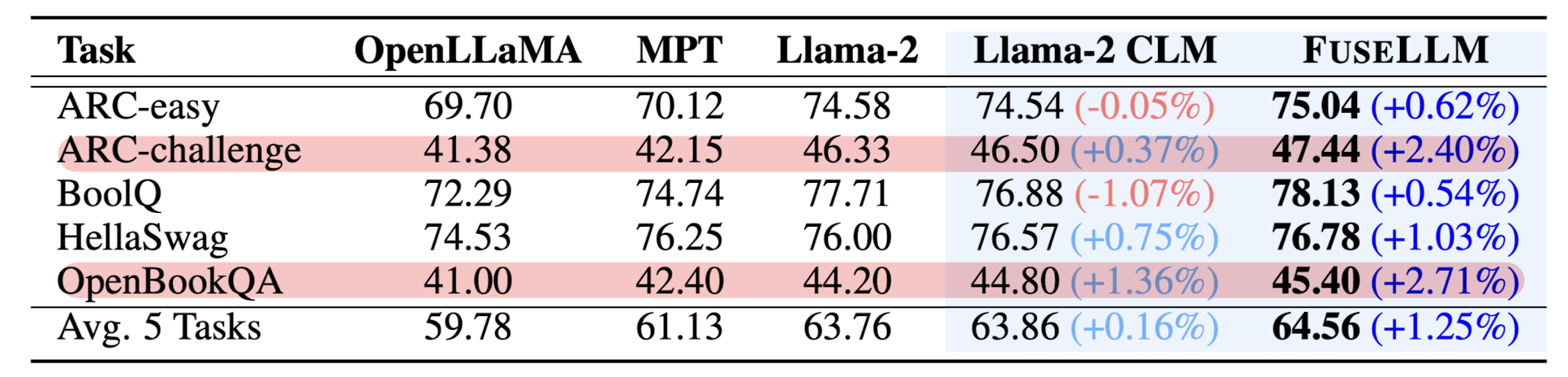
BBH에서 언급한 특징과 엮어서 생각해본다면, 결국 기본 모델들도 어느 정도는 적당한 구색을 갖춘 수준은 되어야 FuseLLM이 의미 있는 성능 향상을 이뤄낼 수 있다고 볼 수 있겠습니다.
즉, 너무 못하는 것들만 모아 놓고 어떤 결과가 좋아지길 바라는 것은 무리라는 뜻입니다.
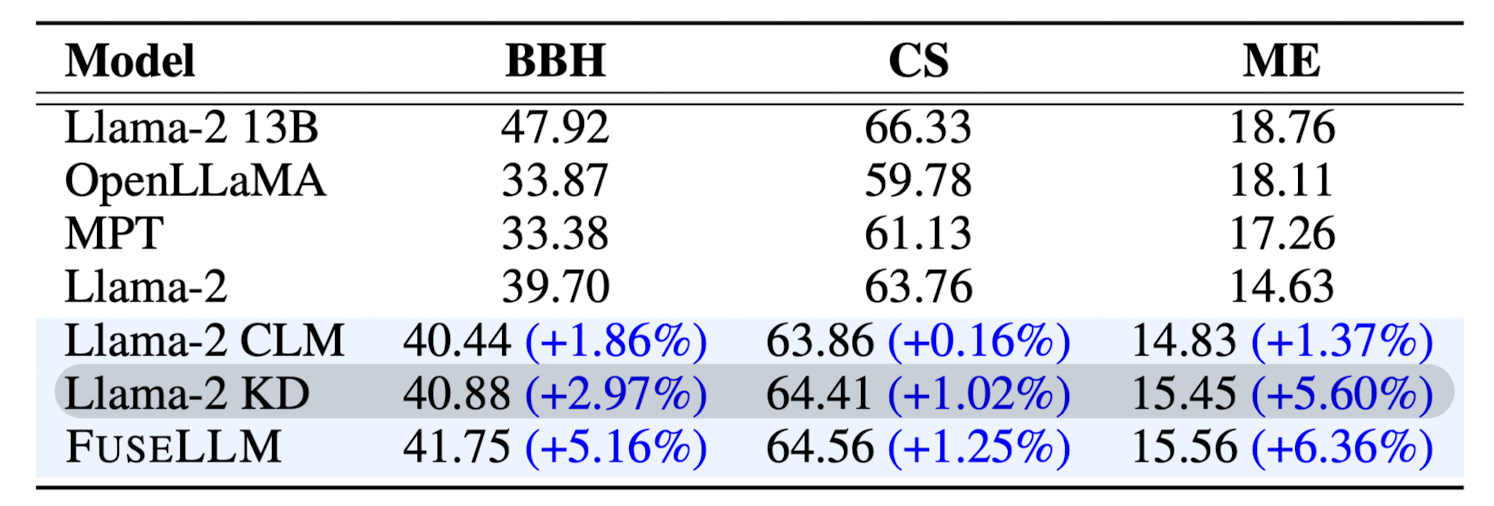
Llama-2 13B 모델을 teacher 모델로 삼아 Knowledge Distillation 했을 때의 결과와 비교한 것입니다.
