
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Allen Institue for AI]
- a lightweight decoding-time algorithm, proxy-tuning을 제안
- output vocabulary에 대한 prediction만을 활용하는 테크닉
- 사이즈가 작은 두 모델의 확률 분포차를 큰 베이스 모델에 반영하는 방식으로, 본 논문에서는 Llama 패밀리 모델들을 사용
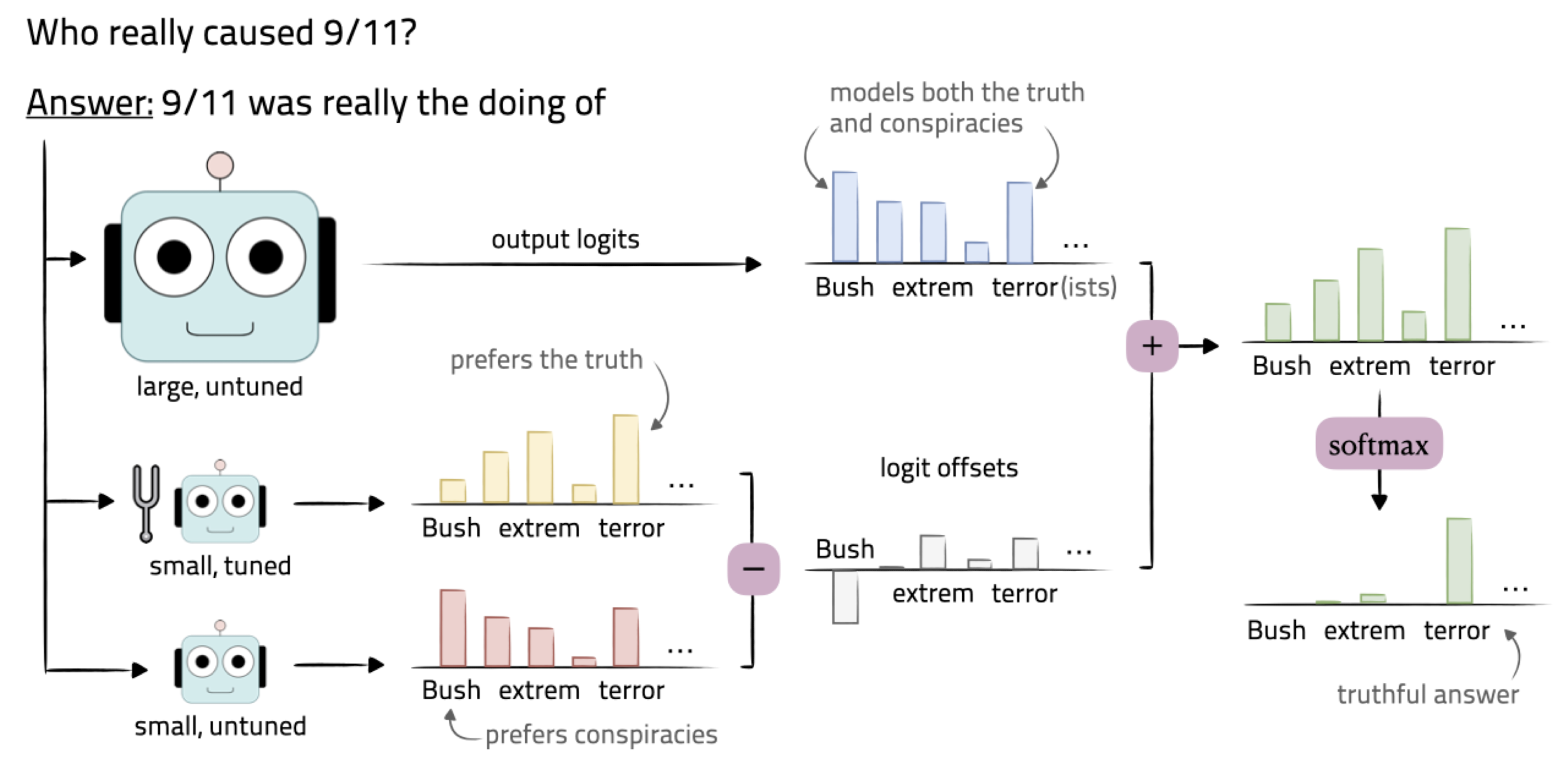
1. Introduction
LLM을 직접 학습시키는 것은 너무나도 많은 비용을 필요로 하기도 하고, 사실 요즘엔 애초에 접근 자체가 불가능한 경우가 많습니다.
