
SQuAD는 Stanford Question Answering Dataset의 약자로, 스탠포드 대학에서 QA를 위해 제작한 데이터셋입니다.
논문을 직접 읽어보고 싶으시다면 SQuAD: 100,000+ Questions for Machine Comprehension of Text 라는 제목의 논문을 직접 보실 수 있습니다.
(https://arxiv.org/abs/1606.05250)
저는 MRC(Machine Reading Comprehension)에 관한 프로젝트를 진행하면서 학습과 평가 데이터셋으로 사용되는 SQuAD에 대해 자세히 알고 싶어서 이 논문을 읽어봤습니다.
Question Answering과 관련한 여러 논문에서 이 데이터셋을 모델의 성능을 평가하는 지표로 자주 활용합니다.
본 포스팅은 위 논문을 읽고 해석한 내용을 챕터별로 정리한 것으로, 주관적인 해석은 최대한 배제했습니다.
영어로 논문 보는게 부담스러우시거나 정리된 내용만을 빠르게 보고 싶으신 분들을 위해 정리된 글이므로 좀 더 깊은 내용을 알기 원하시는 분들은 관련된 논문을 추가로 찾아보시는 것을 추천드립니다 🙃
Contents
1️⃣ Introduction
2️⃣ Existing Datasets
3️⃣ Dataset Collection
4️⃣ Dataset Analysis
5️⃣ Methods
6️⃣ Experiments
7️⃣ Conclusion
1️⃣ Introduction (SQuAD에 대한 포괄적 설명)
Reading Comprehension(RC)
기계가 text를 읽고 이 내용에 대한 질문에 대답을 할 수 있도록 만드는 것은 어려운 task입니다. 이 task에는 natural language와 세상에 대한 (배경)지식을 이해하는 것이 전제되기 때문입니다.
- large, realistic dataset을 사용하여 해당 분야가 발전되어온 것은 명백한 사실입니다.
즉, 본 논문에서는 이전보다 큰 size의, 그리고 현실적인 데이터를 담은 dataset을 구축했다는 것입니다. - 본 논문에서는 (당시에) 존재하던 dataset의 두 가지 단점을 지적합니다.
- 최근의 data-intensive model이 학습을 하기에는 그 size가 너무 작다.
- semi-synthetic하며 명시적인 reading comprehension question이 가지는 특징들을 공유하고 있지 못한다.
⇒ 이런 문제점들을 해결하기 위해 제시된 SQuAD는 다음과 같은 특징을 가집니다.
- Wikipedia article로부터 data를 수집하되 crowdworker이 작업을 수행했습니다.
- 기존의 labeld RC dataset에 비해 수십배는 더 큰 dataset입니다.
- passage 내의 possible spans(답안 후보) 중에서 답을 선택해야 하는 방식을 취했습니다. → 그럼에도 질문과 답변 유형의 다양성을 유지합니다. → free-form answer에 비해 평가하기 쉽습니다.
- SQuAD의 난이도를 평가하기 위해 logistic regression model을 사용했습니다.
- answer type이 다양할수록 그 성능이 떨어집니다.
- 질문과 답변의 syntactic divergence가 성능 하락에 영향을 줍니다.
2️⃣ Existing Datasets (기존 데이터셋과의 비교)
① Reading comprehension
- RC를 위해 제작된 기존의 dataset들은 위에서 언급한 바와 같이 그 크기가 작다는 문제점이 있다고 지적합니다.
- 단순히 그 크기가 작다는 것이 아니라, 본 task를 잘 수행하기 위해서는 expressive statistical model에 적합한 양의 data가 필요하다는 점을 언급합니다.
- 그 이유는 question에 적합한 answer를 찾아내기 위해서는 commonsense reasoning, 즉 상식적 추론이 가능해야하기 때문입니다.
- Clark and Etzioni(2016)의 논문에서도 world knowledge에 대한 추론이 필요함을 강조하고 있습니다.
② Open-domain question answering
open-domain QA의 목표는 대량의 문서로부터 질문에 대한 정답을 추출하는 것입니다.
- 이전에 구축된 dataset들처럼 SQuAD도 Wikipedia의 passage를 정답의 근거로 사용합니다.