FuseLLM이 이보다도 더 좋은 결과를 달성했다는 것은, 작은 모델들만을 사용하는 방법론이 충분히 활용될 가능성이 있다는 것을 시사하는 것으로 보입니다.
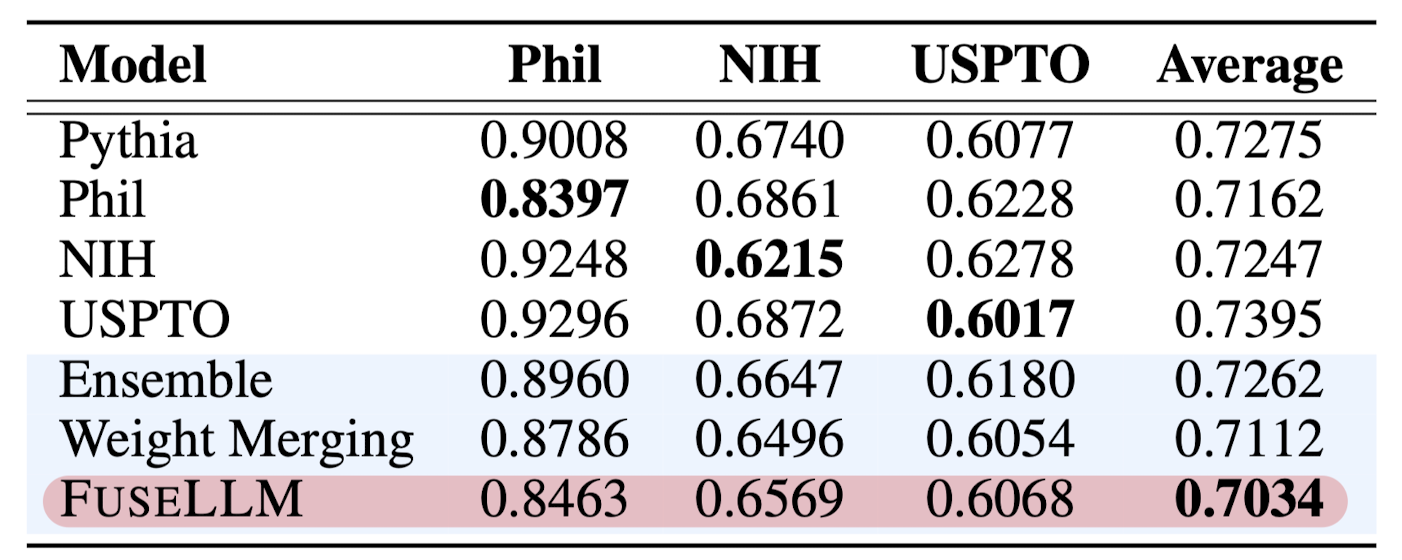
또한 공개된 다른 open-source 모델들로 기존의 Ensemble, Weight Merging 방식을 비교한 결과입니다.
처음 논문의 주장대로 기존의 모델 fusion 방식보다 뛰어난 결과가 나타났다는 것을 알 수 있습니다.
5. Insights
요즘 모델을 합치는 방식에 대한 연구들이 꽤나 많은 것 같습니다.
단순 앙상블이라고 보기에는 어려운.. 그래도 나름 정교한 것 같은..?
LLM이 갖고 있는 치명적인 문제 중 하나가 높은 latency이기 때문에 이를 최소화하면서, 혹은 높이지 않으면서도 좋은 성능을 낼 수 있는 방법을 고민하는 것이 좋은 것 같습니다.
이럴 때는 학습할 데이터를 잘 만들어내는 게 방법이 될 수 있겠죠.
위에서 언급된 바와 같이 여러 모델을 추론 시에 동시에 활용하면 메모리 문제도 있고..
그 모델들의 출력 결과가 확률 분포를 곧 의미하게 되므로, 내재된 능력 등을 externalize한다는 접근이 굉장히 좋은 것 같습니다.
