
ChatGPT에 대한 관심이 아직도 엄청나게 뜨거운데, 벌써 GPT-4가 등장했습니다 🚀
AI에 큰 관심이 없던 사람들도 업무를 효율적으로 처리할 수 있게 되었고,
많은 개발자들이 API를 활용해서 여러 서비스들을 개발하고 배포중입니다.
아직까지도 서비스적인 측면에서 활용될 여지가 무궁무진하다고 생각하는데 기술의 발전 속도를 따라 잡기가 힘드네요.. 🥲
이번 포스팅에서는 OpenAI에서 GPT-4와 함께 공개한 Technical Report를 간단하게 살펴보고,
그 내용을 최대한 요약해서 한글로 정리해보고자 합니다.
사실 Appendix(부록)까지 포함하면 90페이지가 넘기 때문에..
결론 파트까지만 다뤄볼 예정입니다!
0. Abstract
GPT-4는 이미지와 텍스트를 입력으로 받고 텍스트를 출력할 수 있는 거대 언어 모델입니다.
이는 Transformer 기반의 사전 학습 모델로 문서 내의 다음 토큰을 예측하는 방식으로 학습되었습니다.
또한 post-training을 적용한 것이 모델의 성능 향상에 크게 기여했습니다.
핵심적인 것은 작은 사이즈의 모델에 대한 평가 지표와 최적화 기법을 잘 고안했던 것이 큰 규모의 모델로 확장하는 데 크게 기여했다는 것입니다.
1. Introductoin
GPT-4와 같은 거대 멀티모달 모델들은 이미지, 텍스트를 동시에 입력으로 받을 수 있기 때문에 '대화 시스템, 텍스트 요약, 기계 번역' 등의 분야에 활용될 가능성이 높습니다.
흥미로운 것은 GPT가 '사람을 대상으로 고안된 여러 시험들'을 대상으로 평가되었다는 사실입니다.
몇몇 시험들에 대해서는 사람에 준하는, 혹은 그 이상의 퍼포먼스를 보여주었다는 것이 아주 인상적입니다.
심지어 'simulated bar exam(모의 변호사 시험 ㄷㄷㄷ)'에서 GPT-3.5가 하위 10% 성적을 기록한 것과 대조적으로,
GPT-4는 상위 10%의 성적을 기록했다고 합니다..
(AI 변호사님..?)
여러 태스크에서 기존 모델들보다 훨씬 우월한 성능을 뽐낸 것은 어찌보면 당연한 일 같습니다.
그러나 단순히 영어만 잘 처리하는 것에 그치지 않고 다른 언어들에 대해서도 탁월한 퍼포먼스를 보여주었다고 합니다.
하지만 논문에서는 이런 뛰어난 성능의 이면에 단점이 여전히 존재한다고 언급하고 있습니다.
아직까지 모델의 출력 결과를 온전히 신뢰할 수 없고, 또한 모델 context window(문맥을 파악하는 범위로 이해할 수 있을 듯 합니다)는 제한되어 있으며, 경험으로부터 학습하지 못한다는 단점을 가지고 있습니다.
쉽게 말하자면 모델의 답변을 100% 사실로 받아 들이기엔 어렵고,
또한 굉장히 긴 문장 조합에서는 성능이 제대로 발휘되기 어려우며,
2021년 9월 이전(사전 학습을 시작한 시점)의 데이터로만 학습된 것 뿐만 아니라,
새로운 입출력을 추가 학습 데이터로 사용하지 않는다는 한계를 언급한 것입니다.
2. Scope and Limitations of this Technical Report
이 레포트는 GPT의 능력(capabilities), 한계, 그리고 안전과 관련된 특성을 다룬다고 합니다.
GPT-4는 학습 데이터로 '대중적으로 이용 가능한(public하게 공개된)' 데이터와 '특정 라이센스가 존재하는(돈 주고 샀다는 뜻)' 데이터를 둘 다 활용했다고 합니다.
또한 Transformer 기반으로 문서 내의 다음 토큰을 예측하는 방식으로 학습했을 뿐만 아니라, 사람의 피드백을 통해 강화 학습(RLHF, Reinforcement Learning from Human Feedback) 역시 진행되었다고 합니다.
단, 이 레포트에는 모델의 아키텍쳐나 파라미터 사이즈, 하드웨어, 컴퓨팅 방식, 데이터셋 구축 방식, 학습 방식 등에 대한 내용은 다루지 않습니다.
