
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Research, Google DeepMind]
- Open-domain question answering에서 복잡한 Chain-of-Thought (CoT) 추론을 자동적으로 평가할 수 있는 verifiers를 개발
- 이 벤치마크를 REVEAL: Reasoning Verification Evaluation으로 명명
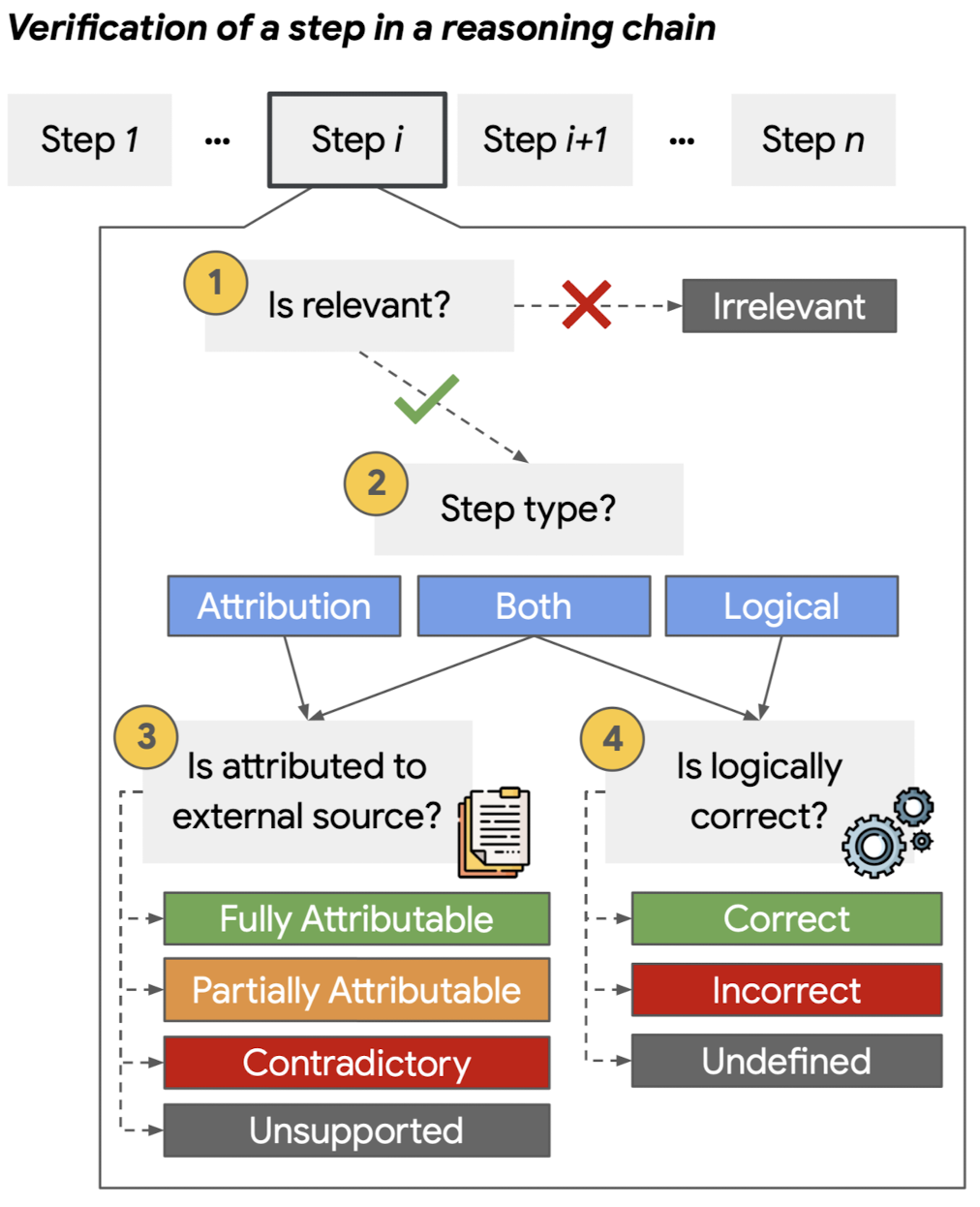
1. Introduction
인공지능 모델이 어떤 질문에 답변할 때 reasoning step을 추가하도록 하면 그 답변의 정확도가 크게 향상된다는 것이 알려지게 되면서 해당 연구가 활발히 이뤄지고 있습니다.
