1. Train / Dev/ Test sets
Applied ML is a highly iterative process

- ML은 다양한 분야에 적용되고 있다.
NLP, CV, Speech Recognitoin, 등.. - 그러나 어떤 분야든지간에 Model에 대한 적합한 hyper parameter를 한 번에 구할 수는 없다.
전문가라 하더라도 위와 같은 cycle을 반복적으로 돌리면서 모델을 적절히 변경할 수 있게 되는 것이다.
Train/dev/test sets
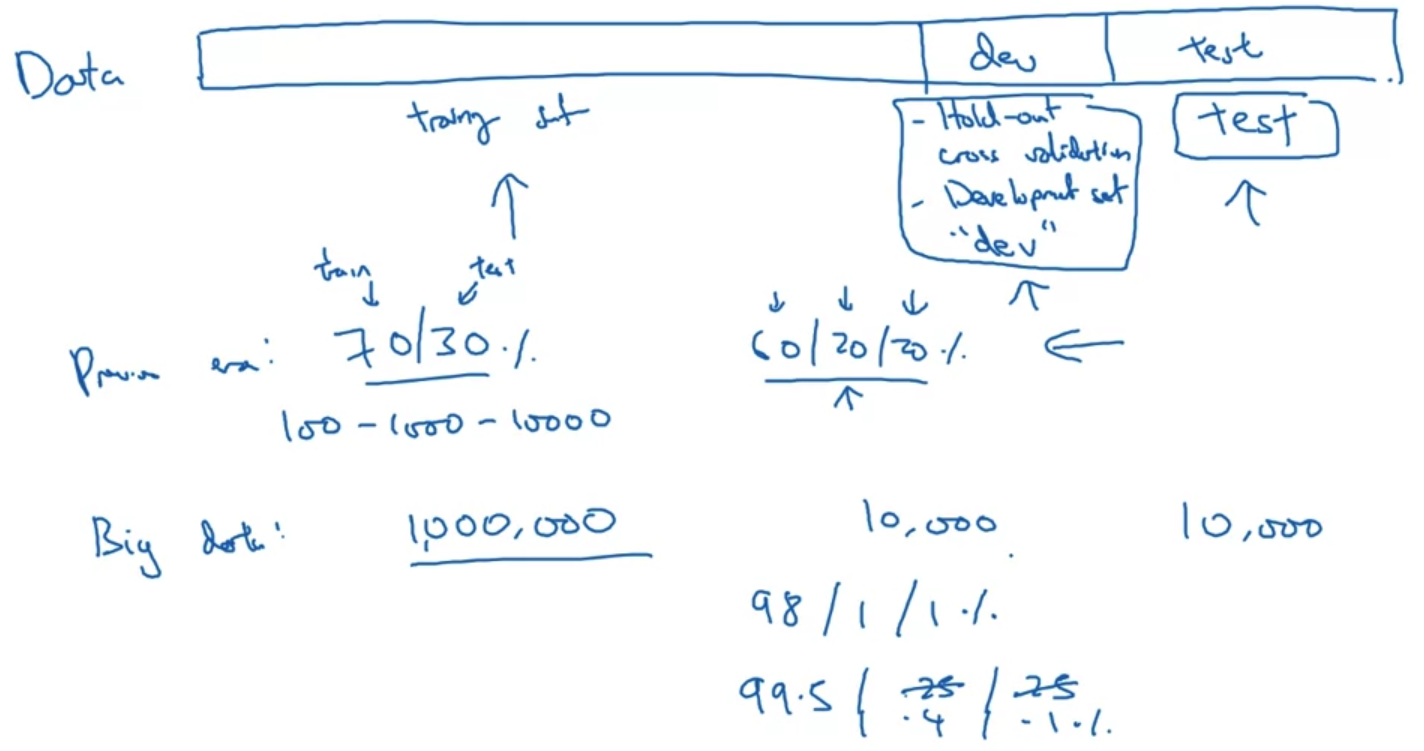
- 우리는 전체 데이터셋을 흔히 train/dev/test 셋으로 나눈다.
train셋에서는 말 그대로 학습을 진행하고, dev셋에서는 우리가 학습시킨 알고리즘과 다른 알고리즘을 cross하여 비교할 수 있으며 test셋에서는 최고의 성능을 보였던 모델을 검증하는 것으로 이해할 수 있다. - 대규모 데이터를 다루기 이전의 시대에서는 train/test 셋으로만 나누며 그 비율을 7:3으로 주로 정했다.
train/dev/test셋으로 나누는 경우 6:2:2 의 비율로 구분하는 경향이 지배적이었다.