- 단, 단순히 문장 자체를 구분했던 이전 dataset들과 달리 speicific span을 파악하는 것을 목표로 합니다.
- 그렇기 때문에 ODQA pipeline의 마지막인 스텝인 answer extraction으로도 이해할 수 있습니다.
- SQuAD에서 가장 큰 영향을 미치는 두 요인은 다음과 같습니다.
- dependency trees
- factor graph
③ Cloze datasets
missing word를 예측하는 것을 목표로 삼는 dataset입니다.
- CNN / Daily New article의 요약 정보 일부를 blanking out했습니다.
- SQuAD는 이 dataset보다 훨씬 긴 phrase와 non-entity까지도 포함한다는 특징이 있습니다.
- 또한 passage에 정답 정보가 수반되는 질문들에 집중하는 방식을 취했다는 특징이 있습니다.
3️⃣ Dataset Collection
① Passage curation
- Project Nayuki’s Wikipedia’s internal PageRanks에서 top 10,000 개의 article을 수집하고 여기서 536개의 article을 random하게 추출했습니다.
- 총 536개의 article에서 23,215개의 paragraphs를 data로 사용하게 됩니다.
② Question-answer collection
- crowdworkers들을 고용하여 질문을 생성했습니다.
- 최소 97%의 HIT acceptance rate, 최소 1,000개의 HIT을 기준으로 잡고 작업을 진행했다고 합니다.
- 각 paragraph에서 5개의 질문을 만들고 답변하도록 했습니다.
- 추가로 작업자들은 paragrph의 단어나 표현을 그대로 베낄 수 없도록 copy-paste는 막아 두었고, 자신만의 표현으로 질문에 답변하도록 했습니다.
③ Additional answers collection
- development / test set에 대해서는 각 질문에 대해 2개의 추가 답변을 생성하도록 했습니다.
- 이때는 질문에 대해 답을 할 수 있는 가장 짧은 span의 paragrph를 고르도록 했습니다.
- 작업자들은 2분에 5개의 답변을 생성하도록 지시 받았습니다. 최종 결과물은 아래 표를 참고할 수 있습니다.
4️⃣ Dataset Analysis
본 논문에서 중점적으로 다룬 요소는 다음 세 가지입니다.
- 정답 유형의 다양성
- 질문의 난이도
- syntactic divergence의 정도
① Diversity in answers
- 우선 numerical / non-numerical 정답으로 구분합니다.
- non-numerical 정답은 constituency parse와 POS tag를 이용하여 분류합니다.
- 적절한 형태의 noun phrase는 person, location, other entities로 구분됩니다.
- 이때는 NER tag를 이용합니다.