3. Predictable Scaling
아시다시피, GPT-4처럼 엄청나게 거대한 모델들은 한 번 학습하는 데 엄청난 자원이 필요합니다.
그렇기에 성능을 확인하기 위해 여러 조건들을 매번 바꿔가면서 테스트하면 굉장히 비효율적이겠죠.
그래서 1,000배 ~ 10,000배 정도 작은 사이즈의 모델로 학습 성과를 검증하되,
사이즈를 키웠을 때도 그 성과를 예측할 수 있도록 infrastructure와 최적화 방식을 잘 구축한 것이 GPT-4 학습에 핵심적인 테크닉이었다고 합니다.
Loss Prediction, Scaling of Capabilities on HumanEval 에 대해 다루고 있는데 구체적으로 어떤 기법들을 적용했는지는 논문을 직접 보시는 것을 추천 드립니다!
대신 이 글에서는 간단한 그래프를 통해 무슨 뜻인지만 이해하고 넘어가겠습니다.
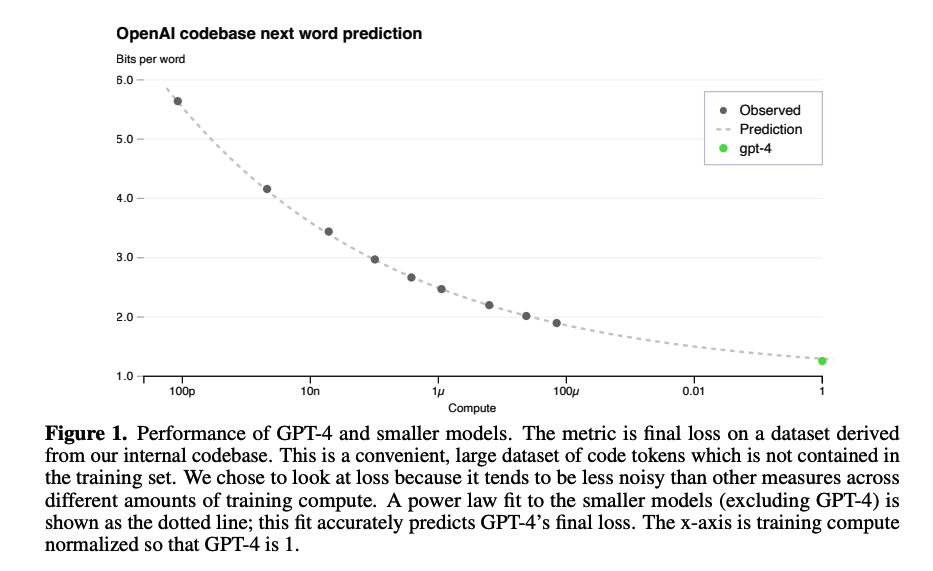
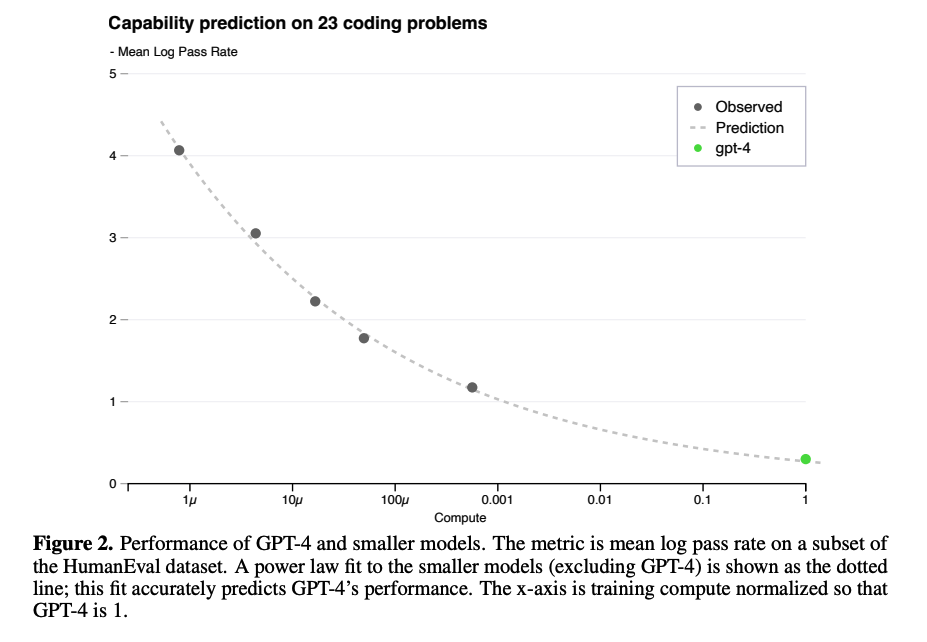
위 두 그래프에서 검은 색 점은 작은 모델들의 성능을 확인한 것입니다.
