최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
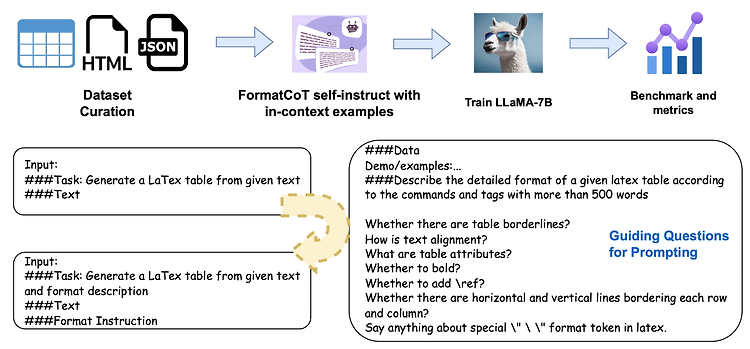
대표 LLM들의 structured output 생성 능력을 테스트하기 위한 Struc-Bench를 제안.
FormatCoT(Chain of Thought)를 활용하여 format instruction을 생성.
여섯 개 관점에서 모델의 능력을 나타내는 ability map 제시.
배경
(벌써 몇 주째 같은 이야기로 리뷰를 시작하는 것 같은데.. 😅)
최근 LLM이 다방면으로 엄청난 퍼포먼스를 보여주는 것은 사실이지만, 특정 분야나 태스크에 대해서는 여전히 뚜렷한 한계를 보여주고 있습니다.
그중 가장 대표적인 것 중 하나가 structured data입니다.
즉, LLM은 구조화된 형식의 output을 만들어내는 능력이 부족하다는 한계가 지속적으로 제기되고 있고, 이는 다양한 분야에 활용 가능한 핵심적인 기술이라는 측면에서 앞으로도 연구의 여지가 많습니다.
본 논문에서는 기존에 LLM의 능력에 대한 구조적 분석의 부재, LLM 성능에 대한 세밀하면서도 포괄적인 평가의 부재를 기존 벤치마크의 한계로 지적합니다.
이에 대한 자신들의 contribution은,
1) raw text, HTML, LaTeX 형식의 structured text 생성 능력을 평가하는 Struc-Bench 제시
2) 기존의 prominent dataset을 통합하고 다양한 도메인으로 확장하여 LLM이 일으키는 에러를 보다 정확히 분석할 수 있게 되었음