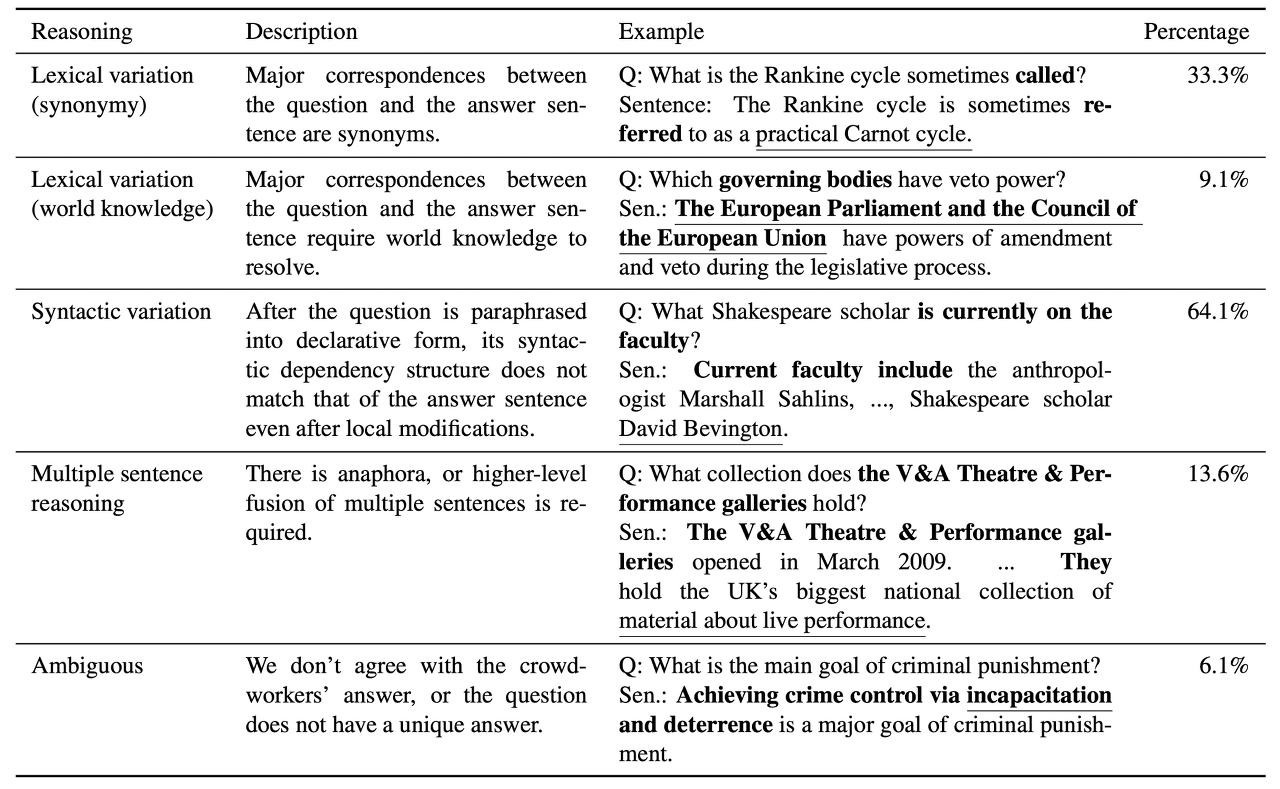
② Reasoning required to answer questions
- 추론 결과에 대한 검증을 위해 48개의 aritcle에서 각각 4개의 질문을 sampling 했습니다.
- 다음 표의 결과는 질문과 답변 사이의 syntactic divergence를 보여줍니다.
③ Stratification by syntactic divergence
- 질문과 답변의 syntactic divergence를 자동적으로 수치화 할 수 있도록 했습니다.
- 문장 내에서 anchor(닻, 기준)를 탐지합니다. 이는 dependency parse tree에서 추출한 결과입니다.
- 질문과 답변 사이의 최소한의 삭제 혹은 삽입의 횟수를 syntactic divergence의 값으로 갖습니다. 즉, minimum edit distance를 사용하는 것입니다.
- 이때 lexical variation은 고려하지 않습니다.
5️⃣ Methods
logistic regression model을 사용하고 세 개의 baseline methods와 그 결과를 비교합니다.
① Sliding Window Baseline
- 각각의 정답 후보에 대해 unigram과 bigram의 중첩 정도를 계산합니다.
- 이 중첩이 최대가 될 수 있도록 정답을 선정합니다.
- 또한 distanced-based extension을 적용합니다.
② Logistic Regression
- 각각의 정답 후보에 대해 몇몇 features 추출합니다. 그리고 이 연속적인 features를 10개의 동일한 사이즈의 bucket으로 분할합니다.
- 총 180 million(18억)개의 feature를 얻을 수 있습니다.
- 대부분은 lexicalied feature 이거나 dependency tree path의 feature입니다.
- 여러 feature 중에서 모델이 올바른 정답 유형을 고르는 데 영향을 주는 feature는 다음과 같습니다.
- matching word
- bigram frequency
- constituent label
- span POS tag
- 그 중에서도 lexicalized feature, dependency tree path feature를 사용한 것이 이 논문에서의 핵심입니다.
- multiclass에 대한 log-likelihood loss는 AdaGrad를 통해 최적화 합니다.
- 다음 표는 각 feature와 그에 따른 description을 정리한 것입니다.
6️⃣ Experiments
① Model Evaluation (metric)
본 논문에서는 두 개의 metric을 사용합니다. 두 metric 모두 punctuation과 article은 취급하지 않습니다.
- Exact match : ground truth answer와 prediction이 얼마나 일치하는지 측정합니다.