대표적으로는 Chain-of-thought (CoT)를 들 수 있겠죠.
하지만 이런 방식의 가장 큰 문제는 중간의 reasoing steps가 전부 옳은 내용인지, 혹은 타당한 논리적 추론에 의한 것인지 확인하기 어렵다는 것입니다.
당연히 데이터셋을 만들기도 어렵고 채점 및 평가하는 것도 상당히 어렵습니다.
이를 본 논문에서는 'lack of high-quality, step-level annotated data' 문제라고 칭합니다.
이를 해결하기 위해 제작된 벤치마크 REVEAL 다양한 종류의 추론 스킬 및 난이도로 구성된 데이터들을 보유하고 있으며, annotater 간 의견 일치 정도에 따라 Reaval-Eval, Reveal-Open 두 개의 데이터셋을 구분하여 공개했습니다.
2. Formalism for Verification of Reasoning Chains
원래는 주어진 vocabulary $\mathbb{Z}$에 대해 verifier $V$는 $\mathbb{Z}^{|q|} \times \mathbb{Z}^{|r|}$로 정의됩니다.
그런데 여기에서는 evidence $e$를 추가하여 $V:\mathbb{Z}^{|q|} \times \mathbb{Z}^{|r|} \times \mathbb{Z}^{|e|} \rightarrow \left [ 0,1 \right ]$가 됩니다.
Full chain vs. step-level verification
verifier가 어떤 것을 입력으로 받을지에 따라 full chain과 step-level로 구분할 수 있습니다.
전자의 경우 전체 reasoning chain이 옳고 그른지에 따라 output을 반환하고, 후자의 경우 각 step을 따로 평가하는 방식입니다.
본 논문에서는 후자의 방식을 취하고 있는데, 이는 'snowballing of hallucinations'를 방지하기 위함이라고 밝혔습니다.
Correctness of an individual step
(1) Step relevance: 각 step이 질문에 대답하는 것과 relevant한지, 혹은 irrelevant 한 지를 판단
(2) Step type: 각 스텝이 word knowledge(attribution), previous step(logical), both, 셋 중 어디에 기인하는지 확인
(3) Step attribution to external source: 정도에 따라, 'fully attributable, partially attributable, contradictory, unsupported' 등으로 구분
(4) Step logical correctness: 이전 step으로부터 논리적으로 추론된 내용이 맞는지 확인
(5) Hybrid steps
논문에서는 어떤 식으로 annotation 했는지에 대한 설명이 있는데 이에 대해서는 생략하도록 하겠습니다.
자세한 방법론이 궁금하신 분들은 논문을 직접 참고해보시면 좋을 듯합니다.
(본문 최하단에 논문 링크 있습니다)
3. Data Collection Process
이 과정을 크게 세 단계로 구분했다고 합니다.
Step 1: Reasoning Chain Generation
네 개의 open-domain question answering 데이터셋으로부터 모델을 통해 chain을 생성합니다.
여기에 사용된 네 개의 데이터셋은 'StrategyQA, MuSiQue, Sports Understanding, Fermi'라고 합니다.
chain을 생성하기 위해 사용된 LM은 'Flan-PaLM-540B, GPT-3 (text-davinci-003), Flan-UL2-20B'입니다.