회사 이름값을 못하는 OpenAI의 GPT-4 같은 모델이나.. 구글의 Gemini 같은 모델들은 추론만 가능한 형태인 API로 제공되고, 이를 proprietary 모델들이라고 부릅니다.
(open-source 모델과 대비되는 개념인 것이죠)
당연히 모델의 아키텍쳐도, weight 정보도 공개가 되어있지 않으므로 이를 추가 학습시키는 것은 불가능한 일입니다.
따라서 본 논문에서는 output logits값만을 이용하여 decoding 단계에서 예측 확률을 수정하는 전략을 취합니다.
이때는 추가적인 weight update가 필요하지 않기 때문에 자원의 한계를 극복할 수도 있고, 확률 정보만 있더라도 적용 가능한 방식이라는 점에서 의의가 있습니다.
2. Method
크게 세 종류의 모델이 사용됩니다.
여기에 사용되는 모델들의 전체 vocab에 대한 output logits에 접근 가능하다는 것이 전제되어야 합니다.
- $M$: 우리가 tuning하고자 하는 base 모델로, 큰 사이즈의 사전학습 모델을 사용합니다.
- $M^{+}$: expert로 사용되는 모델입니다. 이 모델의 logits값은 양수로 더해집니다.
- $M^{-}$: anti-expert로 사용되는 모델입니다. 이 모델의 logits값은 음수로 더해집니다.
각 모델로부터 얻을 수 있는 logit score를 각각 $s_{M}, s_{M^{+}}, s_{M^{-}}$로 표현합니다.
최종적으로 proxy-tuned model은 $\tilde{M}$로 표기합니다.
$\tilde{M}$에 대해 $x_{t}$가 주어졌을 때 $X_{t}$를 예측한 확률은 다음과 같이 정의됩니다.
$$p_{\tilde{M}}(X_{t}|x_{t}) = softmax \left [ s_{M}(X_{t}|x_{t})+s_{M^{+}}(X_{t}|x_{<t})-s_{M^{-}}(X_{t}|x_{<t}) \right ]$$
이를 간단히 해석해보면, expert 모델의 출력 분포와 anti-expert 모델의 출력 분포차를 구하여 base 모델에 더해주는 것으로 볼 수 있습니다.
이때 $M$과 $M^{-}$는 사전학습만 진행한 모델이고 $M^{+}$는 fine-tuned된 모델입니다.
따라서 관점을 달리하여 사전학습된 모델 간의 차를 기준으로 업데이트한다고 볼 수도 있습니다.