- (Macro-averaged) F1 socre : ground truth answer와 prediction의 중첩 평균치를 구합니다.
② Human Performance
SQuAD의 development / test set에 대해 human performance를 측정한 결과입니다.
- testset에 대해서..
- Exact mathc : 77.0%
- F1 score : 86.8%
- mismatch가 일어난 원인은 정답에 대한 근본적인 불일치보다는 비본질적인 구문들 때문입니다.
- 사소한 표현의 포함 유무가 score를 떨어뜨린 것으로 이해할 수 있습니다.
③ Model Performance
logistic regression model은 다른 baselines에 비해 우수한 성능을 보입니다. 하지만 human performance에는 한참 미치지 못합니다.
- 그 이유는 문장 내의 specific span을 찾는 task의 난이도 때문이라고 보입니다.
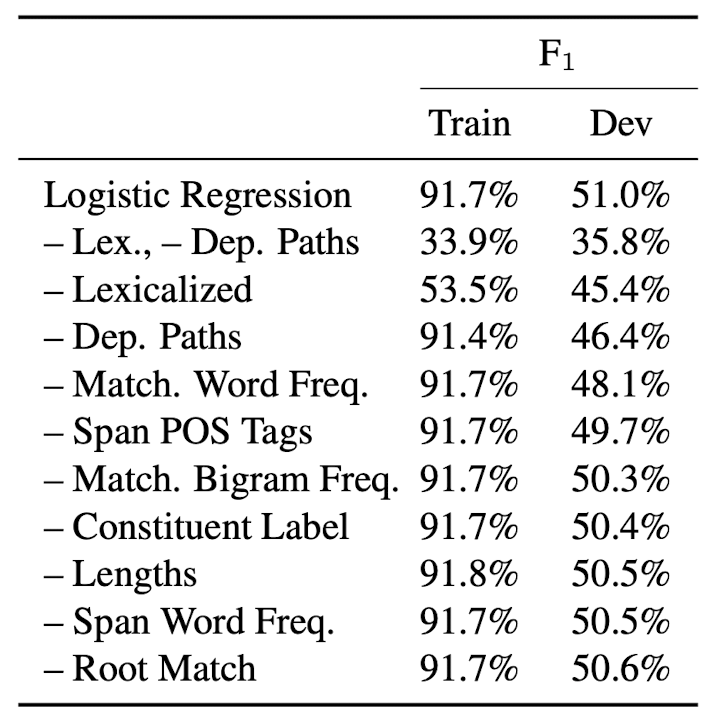
④ Feature ablations (feature 제거 기법)
어떤 feature가 performance에 큰 영향을 미치고 있는지 확인하기 위해 한 feature씩 제거하면서 그때의 performance를 비교분석합니다.
- 위에서 반복적으로 언급했던 것처럼 lexicalized feature와 dependency tree path feature가 가장 큰 영향을 미칩니다.
- lexcialized feature로 인해 training set에 대해 overfitting이 발생하는 경향이 있음도 주목할 만한 현상입니다.
- 그런다고 해서 L2 regularization을 강화하게 되면 모델의 성능이 하락하는 결과로 이어지게 됩니다.
⑤ Performance stratified by answer type
더 많은 insight를 얻기 위해 logistic regression model의 결과를 answer type에 따라 구분했습니다.