3) ChatGPT로 생성한 format instruction을 활용하여 LLaMA 모델이 이 format을 따르도록 학습시키는 structure-aware instruction tuning을 고안
한 것이라고 주장합니다.
본론
Problem Analysis and Benchmark
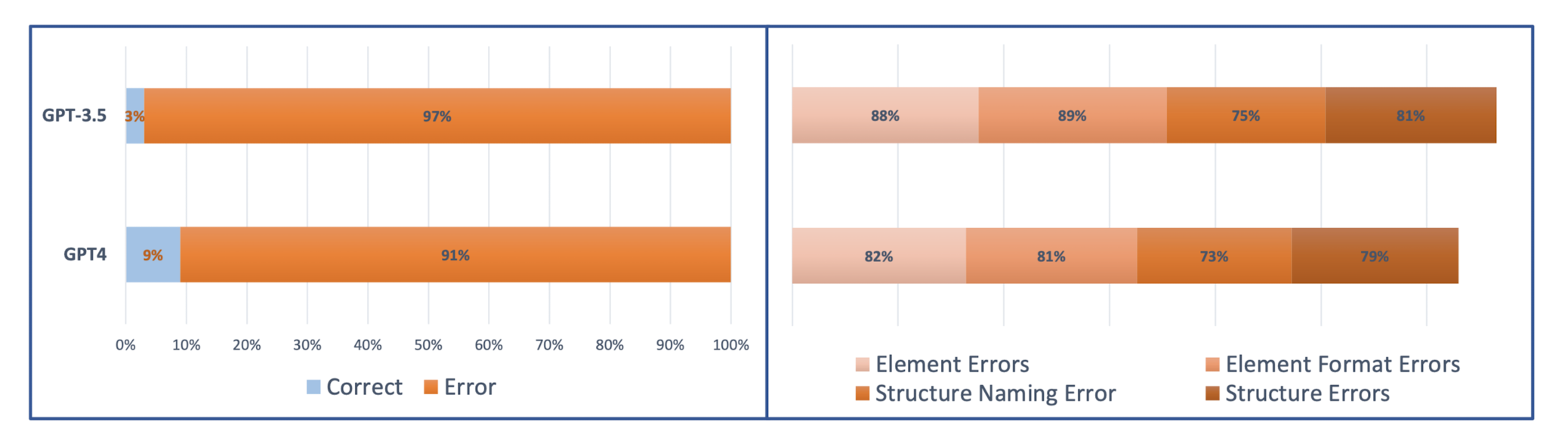
- LLM은 intricate, format-specific outputs을 제대로 만들어내지 못한다는 한계를 지님
- 이는 엄격하면서도 특정한 데이터 구조와 형식을 유지하는 것의 어려움에 기인하는 것으로 판단됨
- GPT-3.5의 경우 3%, GPT-4의 경우 9%에 해당하는 output만이 완전히 올바른 형태였음
- Rotowire, E2E, WikiTableText, WikiBio, 네 개의 data-to-text dataset을 통합
- 3x3 차원 이상의 테이블을 선별하여 복잡도를 보장하고자 함
- GitHub로부터 Latext, HTML 테이블 데이터를 수집

Methodology
- FormatCoT & self-instruct with GPT-3.5 to generate data, instruction pairs
- structure-aware instruction tuning method to fine-tune LLaMA-7B
- Metrics : table의 두 요소, content & structure에 대해 각각 평가
- content : 생성된 tabel과 ground-truth tabel의 cell 간 유사도를 계산