이때는 많아 봤자 10,000개 정도의 데이터를 취급했다. - 그러나 1M 개 이상의 데이터를 취급하는 요즘은 dev/test셋의 기존 목적을 유지하는 선에서 최대한 많은 양의 데이터를 train의 재료로 사용한다.
그래서 극단적인 경우 train/dev/test셋의 비율이 98:1:1, 혹은 99.5:0.4:0.1 수준으로 정해진다.
Mismatched train/test distribution

- train set과 dev/test set의 source가 다른 '잘못된 예시'를 설명하고 있다.
인터넷에서 크롤링한 데이터를 train에서 이용하고 유저들이 직접 올린 데이터를 dev/test에서 사용한다고 가정해보자.
이럴 경우 전자에서는 고해상도에 품질이 좋은 데이터가 주를 이룰 것이고 후자는 그렇지 않을 것이다.
결국 이런 데이터 구성은 모델이 좋은 성능을 가지는데 도움이 되지 않는다.(오히려 방해가 된다) - 따라서 데이터를 split할 때 가장 기본이 되는 원칙 중 하나는 "train/dev/test set"의 source가 동일해야 한다는 것이다.
- 때로는 우리의 모델이 unbiased한지 확인하는 test셋이 필요하지 않을 때도 있다.
이때는 사실상 train/dev셋으로만 구성이 되는데, 이를 train/test셋으로 표현하는 경우가 있다.
하지만 이때는 test셋이 사실 모델간의 성능을 비교하는 dev셋의 역할을 수행하고 있으므로 표현상의 mismatch에 휘둘리면 안 된다.
2. Bias/ Variance
Bias and Variance
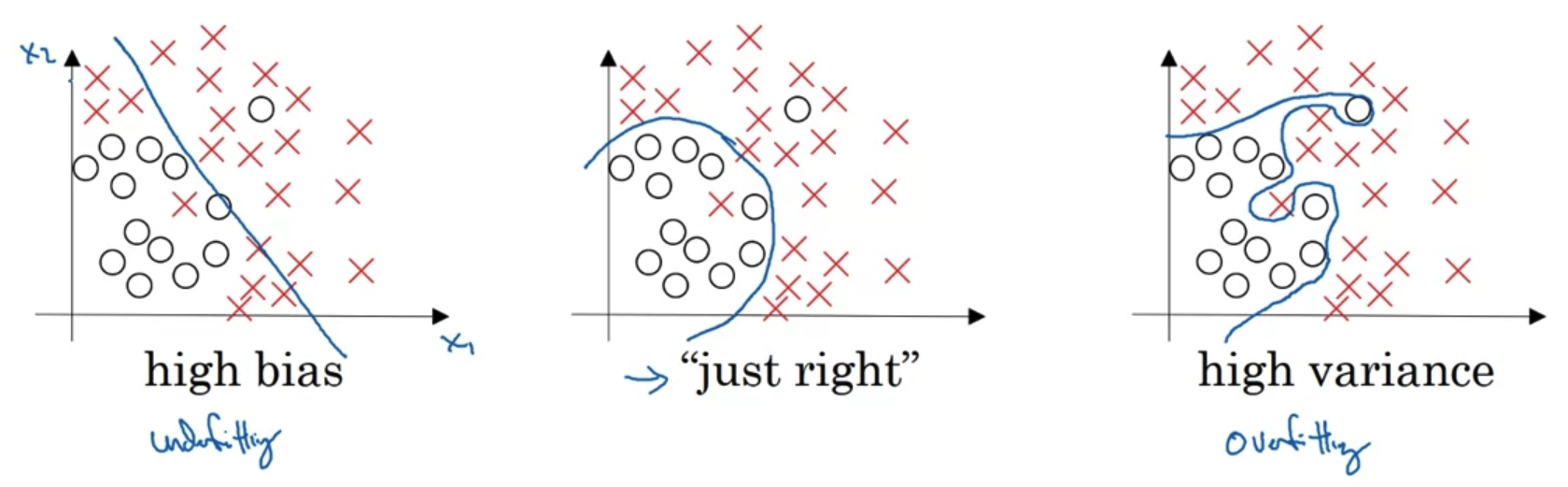
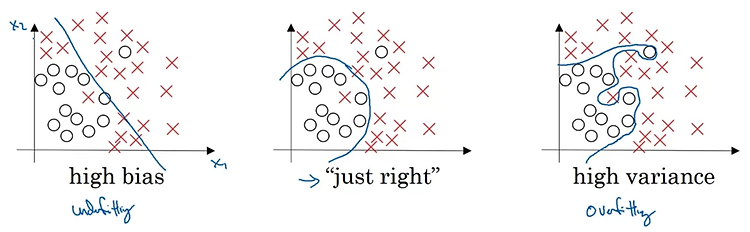
- 이번 시간에는 Bias와 Variance의 trade-off에 대해 배운다.