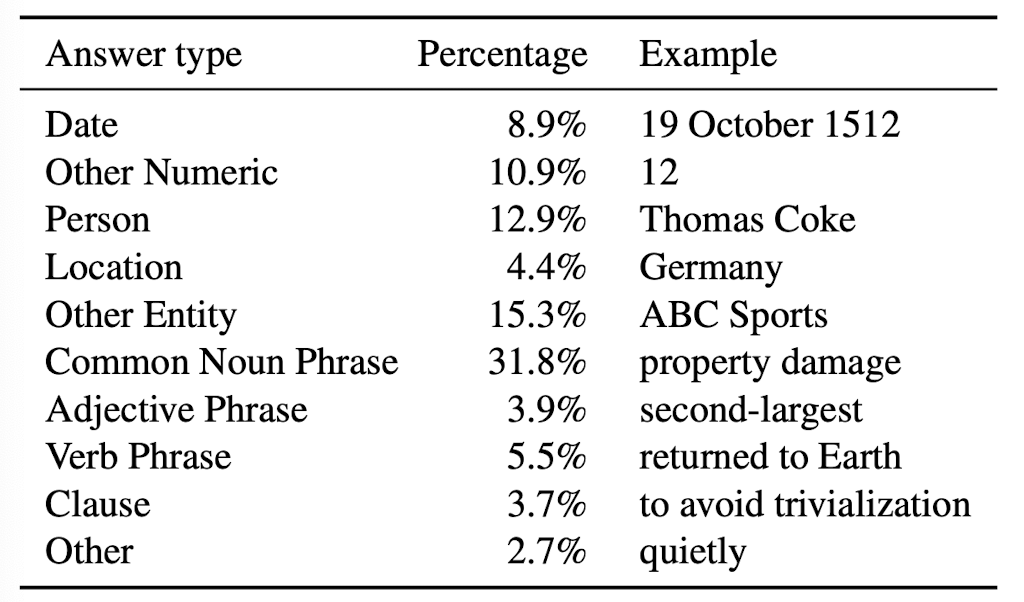
- 그럴싸한 정답 후보가 많지 않거나 대부분의 정답이 single token인 dates나 숫자 관련 카테고리에서 우수한 성능을 보인다는 것을 알 수 있습니다.
- 반대로 정답 후보가 여러 개 존재하는 경우에 대해서는 보다 challenging하게 학습했음을 알 수 있습니다.
⑥ Performance stratified by syntactic divergence
syntactic divergence를 기준으로 human performance와 비교했을 때, 앞으로의 발전 여지가 많이 남았다고 볼 수 있습니다.
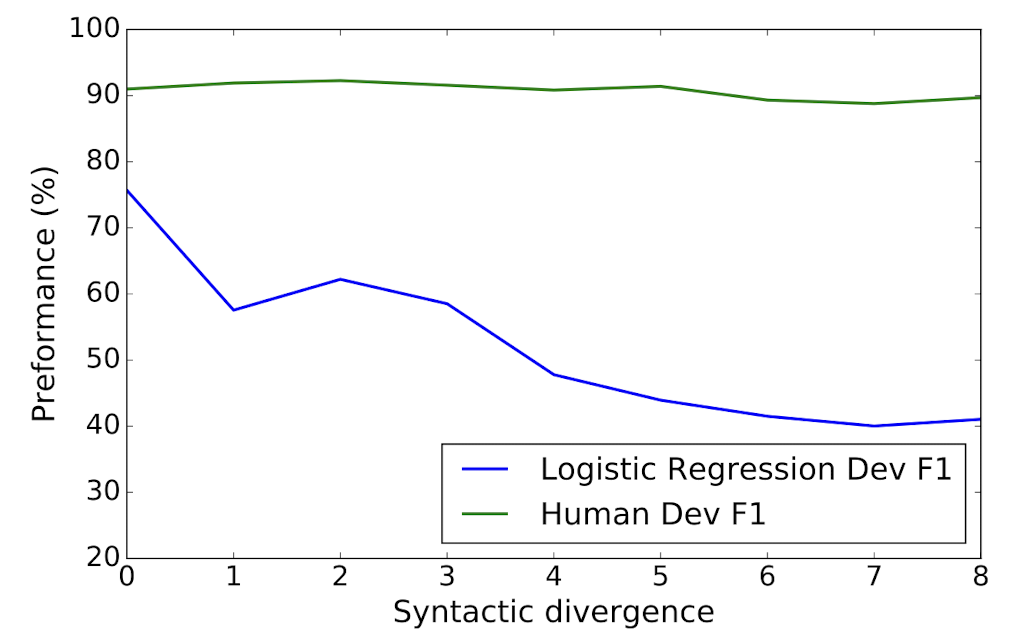
- logistic regression model의 경우 syntactic divergence가 심해질수록 그 성능 저하가 급격합니다. 이와 달리 human performance는 syntactic divergence와 거의 무관하게 유지되고 있음이 확인 가능합니다.