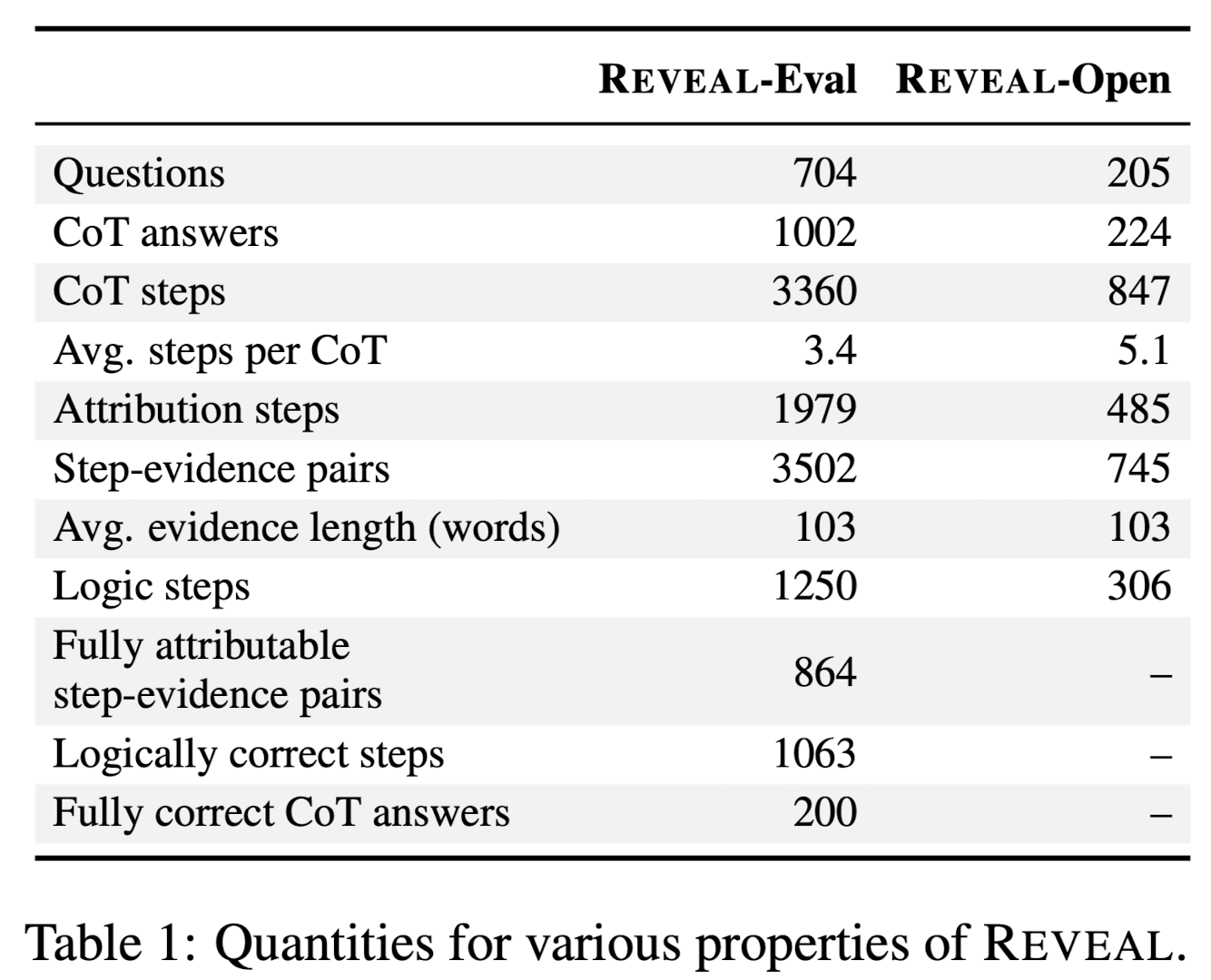
구축된 데이터셋 통계는 다음과 같습니다.
Step 2: Evidence Retrieval
Wikipedia를 external knolwedge source로 사용합니다.
그리고 각 attribution step마다 이 source에서 세 개의 paragraph를 가지고 옵니다.
이때 두 개의 paragraphs에 대해서는 GTR, 나머지 한 개의 paragraph에 대해서는 BM25를 사용했다고 합니다.
Step 3: Annotation
question마다 다섯 개의 annotations를 수집했습니다.
데이터셋을 공개할 때는 어떤 annotater가 작업했는지 표시해 둔 비식별화된 정보까지 함께 공개했다고 합니다.
annotater가 갖는 특성이나 편향된 정보가 있다면 이를 활용하거나 개선할 수 있도록 하기 위함인 것 같습니다.
또한 reasoning 태스크 특성 상 모든 step에 대한 의견 일치가 일어나기는 쉽지 않습니다.
annotator 간 의견이 일치하지 않는 경우를 'low inter-annotator agreement'라고 표현하는데, 다섯 개의 annotation 중에서 세 개 이상의 합의가 없는 경우들은 전부 제외하여 Reval-Open 데이터셋에 포함시켰다고 합니다.
전체 CoT 중 18%가 여기에 해당한다고 하네요.
