![]()
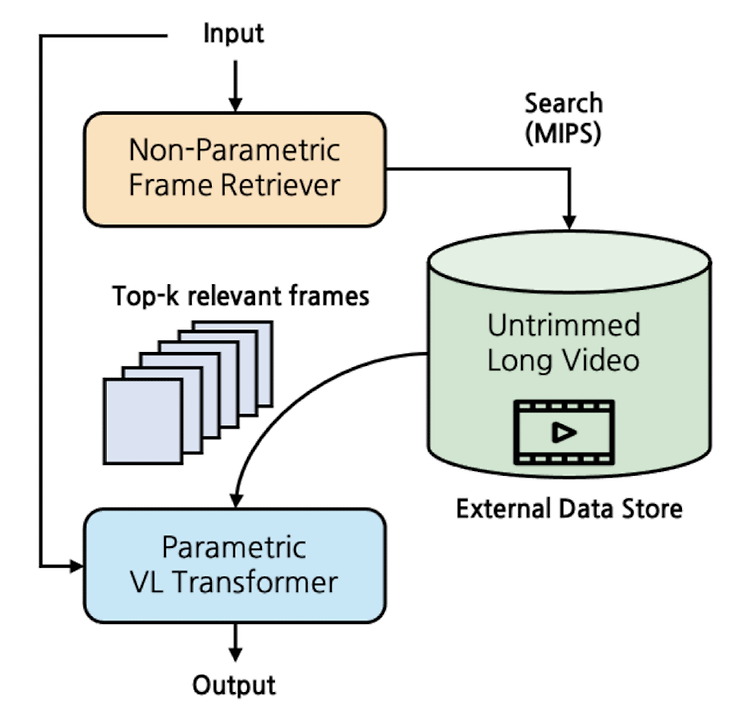
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [Minjoon Seo] - semi-parametric video grounded text generation model, SeViT - video를 외부 data store 취급하여 non-parametric retriever로 접근 - longer video & causal video understanding에서 두각 배경 기존 연구들은 naive frame sampling에 기반하여 sparse video representation의 한계를 지니고 있었음 Realted Works Video-Language M..
![]()
최근(2023.10)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft Research] LLaVA에서 fully-connected vision-language cross-modal connector를 사용한 LLaVA-1.5 공개. data efficient(1.2M public data) & power(SoTA on 11 benchmarks) 배경 최근에는 LLM 뿐만 아니라 LMM, 즉 Large Multimodal Models에 대한 관심도 뜨겁습니다. 여기서도 마찬가지로 전체 모델을 tuning 하지 않고도 성능을 끌어 올리는 기법 등에 대한 연구가 많이 이뤄지고 있죠. 그중..
![]()
최근(2023.09)에 나온 (accept 전 preprint)논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft, MIT] (Factually Augmented) RLHF를 vision-language alignment에 적용. GPT-4를 이용하여 vision instruction tuning을 위한 데이터셋 확보. hallucination 수준을 파악하는 MMHAL-BENCH 개발. 배경 LLM의 부상과 함께 Large Multimodal Model(LMM) 역시 대규모의 image-text pair 데이터에 대한 사전학습을 바탕으로 큰 주목을 받기 시작했습니다. 그러나 multimoda..
![]()
예전(2021.12)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Facebook AI Research (FAIR)] 여러 modality를 '한 번에' 처리할 수 있는 foundation 모델 FLAVA. vision, language, cross/multi-modal vision-langue task 전부 처리. 배경 그렇게 오래 전도 아니지만 이때만 하더라도 multi-modal 모델들의 성능은 지금과 사뭇 달랐던 것 같습니다. 본 논문에서 지적하고 있는 기존 모델들의 한계는 결국 모델의 능력이 '특정 modality에 국한'되어 있다는 것입니다. 여러 modality를 동시에 잘 이해하고 ..
![]()
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success BLIP-2, generic & efficient 사전 학습 Vision & Language Model. frozen image encoder & frozen LLM으로 Querying Transformer를 2-step으로 학습. 배경 이전의 vision-language model을 특정 태스크에 맞게끔 end-to-end 학습하는 방식은 지나치게 많은 자원을 필요로 한다는 문제점이 있었습니다. 본 논문은 자원상의 한계를 극복하면서도 준수한 vision-language model을 만들기 위한 사전 학습 전략을 제시하고 있습니다. ..
![]()
과거(2022.08)에 나온 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Microsoft Corporation] vision 그리고 vision-language task를 고루 잘 수행하는 multimodal foundation model, BEiT-3 여러 pre-training 기법 중에서 오직 masked "language" modeling 기법만을 사용한 것이 특징 배경 Transformers의 아키텍쳐가 엄청나게 좋은 성능을 보이면서 다양한 분야로 퍼져 나갔고, 현재는 multi-modal 분야에도 이것이 활발하게 사용되고 있습니다.(Multiway Transformer) 물론 아직까지 이것이..