- 따라서 syntactic divergence가 심한, 즉 모델의 입장에서 해결하기에 난이도가 높은 문제를 더 잘 처리하게 만들기 위한 여지가 많이 남았다는 뜻입니다.
7️⃣ Conclusion
- SQuAD : Stanford Question Answering Dataset for Reading Comprehension
- Wikipedia articles with crowdsourced question-answer pairs
- Logistic regression model : 51.0% F1 score Human : 86.8% F1 score
출처 : SQuAD: 100,000+ Questions for Machine Comprehension of Text
'Paper Review' 카테고리의 다른 글
SQuAD는 Stanford Question Answering Dataset의 약자로, 스탠포드 대학에서 QA를 위해 제작한 데이터셋입니다.
논문을 직접 읽어보고 싶으시다면 SQuAD: 100,000+ Questions for Machine Comprehension of Text 라는 제목의 논문을 직접 보실 수 있습니다.
(https://arxiv.org/abs/1606.05250)
저는 MRC(Machine Reading Comprehension)에 관한 프로젝트를 진행하면서 학습과 평가 데이터셋으로 사용되는 SQuAD에 대해 자세히 알고 싶어서 이 논문을 읽어봤습니다.
Question Answering과 관련한 여러 논문에서 이 데이터셋을 모델의 성능을 평가하는 지표로 자주 활용합니다.
본 포스팅은 위 논문을 읽고 해석한 내용을 챕터별로 정리한 것으로, 주관적인 해석은 최대한 배제했습니다.
영어로 논문 보는게 부담스러우시거나 정리된 내용만을 빠르게 보고 싶으신 분들을 위해 정리된 글이므로 좀 더 깊은 내용을 알기 원하시는 분들은 관련된 논문을 추가로 찾아보시는 것을 추천드립니다 🙃
Contents
1️⃣ Introduction
2️⃣ Existing Datasets
3️⃣ Dataset Collection
4️⃣ Dataset Analysis
5️⃣ Methods
6️⃣ Experiments
7️⃣ Conclusion
1️⃣ Introduction (SQuAD에 대한 포괄적 설명)
Reading Comprehension(RC)
기계가 text를 읽고 이 내용에 대한 질문에 대답을 할 수 있도록 만드는 것은 어려운 task입니다. 이 task에는 natural language와 세상에 대한 (배경)지식을 이해하는 것이 전제되기 때문입니다.
- large, realistic dataset을 사용하여 해당 분야가 발전되어온 것은 명백한 사실입니다.
즉, 본 논문에서는 이전보다 큰 size의, 그리고 현실적인 데이터를 담은 dataset을 구축했다는 것입니다. - 본 논문에서는 (당시에) 존재하던 dataset의 두 가지 단점을 지적합니다.
- 최근의 data-intensive model이 학습을 하기에는 그 size가 너무 작다.
- semi-synthetic하며 명시적인 reading comprehension question이 가지는 특징들을 공유하고 있지 못한다.
⇒ 이런 문제점들을 해결하기 위해 제시된 SQuAD는 다음과 같은 특징을 가집니다.
- Wikipedia article로부터 data를 수집하되 crowdworker이 작업을 수행했습니다.
- 기존의 labeld RC dataset에 비해 수십배는 더 큰 dataset입니다.
- passage 내의 possible spans(답안 후보) 중에서 답을 선택해야 하는 방식을 취했습니다. → 그럼에도 질문과 답변 유형의 다양성을 유지합니다. → free-form answer에 비해 평가하기 쉽습니다.
- SQuAD의 난이도를 평가하기 위해 logistic regression model을 사용했습니다.
- answer type이 다양할수록 그 성능이 떨어집니다.
- 질문과 답변의 syntactic divergence가 성능 하락에 영향을 줍니다.
2️⃣ Existing Datasets (기존 데이터셋과의 비교)
① Reading comprehension
- RC를 위해 제작된 기존의 dataset들은 위에서 언급한 바와 같이 그 크기가 작다는 문제점이 있다고 지적합니다.
- 단순히 그 크기가 작다는 것이 아니라, 본 task를 잘 수행하기 위해서는 expressive statistical model에 적합한 양의 data가 필요하다는 점을 언급합니다.