- structure : 행과 열의 개수, cell alignment 등의 요소에 대한 유사도를 계산
- Scores : 각 metric에 대해 model / human 중심의 evaluation을 각각 진행
- GPTscore : GPT-3.5로 table의 content와 structure 유사도를 각각 계산하도록 함
- H-Score : hand-crafted scoring functions
Experiment
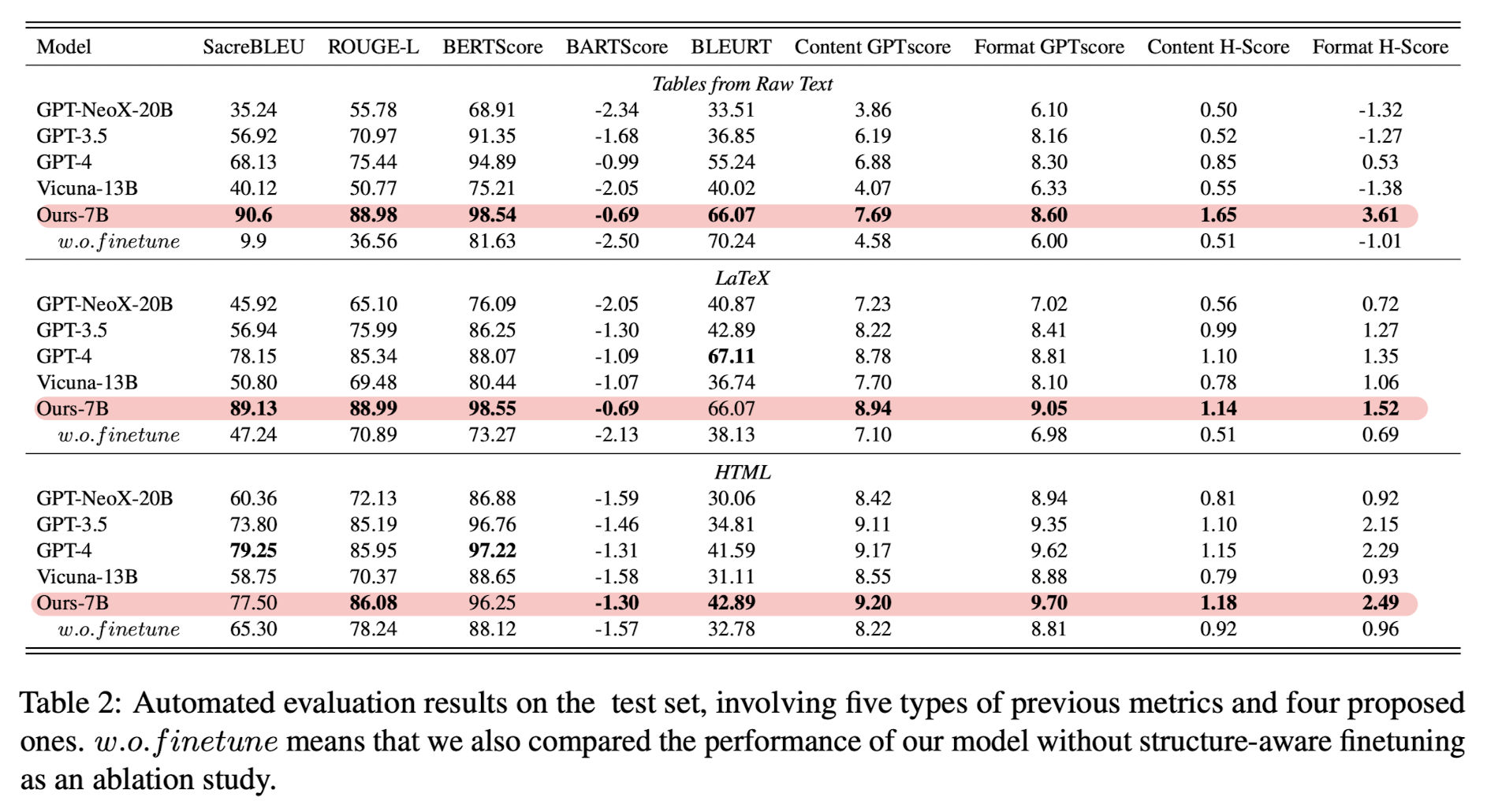
- text 유사도를 측정할 수 있는 고전적인 metric을 모두 사용 : ScareBLEU, ROUGE-L, BERTScore, BARTScore, BLEURT 등
- 여기에 GPT socre와 H-score까지 추가
- 표에서 볼 수 있듯이 'Ours-7B' 모델이 대부분을 압도하는 결과
- Content에 대한 GPTscore와 H-Score는 기존 metrics와 굉장히 align하는 결과가 나타남. 하지만 Format에 대해서는 GPTscore와 Fromat H-Score가 기존 metric 대비 훨씬 높은 점수를 보임.
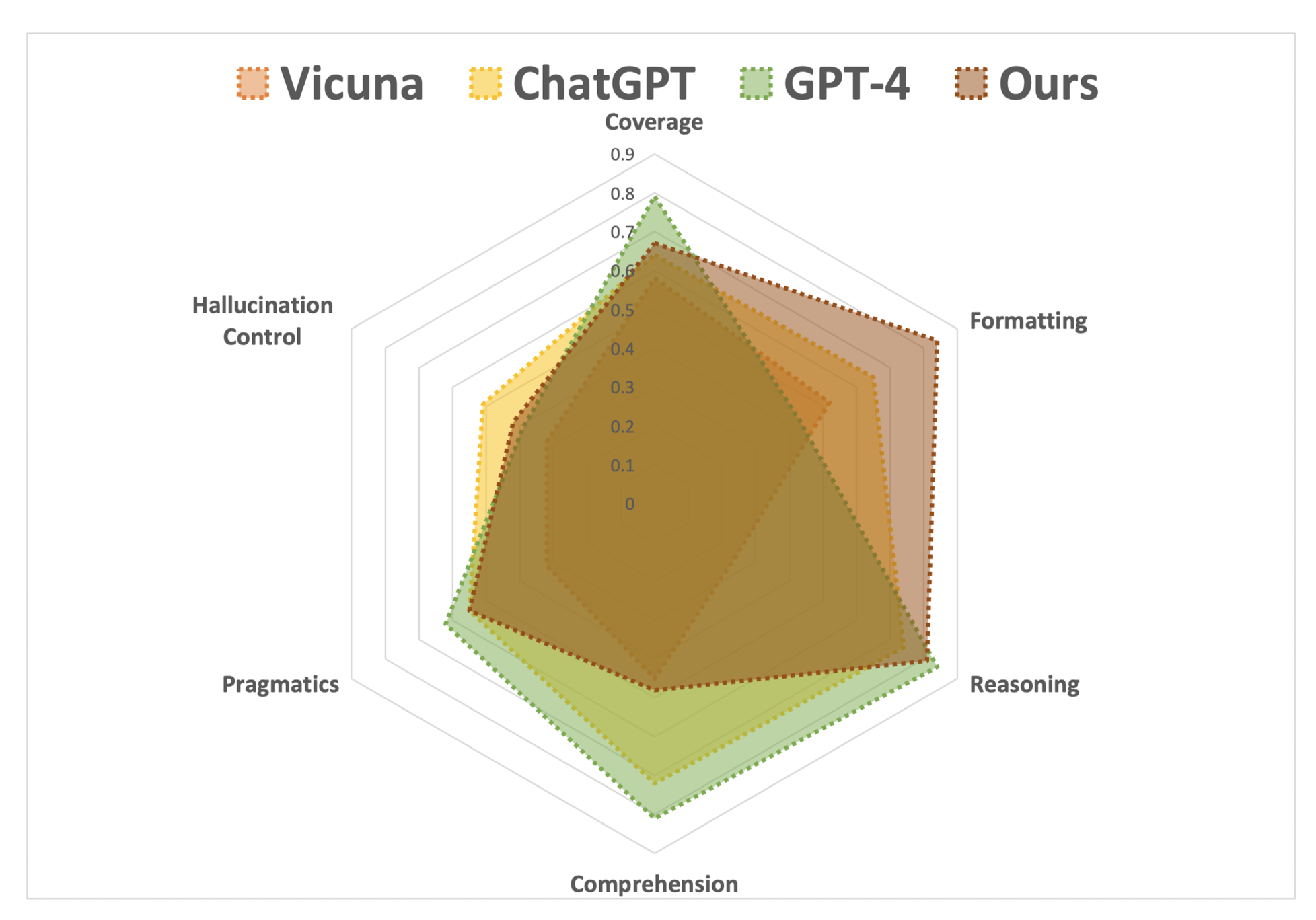
- LLM으로서 갖는 전체적인 퍼포먼스에는 큰 변화가 없지만, 확실히 구조화된 output을 만들어내는 능력은 폭발적으로 향상하는 것을 볼 수 있음
Limitations
- Domain-Specific Benchmark Development
- 저자 스스로 한계라고 해놨는데 어떤 도메인의 table 데이터를 주로 가져다 쓴 건지 명시도 되어 있지 않다..