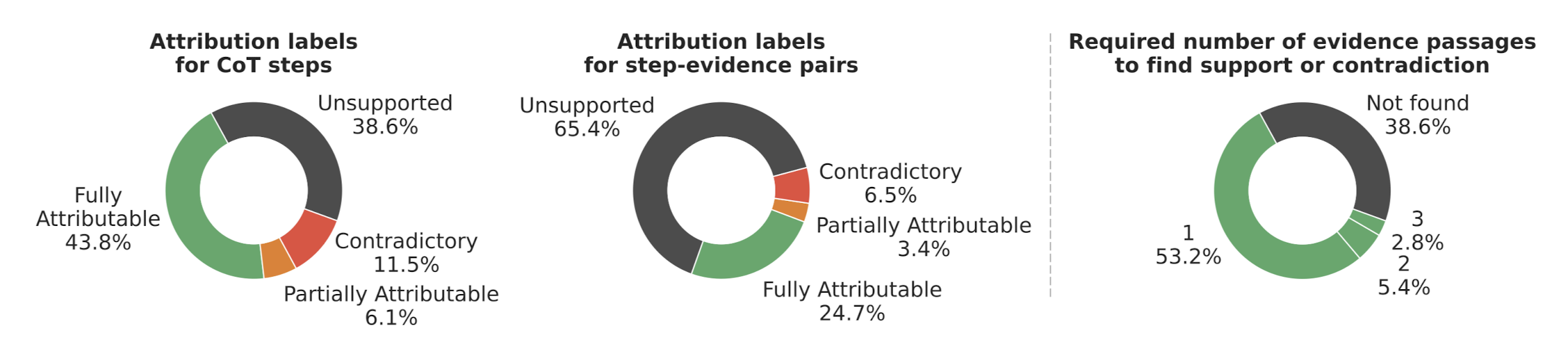
Reveal 데이터셋의 전체 통계 그래프는 다음과 같습니다.
4. Results
실험에 사용된 모델들의 종류는 다음과 같습니다.
- Flan-UL2 (20B)
- Flan-PaLM (540B)
- PaLM-2-L
- GPT-3 (text-davinci-003)
- T5-based model (11B): trained on a mixture of NLI datasets
- FacTool: GPT-3 based fact-checking pipeline
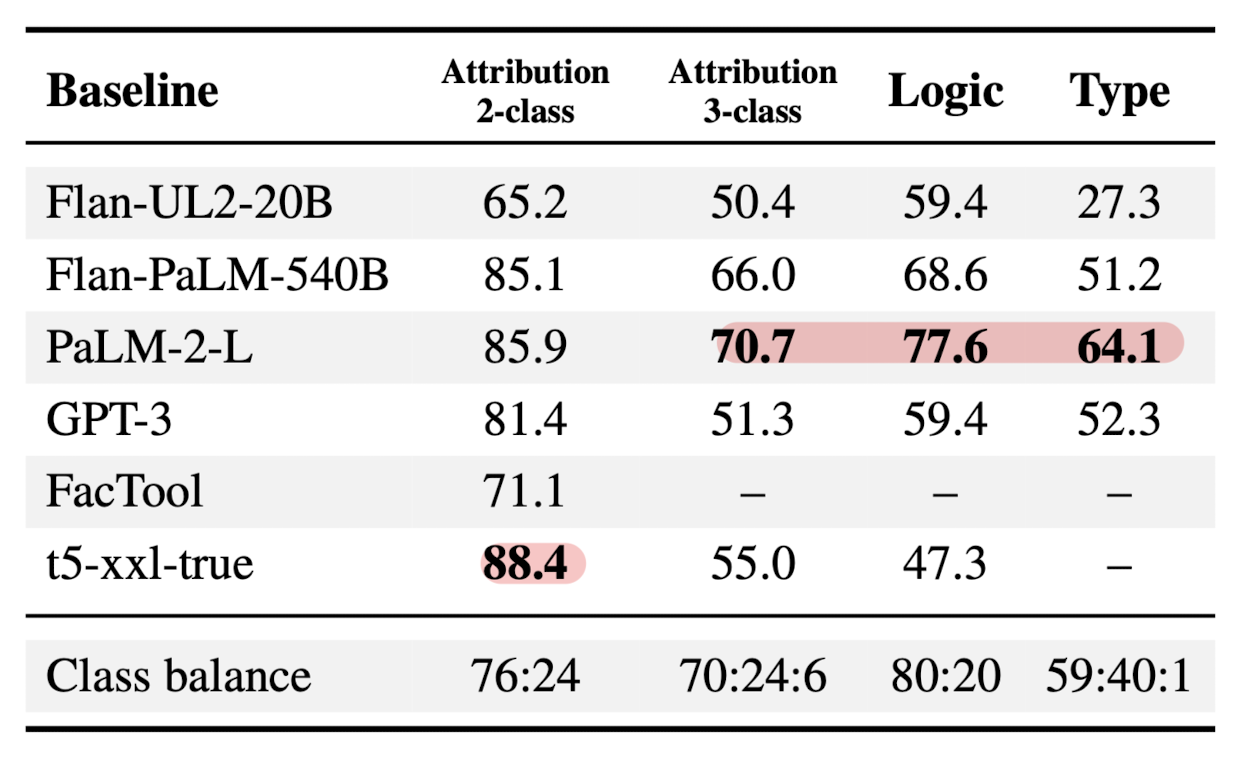
평가를 진행할 때는 5개의 8-shot prompts를 사용하고 그 결과를 평균 내었다고 합니다.
