관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️usechatgpt init success[NC Research]- LLM이 생성한 결과를 평가할 때 존재하는 다양한 bias를 정의 (6개)- EvalBiasBench를 제안. 6개 종류의 bias에 대한 test case를 직접 제작함.- OffsetBias 공개. bias를 낮추는 데 기여할 수 있는 학습용 선호 데이터셋 출처 : https://arxiv.org/abs/2407.06551 1. Introduction최근 LLM이 생성한 텍스트를 LLM으로 평가하는 경우가 굉장히 많아졌습니다.LLM으로 생성하는 텍스트는 종류나 범위가 엄청나게 다양한데 이를 사람이 직접 다 평가하기엔..
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Google Research, Google DeepMind] - Open-domain question answering에서 복잡한 Chain-of-Thought (CoT) 추론을 자동적으로 평가할 수 있는 verifiers를 개발 - 이 벤치마크를 REVEAL: Reasoning Verification Evaluation으로 명명 1. Introduction 인공지능 모델이 어떤 질문에 답변할 때 reasoning step을 추가하도록 하면 그 답변의 정확도가 크게 향상된다는 것이 알려지게 되면서 해당 연구가 활발히 이뤄지고 있습니다. 대표..
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [FAIR, Meta, HuggingFace, AutoGPT, GenAI] - General AI Assistant의 성능을 평가하기 위해 real-word question으로 구성된 벤치마크, GAIA 공개 - 사람은 풀기 쉽지만 인공지능 모델은 풀기 어려운 466개 (그중 166개만 annotation 공개) Q&A pair - 무려 Yann LeCun이 저자에 포함된 논문 1. Introduction LLM은 general tasks를 처리하는 우수한 능력으로 주목을 받았으나 이를 평가하는 시스템은 아직까지 open problem 최근의 벤..
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [KAIST, LG AI Research, Korea University] - LM이 이전의 지식을 그대로 보유하고 있는지, 그리고 최신의 지식을 습득했는지 확인할 수 있는 벤치마크 - TWiki-Diffsets, TWiki-Probes 두 개의 셋으로 구성 - diff data에 대해 LM을 continual learning 하는 것이 perplexity 관점에서 준수하다는 결과 배경 LM의 능력을 평가하는 데이터셋은 대부분 static train / test 데이터셋의 misalignment는 closed-boo..
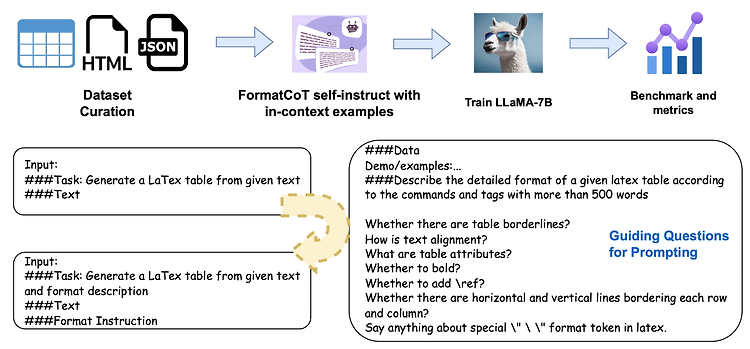
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success 대표 LLM들의 structured output 생성 능력을 테스트하기 위한 Struc-Bench를 제안. FormatCoT(Chain of Thought)를 활용하여 format instruction을 생성. 여섯 개 관점에서 모델의 능력을 나타내는 ability map 제시. 배경 (벌써 몇 주째 같은 이야기로 리뷰를 시작하는 것 같은데.. 😅) 최근 LLM이 다방면으로 엄청난 퍼포먼스를 보여주는 것은 사실이지만, 특정 분야나 태스크에 대해서는 여전히 뚜렷한 한계를 보여주고 있습니다. 그중 가장 대표적인 것 중 하나가 struct..
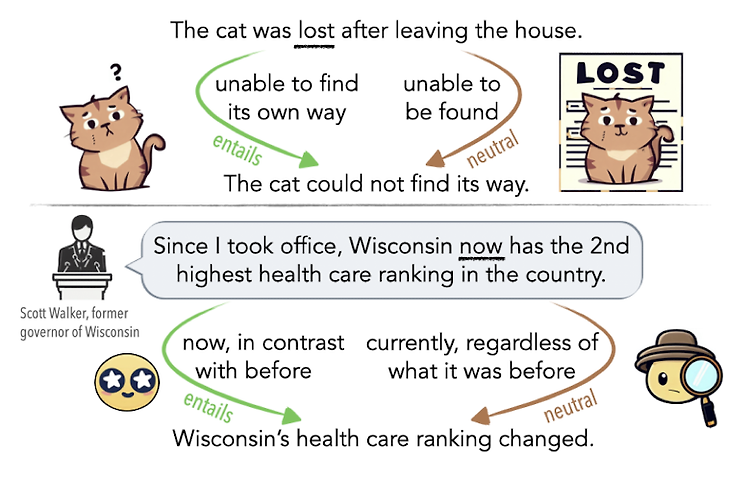
최근에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ 언어가 지닌 ambiguity(모호성)을 인공지능 모델이 이해할 수 있는지 확인할 수 있는 벤치마크 제작 배경 언어의 모호성(ambiguity)는 인간 언어 이해에 있어서 중요한 요소입니다. 중의적인 표현에 대한 해석을 간단한 예로 떠올려 볼 수 있습니다. 때로는 문법적인 오류로 인해 중의적인 의미를 지니는 문장이 될 수도 있지만, 주변 단어들과의 관계에 의해 의미 차이가 발생하는 경우도 존재합니다. LLM을 기반으로 한 챗봇, 즉 대화형 인공지능 모델이 큰 인기를 얻음에 따라, 인공지능 모델이 사람의 언어에 존재하는 이러한 모호성을 이해하고 좋은 판단을 내릴 수 있는지에 대한 관심도 커지고..