
1. Mini-batch Gradient Descent
Match vs. mini-batch gradient descent

- 많은 양의 데이터를 처리해야 하는 딥러닝은 연산 시간을 줄이는 여러 기법들이 필요하다.
그 중 하나가 여러 데이터를 일부씩 묶어 계산하는 방식인 mini-batch gradient descent이다. - 만약 처리해야 하는 데이터의 개수가 5,000,000개라면 어떻게 될까?
이 많은 양의 데이터를 한꺼번에 forward하고 backward 하는 것은 엄청난 computing power를 필요로 할 것이고, 이것이 뒷받침된다고 하더라도 썩 좋은 시간적 효율을 보이진 못할 것이다. - 따라서 우리는 이를 일정 개수(위 예에서는 1,000개)씩 묵어서 연산을 시도하기로 한다.
이때 묶인 각 batch에 대한 표기를 위해서 { } 기호를 사용한다.
그리고 각 batch는 (nx, batch size)의 dimension을 갖는다.

- 위의 예시를 토대로 mini-batch gradient descent가 이루어지는 과정을 살펴보자.
- 만약 5,000,000개의 데이터를 1000개씩 묶어 처리한다면 5천 번의 연산이 필요할 것이다.
각 묶음(mini-batch)을 처리하는 한 번의 과정을 "step"이라고 부른다.
즉, 이 연산은 5000 step으로 이루어져 있다. - mini-batch로 묶인 데이터들은 이전에 배웠던 것처럼 for-loop을 사용하지 않고 vectorization을 통해 빠르게 연산한다.
- 모든 데이터들에 대해 gradient를 구하는 연산(back-propagation)까지 끝나게 되는 한 번의 과정을 "epoch"이라고 한다.
즉 1 epoch 동안 5,000 번의 step을 통해 가중치들의 업데이트가 한 번 일어나는 것이다. - 이런 과정 속에서도 cost를 계산하는데 regularization을 적용할 수 있다.
- loss나 accuracy가 원하는 수준으로 수렴할 때까지 epoch를 늘려 학습을 반복할 수 있다.
📄 1 epoch 동안 5,000 번의 step으로 학습을 하여 가중치 업데이트가 한 번 이뤄진다.
step은 데이터의 개수를 mini-batch size로 나눈 값이 된다.
2. Understanding Mini-batch Gradient Descent
Training with mini batch gradient descent

- iteration에 따른 cost를 그래프로 그리면 위와 같다.
- mini-batch를 적용하지 않은 batch gradient descent의 경우 상대적으로 smooth한 형태의 변화를 보여준다.
하지만 mini-batch를 적용하게 되면 약간 noisy한 형태의 그래프가 나타난다. - 이는 여러 개의 데이터를 묶을 경우 묶인 데이터의 특징에 따라 어떤 것은 loss를 많이 줄이기도 하고 어떤 것은 그렇지도 못할 수 있기 때문이다.
Choosing your mini-batch size
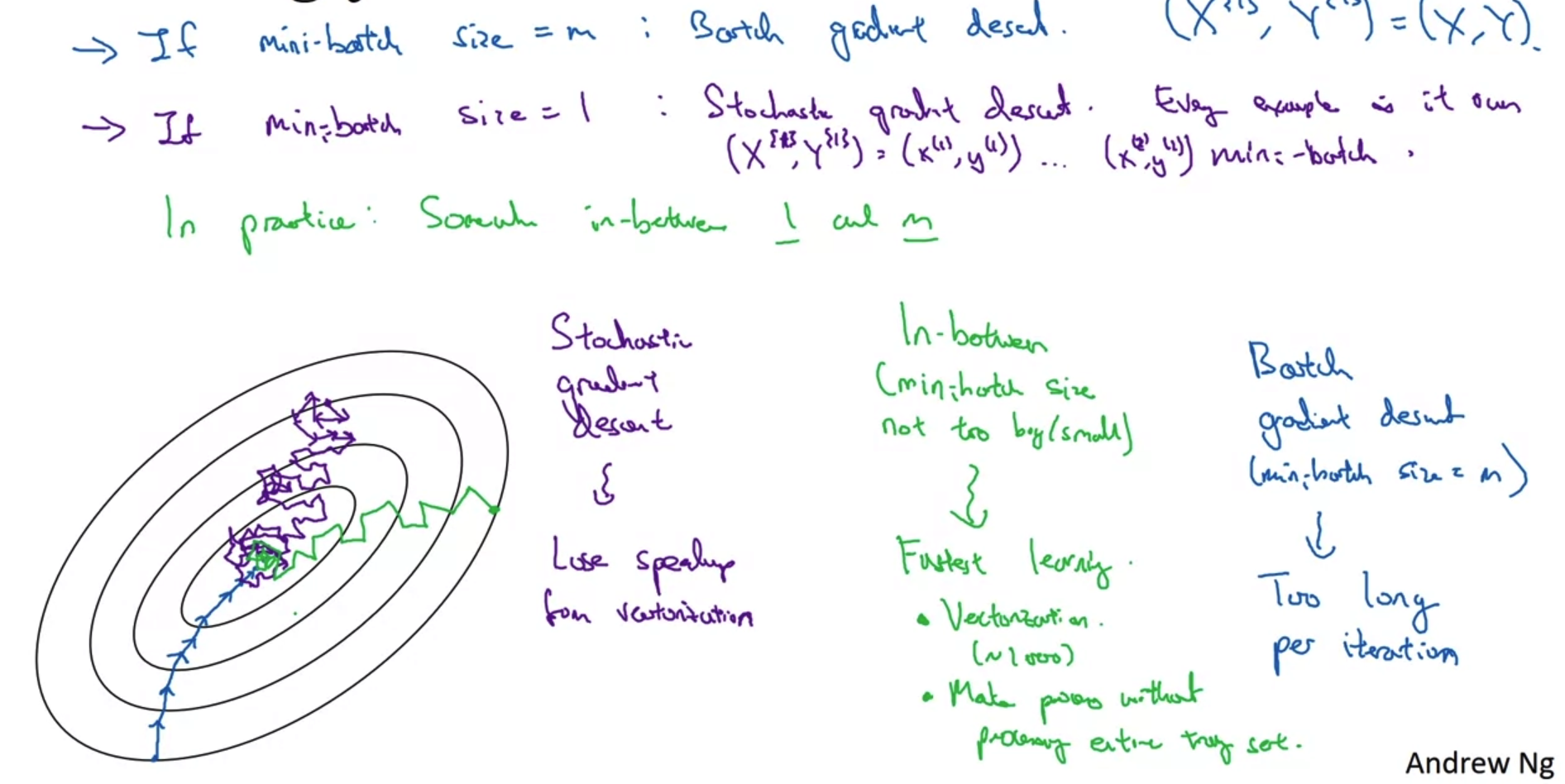
- 그렇다면 training sample을 몇 개씩 묶어서 계산하는 것이 가장 이상적인 방법일까?
- Batch gradient descent : mini-batch size = m