- regression 문제에 대해서 높은 bias를 지니는 경우(가장 왼쪽 그림), 실제 데이터에 적합한 추론이 이뤄지지 않는 'under-fitting'이 발생한다.
반대로 variance가 높은 경우 train set에만 지나치게 적합한 'over-fitting'이 발생한다. - 따라서 이상치에 대해서는 강건한(robust) 형태의 추론(inference)가 이뤄지는 것이 바람직하다.
중간의 그림을 본다면 각각 왼쪽그림의 bias와 오른쪽 그림의 variance를 줄여 합의를 본 상태로 이해할 수 있겠다.

- 개와 고양이를 분류하는 task를 가정해보자.
이때 train set error, dev set error를 임의로 설정하고 비교해본다.- 만약 train set error는 작고 dev set error는 큰 경우 이를 'high variance' 문제로 볼 수 있다.
즉 train set에만 적합한 학습을 수행한 'over-fitting'문제가 발생한 것이다. - 만약 train set error가 큰 편인데 dev set error가 이와 유사하다면 'high bias' 문제로 볼 수 있다.
두 error의 차이가 크지 않은 것은 바람직하지만, 주어진 train set에 대해 적절히 학습하지 못한 문제점을 갖고 있는 것이다. - 만약 두 error가 모두 크면서도 그 차이가 매우 큰 경우는 'high bais & high variance' 문제로 볼 수 있다.
최악의 경우인 것이다. - 만약 두 error가 모두 작으면서도 그 차이가 매우 작은 경우는 'low bias & low variance'로 볼 수 있다.
가장 이상적인 형태로 학습이 이뤄진 것이다.
- 만약 train set error는 작고 dev set error는 큰 경우 이를 'high variance' 문제로 볼 수 있다.
High bias and high variance
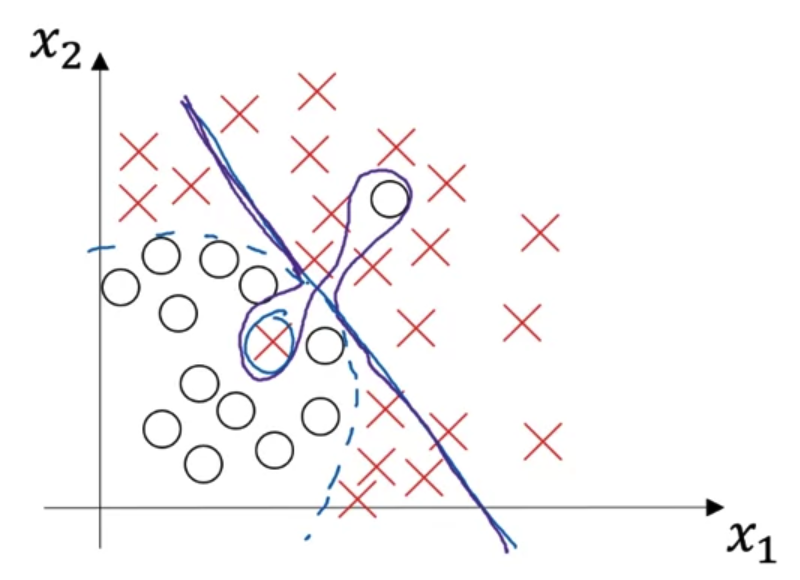
- 위에서 다룬 최악의 학습 형태는 표현하면 위의 '보라색 그래프'와 같이 된다.