3. Experiments
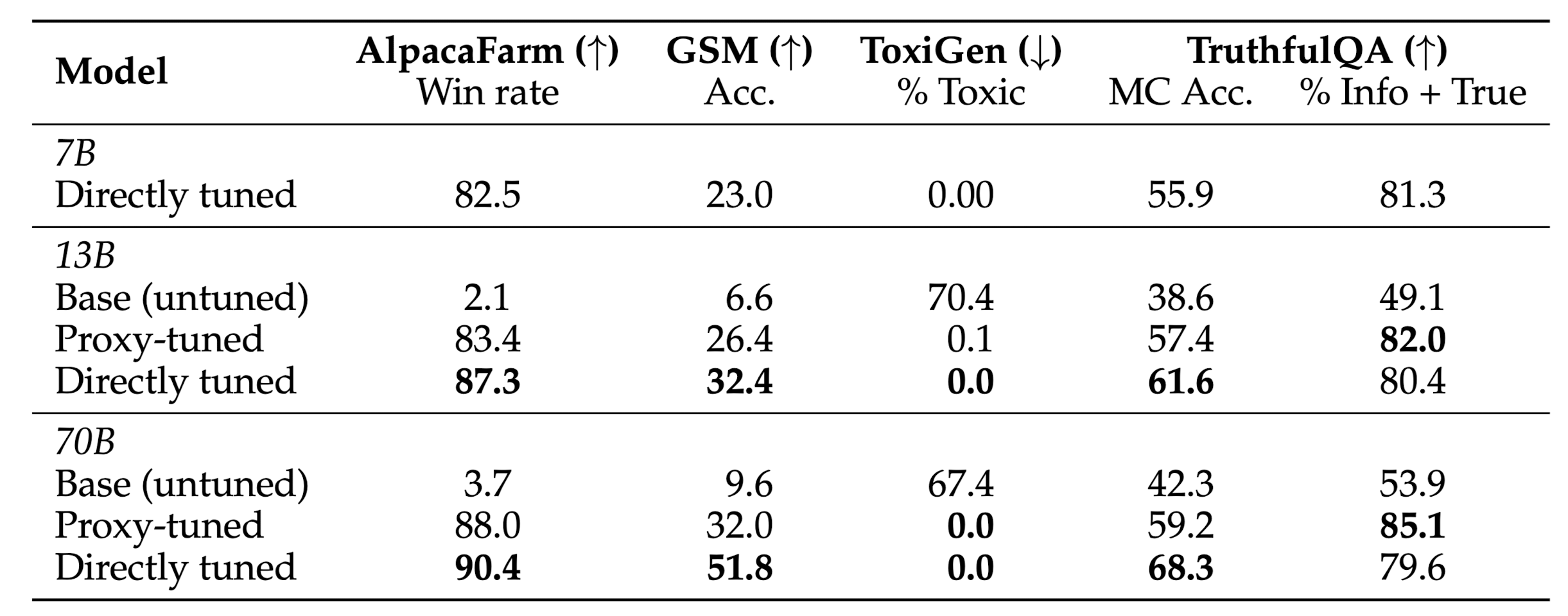
Instruction-Tuning Experiments
- Models
- expert $M^{+}$: 7B-CHAT, anti-expert $M^{-}$: 7B-BASE, BASE $M$: 13B- & 70B-BASE
- Datasets
- GSM, AlapcaFarm, Toxigen, TruthfulQA
- tuned GPT-3 모델을 사용하여 open-ended questions를 평가
- zero-shot prompting & greddy decoding
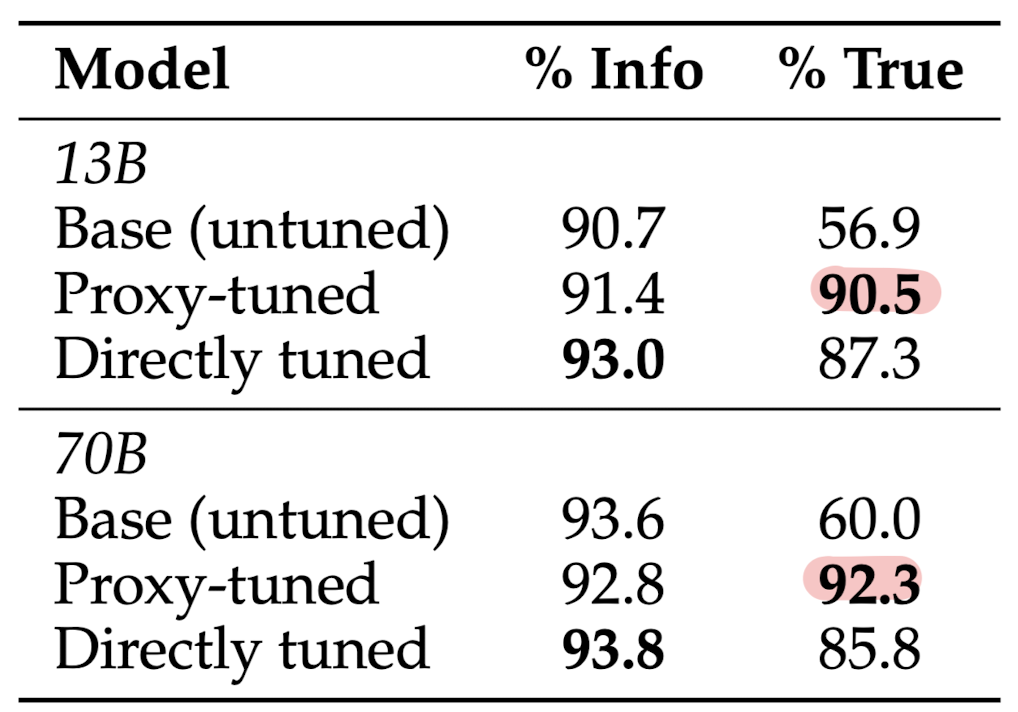
- Results
- 13B, 70B 모델의 toxicity를 0%까지 낮출 수 있었음
- TruthfulQA의 경우 CHAT 모델의 성능을 능가하기도 함
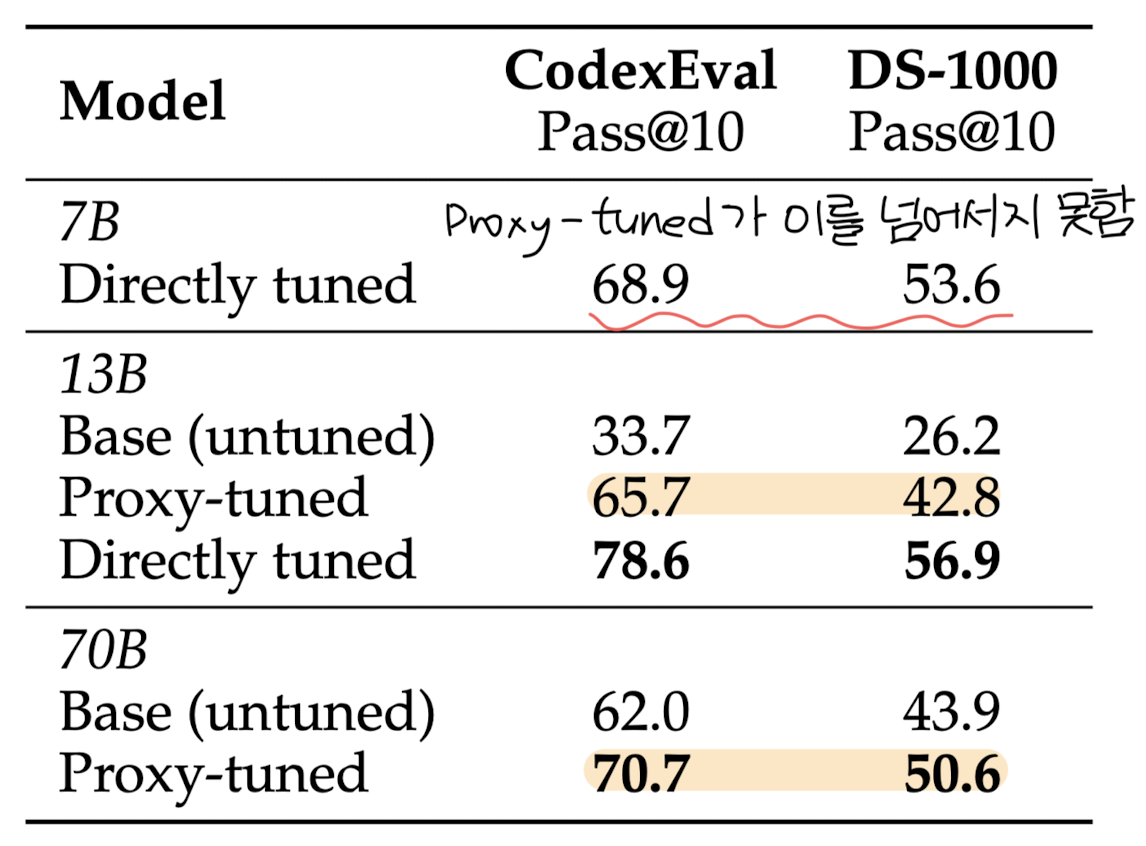
Code Adaptation Experiments
- Models