이러한 방법을 다른 곳들에도 접목시킬 수 있다면 좋을 것 같네요.
출처 : https://arxiv.org/abs/2401.10491
Knowledge Fusion of Large Language Models
While training large language models (LLMs) from scratch can generate models with distinct functionalities and strengths, it comes at significant costs and may result in redundant capabilities. Alternatively, a cost-effective and compelling approach is to
arxiv.org
'Paper Review' 카테고리의 다른 글
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Tencent AI Lab]
- 여러 LLM들의 능력을 single LLM으로 전이하는 방법론을 제시
- Llama-2, MPT, OpenLLaMA, 세 모델을 사용
- source LLM들의 생성 확률 분포를 기반으로 fusion
1. Introduction
LLaMA, GPT와 같은 모델을 직접 학습하는 것은 천문학적인 비용을 초래하며 환경 문제에까지 큰 영향을 준다는 것이 잘 알려져있습니다.
그래서 모델을 직접 학습하지 않고 기존 모델들의 지식을 활용하는 방법론들이 다양하게 제시되고 있습니다.
본 논문에서는 knowledge fusion of LLMs를 제시하고 있습니다.
위 그림에서 볼 수 있는 것처럼 기존에는 Ensemble, Weight Merging과 같은 방식들이 사용되고 있었습니다.
그러나 전자의 경우 하나의 output을 만들어내기 위해 여러 개의 모델이 실시간으로 추론을 진행해야 하므로 memory 및 infernece time issue를 피해갈 수 없었고, 후자의 경우 모델의 아키텍쳐가 동일하지 않으면 적용하기 어렵다는 문제점이 있었습니다.
FuseLLM의 경우 모델이 특정 토큰에 대해 갖는 확률 분포를 통합(fusion)하는 방식으로 모델의 아키텍쳐에 상관 없이 적용할 수 있는 방법론이면서도, 하나의 target model을 학습시키는 방식이라서 latency가 높지 않다는 장점을 가집니다.
2. Related Work
Model Fusion
가장 전통적으로는 모델들의 output을 합치는 ensemble 방식이 있습니다.
이는 크게 weighted averaging과 majority voting으로 구분됩니다.
이러한 방식은 여러 open-source LLMs에 대해서도 적용 가능합니다.
weight merging같은 경우 parameter level에서 모델을 fusion 하는 방식을 이릅니다.
이때 동일한 모델에 대해 다른 학습 전략을 취하거나 configurations를 변경할 수 있습니다.
위에서 언급한 것처럼 ensemble 방식은 parallel deployment of multiple models 문제를, weight merging 방식은 limited to models with identical architectures 문제를 갖고 있습니다.
Knowledge Distillation
모델 압축 기법으로 제시되었던 knowledge distillation은 처음 NLP 분야에 도입되었을 때는 분류 문제에 적용되었습니다.
지금에 이르러서는 teacher 모델과 student 모델 간의 generation distribution의 KL divergence를 줄이는 방식이 정석으로 자리 잡았습니다.
일반적으로는 student 모델의 사이즈가 teacher 모델 대비 훨씬 작아야하고, 또 teacher 모델의 성능을 넘어설 수 없다는 것이 knowledge distillation 방식의 한계이지만, 본 연구에서는 student 모델의 사이즈에 제한을 두지 않아도 되고 기존 source model의 성능을 넘어설 수 있는 방식을 제안한 것이라고 주장합니다.
3. Knowledge Fusion of LLMs
LLMs fusion의 가장 주된 목표는 여러 source LLMs에 내재된 지식을 externalize하는 것입니다.
이를 위해서 각 LLM들이 특정 텍스트에 대해 어떤 확률 분포를 갖는지를 출력하도록 만듭니다.
여기에 사용되는 모델의 notation은
- causal language modeling (CLM)의 objective는 다음과 같습니다.
- 위 sequence 수준의 likelihood를 token-level로 decompose한 식은 아래와 같습니다.
- 이때는 sequential distribution format으로 바꿔야 하는데
- 여기서
- 결과적으로
- 이때는 sequential distribution format으로 바꿔야 하는데
- LLMs Fusion
- 모델을 합치기 이전에는 lightweight continual training을 진행해야 합니다. 이때 pre-training dataset을 반영하는 raw text corpus를 사용했다고 언급되어 있는데 자세한 내용은 나와있지 않습니다.
- 실제 실험은 위 continual training까지 적용한 것과, 이후 fusion을 수행한 것 두 가지를 나눠서 비교합니다.