- 'high bias'는 예측을 잘 하지 못한 것이므로 파란색 직선과 같이 대부분의 예측에 실패하는 형태로 나타난다.
그러면서도 'high variance'의 특징인 개별 요소에 지나치게 적합한 형태도 보인다.
즉, 여기서는 특정 두 개의 예측에 대해서만 아주 적합한 형태로 튀어나오는 것을 볼 수 있다.
3. Basic Recipe for Machine Learning
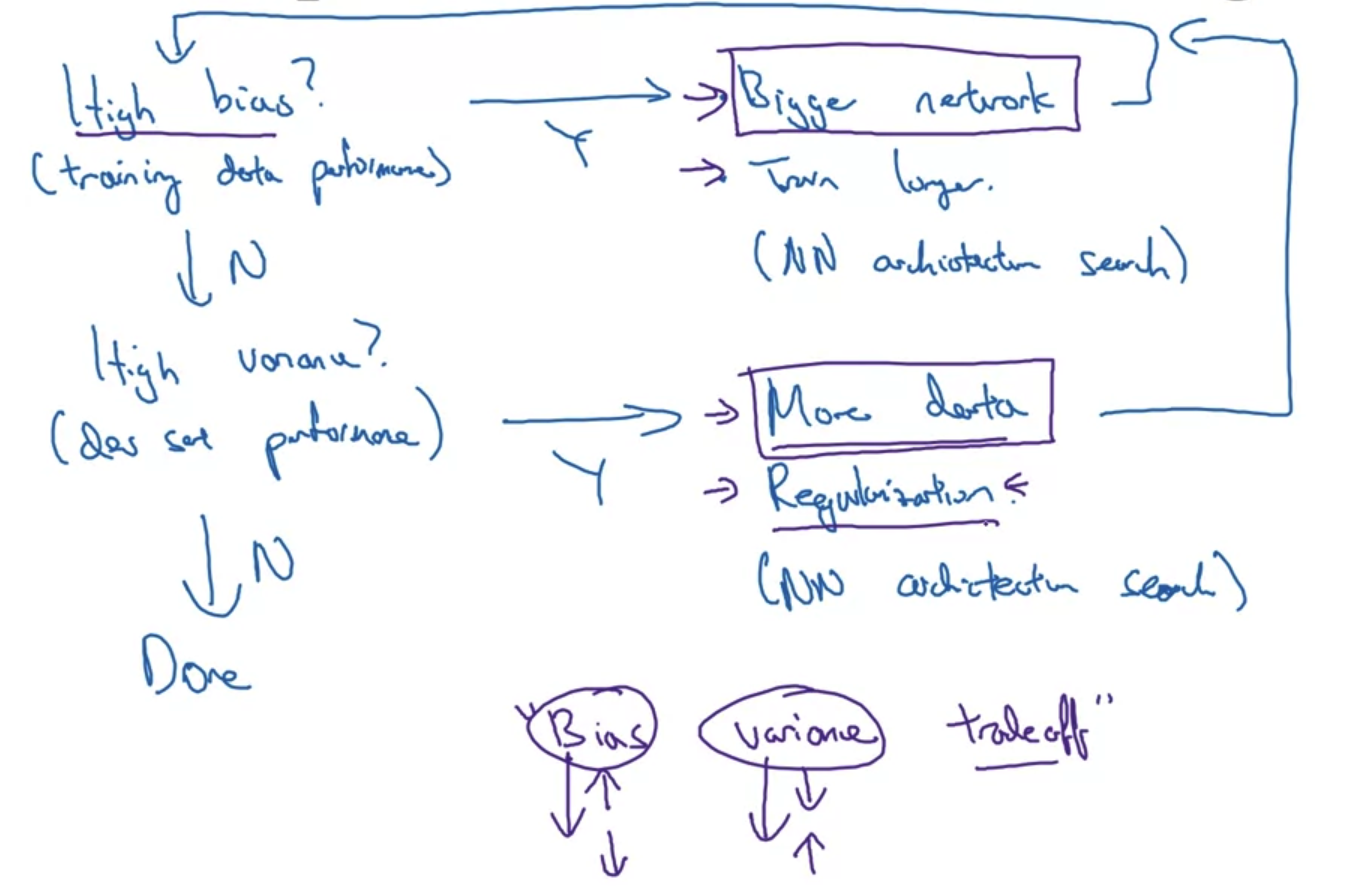
- High bias?