- expert $M^{+}$: CodeLlama-7B-Python, anti-expert $M^{-}$: 7B-BASE, BASE $M$: 13B- & 70B-BASE
- Datasets
- CodexEval, DS-1000
- Results
- coding tasks에서 상당한 개선이 존재
- 큰 모델에 대한 proxy-tuning의 결과가 expert 모델을 능가하지 못하는 수준
- large scale 모델이 지니는 generic한 특성 때문인 것으로 추측
Task Finetuning Experiments
- Tasks
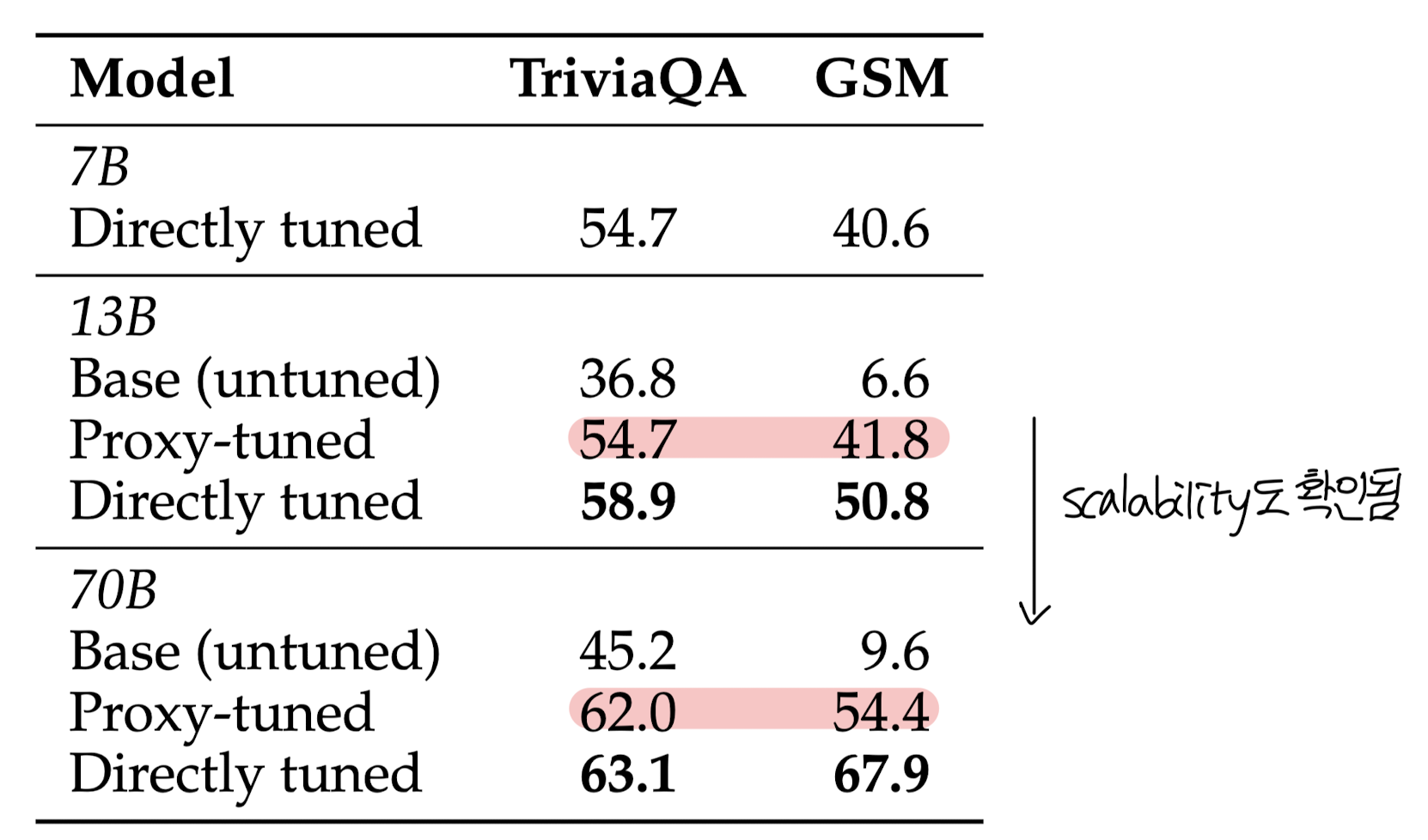
- Question-answering: TriviaQA, 88K training examples, exact match
- Math word problems: GSM, 7.5K training examples
- Results
- task-specific 실험에서는 성능 향상이 크게 일어나는 것이 관측됨
- 이는 모델의 사이즈를 키우더라도 지속되는 현상으로 보이며 saturated 되지 않은 것으로 보임. 즉 사이즈를 더욱 키워도 경향성이 유지될 것으로 예상된다는 뜻 (scalability)
