![]()
관심 있는 고전(?) 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️usechatgpt init success[Naver Clova, KAIST, LBox, Upstage]- Key information extraction (KIE) 태스크를 잘 처리하기 위해 text와 layout을 효과적으로 결합하는 방식을 고안- BROS (BERT Relying On Spatiality): text를 2D 공간에서 relative position encoding 하고 area-masking strategy를 적용- 현실 세계에서 다루기 어려운 두 가지의 문제(incorrect text ordering, fewer downstream examples)에도 강건함..
![]()
관심 있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️usechatgpt init success[OpenAI]- 당시 computer vision system의 SoTA 모델은 사전 정의된 object 카테고리를 예측하도록 학습됨- 이미지와 어울리는 설명(caption)을 예측하도록 하는 사전학습 방식을 제안- fully supervised baseline과 비교했을 때, dataset specific training을 할 필요가 없음 (zero-shot 성능을 강조) 출처 : https://arxiv.org/abs/2103.00020Introduction논문이 제출되었던 2021년 초라면 아직 챗지피티도 나오기 한참 전이니..당시의 CV..
![]()
관심 있는 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️usechatgpt init success[Microsoft]- scan된 문서에 대한 text와 layout 정보 간의 interaction을 함께 학습- 사전학습 단계에서 문서 단위로 학습 출처 : https://arxiv.org/abs/1912.133181. IntroductionBusiness document를 이해하고 그 정보를 활용하기 위한 연구는 오래 전부터 이어져오고 있었습니다.기존에는 대부분의 문서 작업을 사람이 직접 하는 방식이었기 때문에, 이를 인공지능 모델을 이용하여 효율적으로 해결하고자 한 것이죠.그러나 실제로 여러 문서들은 다양한 layout과 형식으로 구성되는 경우가..
![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Tsinghua University, Zhipu AI] - GUI에 대한 이해가 뛰어난 18B 사이즈의 Visual Language Model (VLM)을 도입 - low-resolution & high-resolution image encoder를 동시에 사용하고 cross attention - VQA & GUI 벤치마크 둘 다에서 뛰어난 성능이 확인됨 1. Introduction 최근 LLM을 바탕으로 한 agent의 성장세가 가파른 상황입니다. 무려 15만 개의 star를 받은 AutoGPT를 시작으로 LLM의 능력을 다양한 applica..
![]()
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ usechatgpt init success [Gemini Team, Google] - image, audio, video, text understanding에 있어서 압도적인 능력을 보여주는 multimodal models faimily, Gemini - MMLU에서 human-expert 이상의 performance를 달성한 최초의 케이스 1. Introduction 여러 modalities를 아우르는 능력을 지녔으면서도 각 도메인에서 뛰어난 understanding & reasoning 능력을 갖춘 Gemini 모델을 학습시켰음 모델의 크기는 세 종류로 구분됨 Ultra: for hi..
![]()
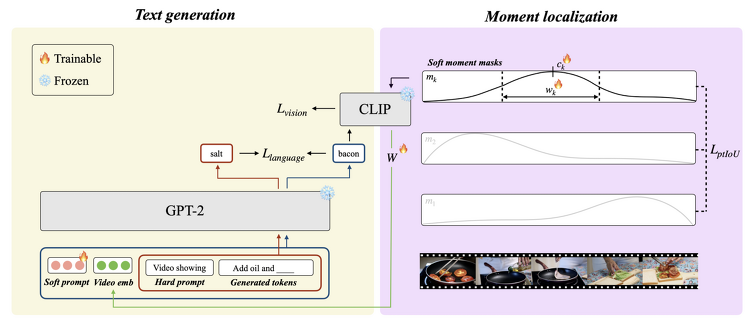
관심있는 NLP 논문을 읽어보고 간단히 정리했습니다. (Language & Knowledge Lab의 Retreival 관련) 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️ [KAIST] - dense video captioning을 zeor-shot으로 처리하는 novel mothod, ZeroTA - soft moment mask를 도입하고, 이를 언어 모델의 prefix parameters와 jointly optimizing - soft momnet mask에 대해 pairwise temporal IoU loss를 도입 - supvervised method에 비해 OOD 시나리오에 대해 강건함 배경 기존의 Dense video captioning은 비디오에 나타난 temporal ..