- bias가 높을 때는 training data performance를 향상시키는 방안을 생각해 볼 수 있다.
- bigger network를 사용하거나, train을 더 오래 해보거나, 더 적합한 Neural Network architecture를 찾아보는 것이 방법이 될 수 있다.
- High variance?
- variance가 높을 때는 dev set performance를 향항시키는 방안을 생각해 볼 수 있다.
- 더 많은 데이터를 사용하거나, regularization을 적용하거나, 마찬가지로 더 적합한 NN architecture를 찾아보는 것이 방법이 될 수 있다.
- 이전에는 Bias & Variance가 일종의 trade-off 관계라고 인식되었다.
즉, bias를 줄이면 variance가 커지고, 반대로 variance를 줄이면 bias가 커진다는 것이다. - 그러나 최근에는 더 많은 데이터를 사용하고 더 큰 network로 학습을 수행함으로써 bias와 variance 중 하나를 감소시키는 것이 반드시 반대쪽을 크게 만드는 것으로 이어지지 않게 되었다.
한마디로 bias와 variance를 동시에 줄이는 다양한 방법론들과 기술이 제시되었다는 것이다.
출처: Coursera, Improving Deep Neural Networks, DeepLearning.AI
'Improving Deep Neural Networks > 1주차' 카테고리의 다른 글
| Quiz & Assignments (0) | 2022.11.06 |
|---|---|
| Setting Up your Optimization(2) (0) | 2022.11.05 |
| Setting Up your Optimization Problem (0) | 2022.11.05 |
| Regularizing your Neural Network (2) | 2022.11.05 |
1. Train / Dev/ Test sets
Applied ML is a highly iterative process
- ML은 다양한 분야에 적용되고 있다.
NLP, CV, Speech Recognitoin, 등.. - 그러나 어떤 분야든지간에 Model에 대한 적합한 hyper parameter를 한 번에 구할 수는 없다.
전문가라 하더라도 위와 같은 cycle을 반복적으로 돌리면서 모델을 적절히 변경할 수 있게 되는 것이다.
Train/dev/test sets
- 우리는 전체 데이터셋을 흔히 train/dev/test 셋으로 나눈다.
train셋에서는 말 그대로 학습을 진행하고, dev셋에서는 우리가 학습시킨 알고리즘과 다른 알고리즘을 cross하여 비교할 수 있으며 test셋에서는 최고의 성능을 보였던 모델을 검증하는 것으로 이해할 수 있다. - 대규모 데이터를 다루기 이전의 시대에서는 train/test 셋으로만 나누며 그 비율을 7:3으로 주로 정했다.
train/dev/test셋으로 나누는 경우 6:2:2 의 비율로 구분하는 경향이 지배적이었다.
이때는 많아 봤자 10,000개 정도의 데이터를 취급했다. - 그러나 1M 개 이상의 데이터를 취급하는 요즘은 dev/test셋의 기존 목적을 유지하는 선에서 최대한 많은 양의 데이터를 train의 재료로 사용한다.
그래서 극단적인 경우 train/dev/test셋의 비율이 98:1:1, 혹은 99.5:0.4:0.1 수준으로 정해진다.
Mismatched train/test distribution
- train set과 dev/test set의 source가 다른 '잘못된 예시'를 설명하고 있다.
인터넷에서 크롤링한 데이터를 train에서 이용하고 유저들이 직접 올린 데이터를 dev/test에서 사용한다고 가정해보자.
이럴 경우 전자에서는 고해상도에 품질이 좋은 데이터가 주를 이룰 것이고 후자는 그렇지 않을 것이다.
결국 이런 데이터 구성은 모델이 좋은 성능을 가지는데 도움이 되지 않는다.(오히려 방해가 된다) - 따라서 데이터를 split할 때 가장 기본이 되는 원칙 중 하나는 "train/dev/test set"의 source가 동일해야 한다는 것이다.
- 때로는 우리의 모델이 unbiased한지 확인하는 test셋이 필요하지 않을 때도 있다.
이때는 사실상 train/dev셋으로만 구성이 되는데, 이를 train/test셋으로 표현하는 경우가 있다.