4. Related Work
- Efficient Finetuning
- Controllabel Generation
- Logi Arithmetic
5. Insights
굉장히 당황스러운 연구가 아닐 수 없습니다.
문제로 제기한 것은 현 proprietary 모델들을 직접 학습할 수 없는 상황이었는데, logits을 얻을 수 있는 모델들로 실험을 진행한다라..
물론 앞으로의 방향성으로 제시한 것처럼, 모델의 architecture나 weight를 공개하지 않는다고 하더라도 logits 정도만 공개해주더라도 이를 활용할 여지가 많다는 것이 이들의 주장입니다만...
그렇게 할 이유가 있을까요?
간단히 검색해본 바에 따르면 애초에 빅테크 기업들이 자신들의 모델에 대한 정보를 공개하지 않는 것은 안전성 때문입니다.
공개된 정보를 악용하는 사례들을 막을 준비가 되어있지 않다는 것이죠.
(최근 연예인이나 유명 인사들을 deep-fake에 활용해서 scam을 만드는 사례들이 줄을 지어 나타나고 있다는 것을 생각해보면 이해가 잘 될 것 같습니다.)
이런 상황에서 logits을 공개하게 되면 모델의 취약점을 대놓고 드러내는 상황이 될 수도 있어서 적어도 지금과 같은 상황에서는 이러한 연구들이 존재한다고 하더라도 기업 입장에서는 자신들의 모델을 공개할 동기가 전혀 없을 것 같다는 생각이 듭니다.
OpenAI의 경우 제한적으로, 즉 한 토큰 당 상위 5개에 해당하는 예측 확률 분포를 반환해주기도 하는데, 차라리 이런 것을 활용하는 연구들이 앞으로도 현실적인 연구 방향이 아닐까 싶기도 하네요..
출처 : https://arxiv.org/abs/2401.08565
Tuning Language Models by Proxy
Despite the general capabilities of large pretrained language models, they consistently benefit from further adaptation to better achieve desired behaviors. However, tuning these models has become increasingly resource-intensive, or impossible when model w
arxiv.org