- 이때는 모든 training example을 한 번에 처리한다. 즉, 기존의 방식을 뜻한다.
- 이때는 학습이 반복됨에 따라 global minimum을 향해 곧은 방향으로 나아간다.
- 전체 데이터를 여러 번 학습해야 하므로 시간이 오래 걸린다는 단점이 있다.
- Stochastic gradient descent(확률적 경사하강법) : mini-batch size = 1
- 단 한 개씩의 training example을 계산하는 방식을 뜻한다.
- 각 example마다 학습이 이루어지므로 연산 속도가 아주 빠르다.
- 그러나 noisy가 아주 심한 방식이고 global minimum에 절대 수렴(converge)할 수 없는 방식이다.
- Mini-batch gradient descent : between 'Batch gradient descent' and 'Stochastic gradient descent'
- 극단적인 두 방식의 중간에 조화로우면서도 가장 효율적인 방식이다.
- 여러 training example에 대해 vectorize를 할 수 있어 연산 속도가 빠르면서도 global minimum을 향해 거의 수렴한다는 특징이 있다.
🔥 Mini-batch 방식은 batch size를 '적당히' 설정하여 '빠른 연산 속도'와 '정확성'이라는 두 마리 토끼를 잡은 방식이다.

- 만약 training set size가 2,000 이하로 굉장히 작은 편이라면 그냥 Batch gradient descent를 사용한다.
- 일반적인 mini-batch size는 '64, 128, 256, 512' 이다.
중요한 것은 내가 가진 CPU/GPU 메모리에 적절한 mini-batch size를 설정해야 한다는 점이다.
이는 정확히 조건을 따져 파악하기는 어려우므로 직접 여러 시도를 통해 적절한 값을 찾는 것이 중요하다.
(그렇기 때문에 mini-batch size도 일종의 hyper-parameter이다)
출처: Coursera, Improving Deep Neural Networks, DeepLearning.AI
'Improving Deep Neural Networks > 2주차' 카테고리의 다른 글
| Quiz & Programming Assignments (0) | 2022.11.13 |
|---|---|
| Optimization Algorithms(4) - Learning Rate Decay (0) | 2022.11.12 |
| Optimization Algorithms(3) - Gradient Descent (0) | 2022.11.10 |
| Optimization Algorithms(2) - Exponentially Weighted Averages (0) | 2022.11.09 |
1. Mini-batch Gradient Descent
Match vs. mini-batch gradient descent
- 많은 양의 데이터를 처리해야 하는 딥러닝은 연산 시간을 줄이는 여러 기법들이 필요하다.
그 중 하나가 여러 데이터를 일부씩 묶어 계산하는 방식인 mini-batch gradient descent이다. - 만약 처리해야 하는 데이터의 개수가 5,000,000개라면 어떻게 될까?