- K개의 source 모델에 대한 확률 분포를 구하고 이를 Fusion하게 되면 Fusion에 대한 loss 역시 다음과 같은 식으로 정리됩니다.
- 결과적으로는 CLM 수식과 합쳐져
- Token Alignment
- 실험에 사용된 세 개의 LLM들은 서로 다른 vocab을 갖고 있으므로 이를 일치시키는 작업이 필요합니다. 토큰에 대한 확률 분포를 구하더라도 다른 의미를 지니게 되기 때문입니다.
- 기존에 사용되던 EM (Exact Match) constraint를 MinED (Minimum Edit Distance)로 대체했다고 합니다.
- Fusion Strategies
- 위 내용을 하나로 합치게 되면, 각 source LLM이 갖는 확률 분포를 구하고, MinED를 통해 토큰 간 align을 진행한 뒤, MinCE 또는 AvgCE를 적용하여 Fuse를 진행합니다. 알고리즘은 다음과 같습니다.
4. Experiments
Setup
- Dataset for continual trainnig: MiniPile 데이터셋을 사용합니다.
- Fusion function: minimum cross-entropy (MinCE)를 사용합니다.
- 8 NVIDIA A100 GPUs (40GB), FlashAttention, HuggingFace Transformers
- Evaluation
- Big-Bench Hard (BBH): few-shot chain-of-thought (CoT) prompts, exact match (EM) accuracy
- Common Sense (CS): likelihood-based zero-shot evaluation, accuracy
- MultiPL-E (ME): zero-shot code generation, pass@1
- Baselines
- original LLMs: Llama-2 7B, OpenLLaMA 7B, MPT 7B
- Llama-2 CLM
Results
BBH에 대한 결과를 정리한 표입니다.
일반적으로는 CLM 만으로도 성능이 향상되기도 하고, 특히 FuseLLM은 전반적으로 기존 모델들 대비 뛰어난 성능을 보인다는 것을 알 수 있습니다.
다만, backbone이 되는 모델 Llama-2가 약세를 보이거나, 그 외 두 개의 모델이 약세를 보이는 경우 FuseLLM 또한 좋은 성능을 발휘하지 못한다는 것이 특징입니다.
BBH에서 언급한 특징과 엮어서 생각해본다면, 결국 기본 모델들도 어느 정도는 적당한 구색을 갖춘 수준은 되어야 FuseLLM이 의미 있는 성능 향상을 이뤄낼 수 있다고 볼 수 있겠습니다.
즉, 너무 못하는 것들만 모아 놓고 어떤 결과가 좋아지길 바라는 것은 무리라는 뜻입니다.
Llama-2 13B 모델을 teacher 모델로 삼아 Knowledge Distillation 했을 때의 결과와 비교한 것입니다.
FuseLLM이 이보다도 더 좋은 결과를 달성했다는 것은, 작은 모델들만을 사용하는 방법론이 충분히 활용될 가능성이 있다는 것을 시사하는 것으로 보입니다.
또한 공개된 다른 open-source 모델들로 기존의 Ensemble, Weight Merging 방식을 비교한 결과입니다.
처음 논문의 주장대로 기존의 모델 fusion 방식보다 뛰어난 결과가 나타났다는 것을 알 수 있습니다.
5. Insights
요즘 모델을 합치는 방식에 대한 연구들이 꽤나 많은 것 같습니다.
단순 앙상블이라고 보기에는 어려운.. 그래도 나름 정교한 것 같은..?
LLM이 갖고 있는 치명적인 문제 중 하나가 높은 latency이기 때문에 이를 최소화하면서, 혹은 높이지 않으면서도 좋은 성능을 낼 수 있는 방법을 고민하는 것이 좋은 것 같습니다.
이럴 때는 학습할 데이터를 잘 만들어내는 게 방법이 될 수 있겠죠.
위에서 언급된 바와 같이 여러 모델을 추론 시에 동시에 활용하면 메모리 문제도 있고..
그 모델들의 출력 결과가 확률 분포를 곧 의미하게 되므로, 내재된 능력 등을 externalize한다는 접근이 굉장히 좋은 것 같습니다.
이러한 방법을 다른 곳들에도 접목시킬 수 있다면 좋을 것 같네요.
출처 : https://arxiv.org/abs/2401.10491
Knowledge Fusion of Large Language Models
While training large language models (LLMs) from scratch can generate models with distinct functionalities and strengths, it comes at significant costs and may result in redundant capabilities. Alternatively, a cost-effective and compelling approach is to
arxiv.org