- 그 이유는 question에 적합한 answer를 찾아내기 위해서는 commonsense reasoning, 즉 상식적 추론이 가능해야하기 때문입니다.
- Clark and Etzioni(2016)의 논문에서도 world knowledge에 대한 추론이 필요함을 강조하고 있습니다.
② Open-domain question answering
open-domain QA의 목표는 대량의 문서로부터 질문에 대한 정답을 추출하는 것입니다.
- 이전에 구축된 dataset들처럼 SQuAD도 Wikipedia의 passage를 정답의 근거로 사용합니다.
- 단, 단순히 문장 자체를 구분했던 이전 dataset들과 달리 speicific span을 파악하는 것을 목표로 합니다.
- 그렇기 때문에 ODQA pipeline의 마지막인 스텝인 answer extraction으로도 이해할 수 있습니다.
- SQuAD에서 가장 큰 영향을 미치는 두 요인은 다음과 같습니다.
- dependency trees
- factor graph
③ Cloze datasets
missing word를 예측하는 것을 목표로 삼는 dataset입니다.
- CNN / Daily New article의 요약 정보 일부를 blanking out했습니다.
- SQuAD는 이 dataset보다 훨씬 긴 phrase와 non-entity까지도 포함한다는 특징이 있습니다.
- 또한 passage에 정답 정보가 수반되는 질문들에 집중하는 방식을 취했다는 특징이 있습니다.
3️⃣ Dataset Collection
① Passage curation
- Project Nayuki’s Wikipedia’s internal PageRanks에서 top 10,000 개의 article을 수집하고 여기서 536개의 article을 random하게 추출했습니다.
- 총 536개의 article에서 23,215개의 paragraphs를 data로 사용하게 됩니다.
② Question-answer collection
- crowdworkers들을 고용하여 질문을 생성했습니다.
- 최소 97%의 HIT acceptance rate, 최소 1,000개의 HIT을 기준으로 잡고 작업을 진행했다고 합니다.
- 각 paragraph에서 5개의 질문을 만들고 답변하도록 했습니다.
- 추가로 작업자들은 paragrph의 단어나 표현을 그대로 베낄 수 없도록 copy-paste는 막아 두었고, 자신만의 표현으로 질문에 답변하도록 했습니다.
③ Additional answers collection
- development / test set에 대해서는 각 질문에 대해 2개의 추가 답변을 생성하도록 했습니다.
- 이때는 질문에 대해 답을 할 수 있는 가장 짧은 span의 paragrph를 고르도록 했습니다.
- 작업자들은 2분에 5개의 답변을 생성하도록 지시 받았습니다. 최종 결과물은 아래 표를 참고할 수 있습니다.
4️⃣ Dataset Analysis
본 논문에서 중점적으로 다룬 요소는 다음 세 가지입니다.
- 정답 유형의 다양성
- 질문의 난이도
- syntactic divergence의 정도
① Diversity in answers
- 우선 numerical / non-numerical 정답으로 구분합니다.
- non-numerical 정답은 constituency parse와 POS tag를 이용하여 분류합니다.
- 적절한 형태의 noun phrase는 person, location, other entities로 구분됩니다.
- 이때는 NER tag를 이용합니다.
② Reasoning required to answer questions
- 추론 결과에 대한 검증을 위해 48개의 aritcle에서 각각 4개의 질문을 sampling 했습니다.
- 다음 표의 결과는 질문과 답변 사이의 syntactic divergence를 보여줍니다.
③ Stratification by syntactic divergence
- 질문과 답변의 syntactic divergence를 자동적으로 수치화 할 수 있도록 했습니다.
- 문장 내에서 anchor(닻, 기준)를 탐지합니다. 이는 dependency parse tree에서 추출한 결과입니다.
- 질문과 답변 사이의 최소한의 삭제 혹은 삽입의 횟수를 syntactic divergence의 값으로 갖습니다. 즉, minimum edit distance를 사용하는 것입니다.
- 이때 lexical variation은 고려하지 않습니다.
5️⃣ Methods
logistic regression model을 사용하고 세 개의 baseline methods와 그 결과를 비교합니다.
① Sliding Window Baseline
- 각각의 정답 후보에 대해 unigram과 bigram의 중첩 정도를 계산합니다.
