
관심 있는 NLP 논문을 읽어보고 ChatGPT를 이용하여 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[ByteDance Research]
- CoT 데이터에 SFT를 적용할 때, 각 질문마다 존재할 수 있는 여러 개의 reasoning paths를 활용하는 방식
- 수학 문제를 푸는 세 개의 벤치마크(GSM8K, MathQA, SVAMP)를 통해 뛰어난 generalizability를 확인
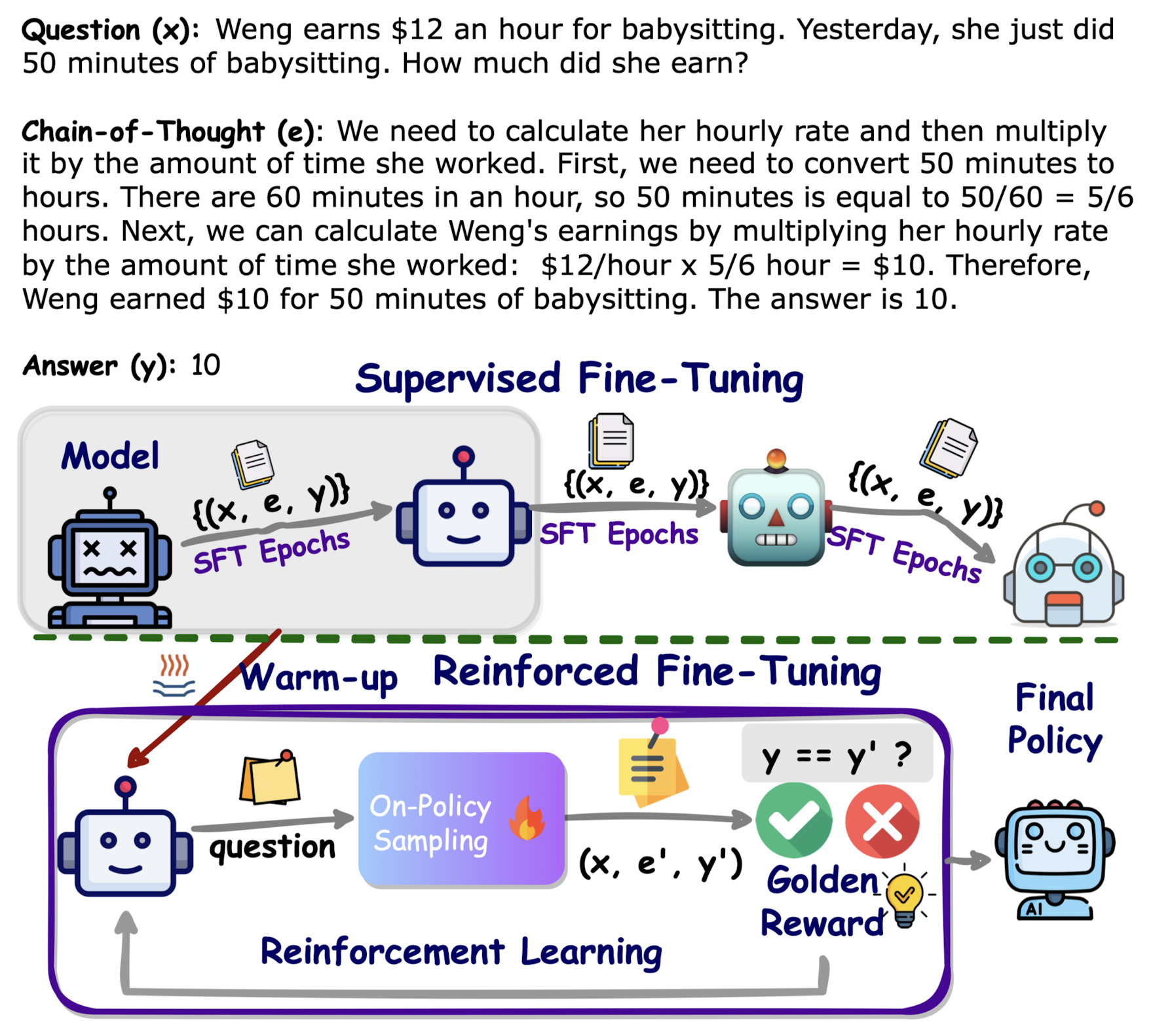
- SFT로 warmup한 이후 PPO를 적용하는 방식인 Reinforced Fine-Tuning을 제안
- 다양한 inference-tim strategies와 결합 가능한 방법론
1. Introduction
지금까지 수학 문제를 푸는 모델을 만드는 가장 좋은 방식은 Chain-of-Thougt (CoT) annotations를 활용하여 Supervised Fine-Tuning 하는 것으로 알려져 있습니다.
그런데 일반적으로 이런 데이터는 질문 하나당 한 개의 annotation만 존재하므로 일반화 성능이 떨어질 수밖에 없다는 문제점을 안고 있습니다.
CoT와 같은 형태의 annotation은 만들기도 쉽지 않지만, 한 문제에 대해 여러 답변이 존재할 수 있다는 가능성이 배제되고 있는 추가적인 문제가 발생하고 있는 것이죠.
본 논문에서는 이를 해결하기 위해 SFT는 warm-up 스테이지로 삼아 그 과정을 최소화하고, 하나의 수학적 질문에 가능한 여러 답변을 생성한 뒤 이를 바탕으로 추가 강화 학습을 적용하는 방식인 ReFT를 제안하고 있습니다.
여기에는 online Reinforcement Learning (RL) 알고리즘인 Proximal Policy Optimization (PPO)를 사용했다고 합니다.
또한 majority voting, reward modeling reranking과 같은 추론 단계에서의 테크닉들과 결합 가능한 방식이라는 점이 중요한 실험 결과이기도 합니다.
2. Related Work
- Math Problem Solving
- Python program as CoT prompt, increasing the amount of CoT data
- Reinforcement Learning
- PPO, Direct Preference Optimization (DPO), Identity Preference Optimization (IPO), Kahneman-Tversky Optimization (KTO)
3. Method