또한 위 결과는 클래스 분포의 불균형을 감안하여 macro-f1 score를 사용한 결과입니다.
(여기서 말하는 클래스는 예를 들어 correct, incorrect 등을 뜻합니다)
위는 Step-level의 평가였고, CoT-level에서의 평가 결과는 아래와 같습니다.
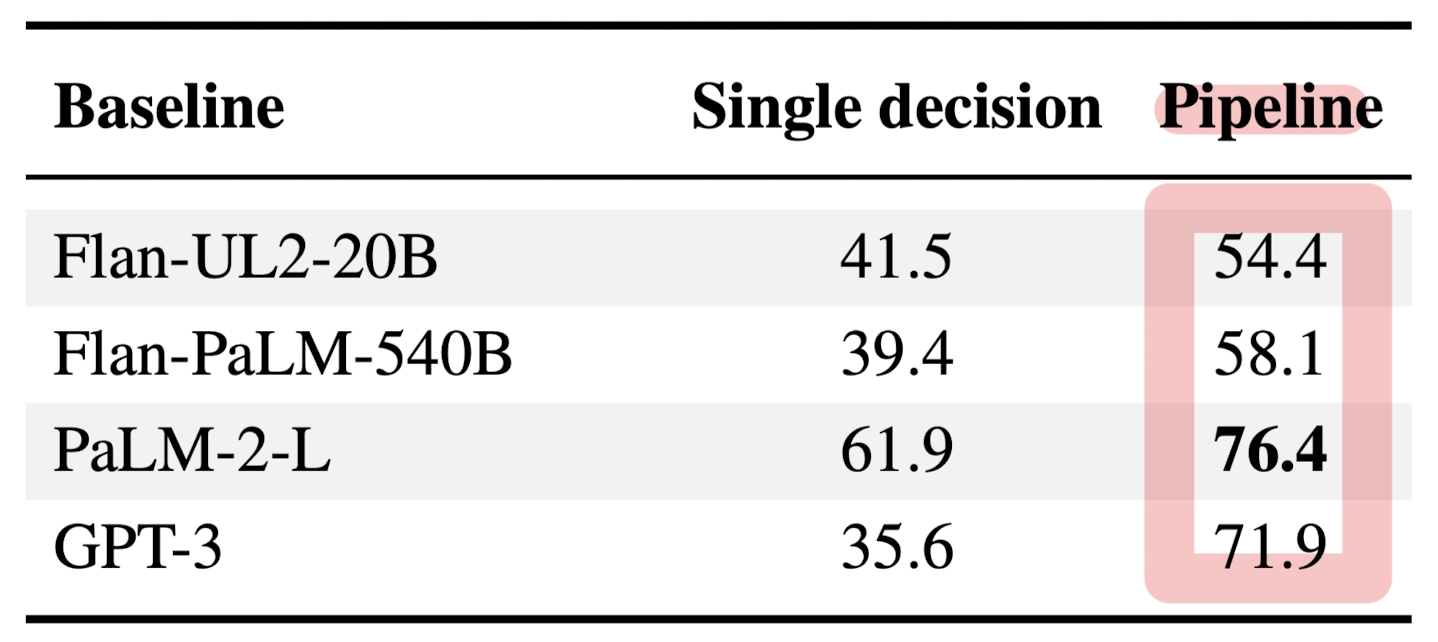
모든 베이스라인이 high-level의 CoT 태스크에서 어려움을 겪는다는 것을 알 수 있습니다.
출처 : https://arxiv.org/abs/2402.00559
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Prompting language models to provide step-by-step answers (e.g., "Chain-of-Thought") is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses auto
arxiv.org