이 많은 양의 데이터를 한꺼번에 forward하고 backward 하는 것은 엄청난 computing power를 필요로 할 것이고, 이것이 뒷받침된다고 하더라도 썩 좋은 시간적 효율을 보이진 못할 것이다. - 따라서 우리는 이를 일정 개수(위 예에서는 1,000개)씩 묵어서 연산을 시도하기로 한다.
이때 묶인 각 batch에 대한 표기를 위해서 { } 기호를 사용한다.
그리고 각 batch는 (nx, batch size)의 dimension을 갖는다.
- 위의 예시를 토대로 mini-batch gradient descent가 이루어지는 과정을 살펴보자.
- 만약 5,000,000개의 데이터를 1000개씩 묶어 처리한다면 5천 번의 연산이 필요할 것이다.
각 묶음(mini-batch)을 처리하는 한 번의 과정을 "step"이라고 부른다.
즉, 이 연산은 5000 step으로 이루어져 있다. - mini-batch로 묶인 데이터들은 이전에 배웠던 것처럼 for-loop을 사용하지 않고 vectorization을 통해 빠르게 연산한다.
- 모든 데이터들에 대해 gradient를 구하는 연산(back-propagation)까지 끝나게 되는 한 번의 과정을 "epoch"이라고 한다.
즉 1 epoch 동안 5,000 번의 step을 통해 가중치들의 업데이트가 한 번 일어나는 것이다. - 이런 과정 속에서도 cost를 계산하는데 regularization을 적용할 수 있다.
- loss나 accuracy가 원하는 수준으로 수렴할 때까지 epoch를 늘려 학습을 반복할 수 있다.
📄 1 epoch 동안 5,000 번의 step으로 학습을 하여 가중치 업데이트가 한 번 이뤄진다.
step은 데이터의 개수를 mini-batch size로 나눈 값이 된다.
2. Understanding Mini-batch Gradient Descent
Training with mini batch gradient descent
- iteration에 따른 cost를 그래프로 그리면 위와 같다.
- mini-batch를 적용하지 않은 batch gradient descent의 경우 상대적으로 smooth한 형태의 변화를 보여준다.
하지만 mini-batch를 적용하게 되면 약간 noisy한 형태의 그래프가 나타난다. - 이는 여러 개의 데이터를 묶을 경우 묶인 데이터의 특징에 따라 어떤 것은 loss를 많이 줄이기도 하고 어떤 것은 그렇지도 못할 수 있기 때문이다.
Choosing your mini-batch size
- 그렇다면 training sample을 몇 개씩 묶어서 계산하는 것이 가장 이상적인 방법일까?
- Batch gradient descent : mini-batch size = m
- 이때는 모든 training example을 한 번에 처리한다. 즉, 기존의 방식을 뜻한다.
- 이때는 학습이 반복됨에 따라 global minimum을 향해 곧은 방향으로 나아간다.
- 전체 데이터를 여러 번 학습해야 하므로 시간이 오래 걸린다는 단점이 있다.
- Stochastic gradient descent(확률적 경사하강법) : mini-batch size = 1
- 단 한 개씩의 training example을 계산하는 방식을 뜻한다.
- 각 example마다 학습이 이루어지므로 연산 속도가 아주 빠르다.
- 그러나 noisy가 아주 심한 방식이고 global minimum에 절대 수렴(converge)할 수 없는 방식이다.
- Mini-batch gradient descent : between 'Batch gradient descent' and 'Stochastic gradient descent'
- 극단적인 두 방식의 중간에 조화로우면서도 가장 효율적인 방식이다.
- 여러 training example에 대해 vectorize를 할 수 있어 연산 속도가 빠르면서도 global minimum을 향해 거의 수렴한다는 특징이 있다.
🔥 Mini-batch 방식은 batch size를 '적당히' 설정하여 '빠른 연산 속도'와 '정확성'이라는 두 마리 토끼를 잡은 방식이다.
- 만약 training set size가 2,000 이하로 굉장히 작은 편이라면 그냥 Batch gradient descent를 사용한다.
- 일반적인 mini-batch size는 '64, 128, 256, 512' 이다.
중요한 것은 내가 가진 CPU/GPU 메모리에 적절한 mini-batch size를 설정해야 한다는 점이다.
이는 정확히 조건을 따져 파악하기는 어려우므로 직접 여러 시도를 통해 적절한 값을 찾는 것이 중요하다.
(그렇기 때문에 mini-batch size도 일종의 hyper-parameter이다)
출처: Coursera, Improving Deep Neural Networks, DeepLearning.AI
'Improving Deep Neural Networks > 2주차' 카테고리의 다른 글
| Quiz & Programming Assignments (0) | 2022.11.13 |
|---|---|
| Optimization Algorithms(4) - Learning Rate Decay (0) | 2022.11.12 |
| Optimization Algorithms(3) - Gradient Descent (0) | 2022.11.10 |
| Optimization Algorithms(2) - Exponentially Weighted Averages (0) | 2022.11.09 |