위에서 설명한 것처럼 Warm-up과 Reinforcement Learning, 두 단계로 구성됩니다.
여기에 사용되는 개념들이 상당히 많고 복잡한데, 자세한 이해를 원하시는 경우 논문을 직접 참고하시는 게 좋을 것 같습니다.
(이걸 다 정리하다가는 시간이 너무 많이 날아가는 관계로 간단히 포인트만 정리하고 넘어가고자 합니다)
Warm-up
- (question, CoT)의 튜플로 구성된 $(x, e)$ 데이터셋을 사용해 policy를 fine-tuning 합니다.
- policy $\pi_{\theta}(\cdot |s_{t})$에서 $a_{t}$를 추출하는데, 이는 vocab의 어떤 토큰이라도 될 수 있고, $s_{t}$는 question과 지금까지 생성된 모든 토큰을 뜻합니다.
- 이때의 손실함수는 다음과 같이 정의됩니다. $L_{SFT}(\theta) = -\mathbb{E}_{e \sim D} \left [ \sum_{i=1}^{L} \log (\pi_{\theta}(a_{t}|s_{t})\right ]$
Reinforcement Learning
- (question, answer)의 튜플로 구성된 $(x,y$ 데이터셋을 사용해 online self-learning을 진행합니다.
- policy 모델은 반복적으로 responses를 sampling하고 각각이 정답인지 평가한 뒤, 이를 바탕으로 파라미터를 업데이트합니다.
- reward function의 경우 response가 정답이면 1, 그렇지 않으면 0을 반환하는데, 숫자로 답해야 하는 경우 부분 점수 0.1점을 부여합니다.
- 이를 통해 effect or learning from sparse reward를 줄일 수 있다고 합니다.
- PPO with a clipped objective algorithm for training
- reward는 reward function score와 Kullback-Leibler (KL) divergence의 합이며 수식은 다음과 같습니다.
$$r_{total}(s_{t},a_{t},s_{t+1}) = r(s_{t},a_{t},s_{t+1}) - \beta KL(\pi_{\theta}(\cdot | s_{t}), \pi_{\theta}^{0}(\cdot | s_{t}))$$ - 최종적으로 유도되는 식들이 더 있는데 여기서는 다루지 않겠습니다. 단, 최종 손실 함수는 다음과 같이 정의됩니다.
$$L_{RL}(\theta, \phi) = L_{policy} + \alpha L_{value}$$
4. Experiments
- Datasets
- GSM8K, SVAMP: 정답이 숫자(값)인 벤치마크입니다.
- MathQA: 여러 개 선택지(ABCD) 중에 하나를 고르는 형태의 벤치마크 입니다.
- GPT-3.5-turbo
- few-shot prompting
- N-CoT, P-CoT annotation을 둘 다 획득 (자연어, 프로그래밍어)
- Baseline
- ReFT with SFT vs self-training
- Offline Self-Training (Offline-ST), Self-Training (Online-ST)
- Models
- Galactica-6.7B, Codellama-7B
- majority voting, reward modeling reranking도 결합해봅니다.
- Results

단순히 SFT만 적용했을 때, Offline-ST, Oneline-ST와 비교했을 때 눈에 띄는 성능 우위를 점하고 있습니다.

반복적으로 언급했던 것처럼 추론 단계에서 사용할 수 있는 다른 테크닉들과 결합해 사용할 수 있는 방식임을 확인했습니다.

모델의 사이즈가 굉장히 작을 때 ReFT를 적용해도 성능 향상이 있다는 것을 확인했습니다.
아주 중요한 실험 포인트라는 생각이 듭니다.
5. Insights
가장 먼저 든 생각은 '강화학습 공부 좀 해야겠다..'였습니다.
사실 RLHF가 주목을 받았을 때 미리 잘 해뒀으면 좋을 것을 많이도 미뤄왔네요..
개인적으로 개선 여지가 많은 포인트는 reward hacking이라고 생각합니다.
논문에서 limitation으로 언급했던 것처럼, sampling된 CoT들이 정답에 해당하는지 아닌지는 최종 결과만 가지고 판단하다보니 중간에 잘못된 내용이 포함되어도 이를 걸러내지 못하는 문제점이 있습니다.

가장 단순하게는 뭐 중간 과정도 타당한지를 확인할 수 있도록 decomposition하고 offline 학습으로 전환한다든가, 평가용 LLM을 활용하여 보다 엄격한 필터링 과정을 거친다든가 하는 방법들을 적용해볼 수 있을 것 같습니다.
물론 이런 방법들 전부 메모리나 latency 이슈를 피해가기는 힘들겠지만요 😅
출처 : https://arxiv.org/abs/2401.08967v1
ReFT: Reasoning with Reinforced Fine-Tuning
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the tr
arxiv.org