사실 이런 구조화된 데이터를 잘 다루면 좋은 분야들이 굉장히 많은데, 이를 범용적으로 활용 가능한가라는 의문을 제시한다면 거의 무조건 No, 라고 답변할 수밖에 없을 듯하다.
- 저자 스스로 한계라고 해놨는데 어떤 도메인의 table 데이터를 주로 가져다 쓴 건지 명시도 되어 있지 않다..
- Enhancing Numerical Reasoning Capabilities
- 위에 나타난 것처럼 LLM의 기타 일반적인 능력은 전혀 향상되지 않는다는 것을 볼 수 있다.
그렇다면 이렇게 아주 특수하고 세부적인 task나 데이터에 대해서만 활용 가능한 모델이 갖는 의의는 무엇일까?
단순 Exact Match를 위한 모델들을 넘어서기 위해 제안된 것 치고는 다소 아쉬워 보이는 결과라는 생각도 든다.
- 위에 나타난 것처럼 LLM의 기타 일반적인 능력은 전혀 향상되지 않는다는 것을 볼 수 있다.
출처 : https://arxiv.org/abs/2309.08963
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
Despite the power of Large Language Models (LLMs) like GPT-4, they still struggle with tasks that require generating complex, structured outputs. In this study, we assess the capability of Current LLMs in generating complex structured data and propose a st
arxiv.org