하지만 이때는 test셋이 사실 모델간의 성능을 비교하는 dev셋의 역할을 수행하고 있으므로 표현상의 mismatch에 휘둘리면 안 된다.
2. Bias/ Variance
Bias and Variance
- 이번 시간에는 Bias와 Variance의 trade-off에 대해 배운다.
- regression 문제에 대해서 높은 bias를 지니는 경우(가장 왼쪽 그림), 실제 데이터에 적합한 추론이 이뤄지지 않는 'under-fitting'이 발생한다.
반대로 variance가 높은 경우 train set에만 지나치게 적합한 'over-fitting'이 발생한다. - 따라서 이상치에 대해서는 강건한(robust) 형태의 추론(inference)가 이뤄지는 것이 바람직하다.
중간의 그림을 본다면 각각 왼쪽그림의 bias와 오른쪽 그림의 variance를 줄여 합의를 본 상태로 이해할 수 있겠다.
- 개와 고양이를 분류하는 task를 가정해보자.
이때 train set error, dev set error를 임의로 설정하고 비교해본다.- 만약 train set error는 작고 dev set error는 큰 경우 이를 'high variance' 문제로 볼 수 있다.
즉 train set에만 적합한 학습을 수행한 'over-fitting'문제가 발생한 것이다. - 만약 train set error가 큰 편인데 dev set error가 이와 유사하다면 'high bias' 문제로 볼 수 있다.
두 error의 차이가 크지 않은 것은 바람직하지만, 주어진 train set에 대해 적절히 학습하지 못한 문제점을 갖고 있는 것이다. - 만약 두 error가 모두 크면서도 그 차이가 매우 큰 경우는 'high bais & high variance' 문제로 볼 수 있다.
최악의 경우인 것이다. - 만약 두 error가 모두 작으면서도 그 차이가 매우 작은 경우는 'low bias & low variance'로 볼 수 있다.
가장 이상적인 형태로 학습이 이뤄진 것이다.
- 만약 train set error는 작고 dev set error는 큰 경우 이를 'high variance' 문제로 볼 수 있다.
High bias and high variance
- 위에서 다룬 최악의 학습 형태는 표현하면 위의 '보라색 그래프'와 같이 된다.
- 'high bias'는 예측을 잘 하지 못한 것이므로 파란색 직선과 같이 대부분의 예측에 실패하는 형태로 나타난다.
그러면서도 'high variance'의 특징인 개별 요소에 지나치게 적합한 형태도 보인다.
즉, 여기서는 특정 두 개의 예측에 대해서만 아주 적합한 형태로 튀어나오는 것을 볼 수 있다.
3. Basic Recipe for Machine Learning
- High bias?
- bias가 높을 때는 training data performance를 향상시키는 방안을 생각해 볼 수 있다.
- bigger network를 사용하거나, train을 더 오래 해보거나, 더 적합한 Neural Network architecture를 찾아보는 것이 방법이 될 수 있다.
- High variance?
- variance가 높을 때는 dev set performance를 향항시키는 방안을 생각해 볼 수 있다.
- 더 많은 데이터를 사용하거나, regularization을 적용하거나, 마찬가지로 더 적합한 NN architecture를 찾아보는 것이 방법이 될 수 있다.
- 이전에는 Bias & Variance가 일종의 trade-off 관계라고 인식되었다.
즉, bias를 줄이면 variance가 커지고, 반대로 variance를 줄이면 bias가 커진다는 것이다. - 그러나 최근에는 더 많은 데이터를 사용하고 더 큰 network로 학습을 수행함으로써 bias와 variance 중 하나를 감소시키는 것이 반드시 반대쪽을 크게 만드는 것으로 이어지지 않게 되었다.
한마디로 bias와 variance를 동시에 줄이는 다양한 방법론들과 기술이 제시되었다는 것이다.
출처: Coursera, Improving Deep Neural Networks, DeepLearning.AI
'Improving Deep Neural Networks > 1주차' 카테고리의 다른 글
| Quiz & Assignments (0) | 2022.11.06 |
|---|---|
| Setting Up your Optimization(2) (0) | 2022.11.05 |
| Setting Up your Optimization Problem (0) | 2022.11.05 |
| Regularizing your Neural Network (2) | 2022.11.05 |