- 이 중첩이 최대가 될 수 있도록 정답을 선정합니다.
- 또한 distanced-based extension을 적용합니다.
② Logistic Regression
- 각각의 정답 후보에 대해 몇몇 features 추출합니다. 그리고 이 연속적인 features를 10개의 동일한 사이즈의 bucket으로 분할합니다.
- 총 180 million(18억)개의 feature를 얻을 수 있습니다.
- 대부분은 lexicalied feature 이거나 dependency tree path의 feature입니다.
- 여러 feature 중에서 모델이 올바른 정답 유형을 고르는 데 영향을 주는 feature는 다음과 같습니다.
- matching word
- bigram frequency
- constituent label
- span POS tag
- 그 중에서도 lexicalized feature, dependency tree path feature를 사용한 것이 이 논문에서의 핵심입니다.
- multiclass에 대한 log-likelihood loss는 AdaGrad를 통해 최적화 합니다.
- 다음 표는 각 feature와 그에 따른 description을 정리한 것입니다.
6️⃣ Experiments
① Model Evaluation (metric)
본 논문에서는 두 개의 metric을 사용합니다. 두 metric 모두 punctuation과 article은 취급하지 않습니다.
- Exact match : ground truth answer와 prediction이 얼마나 일치하는지 측정합니다.
- (Macro-averaged) F1 socre : ground truth answer와 prediction의 중첩 평균치를 구합니다.
② Human Performance
SQuAD의 development / test set에 대해 human performance를 측정한 결과입니다.
- testset에 대해서..
- Exact mathc : 77.0%
- F1 score : 86.8%
- mismatch가 일어난 원인은 정답에 대한 근본적인 불일치보다는 비본질적인 구문들 때문입니다.
- 사소한 표현의 포함 유무가 score를 떨어뜨린 것으로 이해할 수 있습니다.
③ Model Performance
logistic regression model은 다른 baselines에 비해 우수한 성능을 보입니다. 하지만 human performance에는 한참 미치지 못합니다.
- 그 이유는 문장 내의 specific span을 찾는 task의 난이도 때문이라고 보입니다.
④ Feature ablations (feature 제거 기법)
어떤 feature가 performance에 큰 영향을 미치고 있는지 확인하기 위해 한 feature씩 제거하면서 그때의 performance를 비교분석합니다.
- 위에서 반복적으로 언급했던 것처럼 lexicalized feature와 dependency tree path feature가 가장 큰 영향을 미칩니다.
- lexcialized feature로 인해 training set에 대해 overfitting이 발생하는 경향이 있음도 주목할 만한 현상입니다.
- 그런다고 해서 L2 regularization을 강화하게 되면 모델의 성능이 하락하는 결과로 이어지게 됩니다.
⑤ Performance stratified by answer type
더 많은 insight를 얻기 위해 logistic regression model의 결과를 answer type에 따라 구분했습니다.
- 그럴싸한 정답 후보가 많지 않거나 대부분의 정답이 single token인 dates나 숫자 관련 카테고리에서 우수한 성능을 보인다는 것을 알 수 있습니다.
- 반대로 정답 후보가 여러 개 존재하는 경우에 대해서는 보다 challenging하게 학습했음을 알 수 있습니다.
⑥ Performance stratified by syntactic divergence
syntactic divergence를 기준으로 human performance와 비교했을 때, 앞으로의 발전 여지가 많이 남았다고 볼 수 있습니다.
- logistic regression model의 경우 syntactic divergence가 심해질수록 그 성능 저하가 급격합니다. 이와 달리 human performance는 syntactic divergence와 거의 무관하게 유지되고 있음이 확인 가능합니다.
- 따라서 syntactic divergence가 심한, 즉 모델의 입장에서 해결하기에 난이도가 높은 문제를 더 잘 처리하게 만들기 위한 여지가 많이 남았다는 뜻입니다.
7️⃣ Conclusion
- SQuAD : Stanford Question Answering Dataset for Reading Comprehension
- Wikipedia articles with crowdsourced question-answer pairs
- Logistic regression model : 51.0% F1 score Human : 86.8% F1 score
출처 : SQuAD: 100,000+ Questions for Machine Comprehension of Text