그리고 초록색 점은 실제 GPT-4의 성능을 확인한 것이구요.
모델의 사이즈를 키울수록 성능이 향상된다는 것을 알 수가 있습니다.
이때 최적화 기법이나 평가 지표를 잘못 설정했다면 이와 같이 부드러운 예측 곡선에 일치하는 결과가 나오지 못했을 것입니다.
(log에 거의 정확히 일치하는 것을 볼 수 있죠!)
따라서 연구 단계에서 이뤄지는 여러 실험들이 어떤 영향을 줄 수 있는지에 대해 작은 모델로 먼저 테스트하고,
최종 단계에서 가장 큰 사이즈의 GPT-4로 결과를 측정하여 효율성을 높였다고 볼 수 있겠습니다.
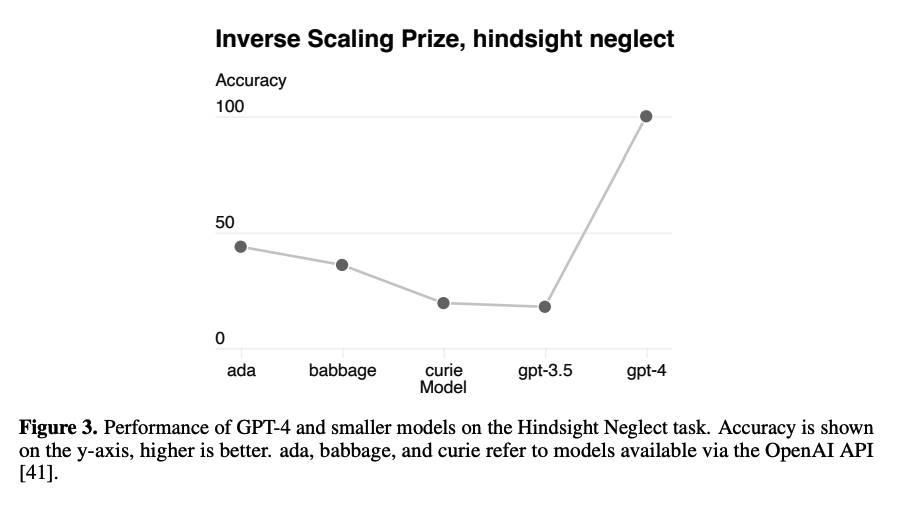
또 한 가지 재미있는 특징이 Hindsight Neglect task에 대한 성능을 확인했을 때 나타났습니다.
기존 모델들을 통한 연구 결과에서는 모델 사이즈를 키우게 되면(scaling) 오히려 성능이 하락했다고 합니다.
그러나 GPT의 그 사이즈를 키웠을 때 말도 안 되는 정확도를 보였다고 하네요.
이런 특징이 왜 나타나게 되었는지에 대한 설명은 논문 저자도 설명하기 어렵다고 밝혔습니다.
4. Capabilities
처음 언급했던 것처럼 GPT-4는 심지어 사람을 대상으로 한 테스트로도 그 성능을 확인해봤다고 합니다.
이런 테스트를 진행할 때는 그런 테스트에 대해 특정학습을 따로 수행하지도 않았다고 하네요.
이러한 시험은 publicly-available materials, 즉 누구나 이용가능한 것들로부터 획득한 데이터라고 합니다.
질문들은 '다중 선택(multiple-choice)'과 '자유 답변(free-response)' 형태로 구성되어 있으며 각각 알맞은 프롬프트를 디자인했답니다.
또한 최종적으로 성능을 평가할 때는 학습 단계에서 보지 못했던 데이터들을 사용했습니다.
4.1. Exam results

대략적인 개요만 살펴보면 위와 같습니다.
파란색은 GPT-3.5, 초록색은 GPT-4의 시험 결과를 나타냅니다.
확실히 대부분의 시험에서 GPT-4가 압도적인 성능 향상을 보였다는 것을 알 수 있습니다.
재밌는 것은 모델의 성능 향상이 'pre-training process', 즉 사전 학습 과정에 기인하는 것으로 판단된다는 점입니다.
지금까지 알려진 것은 사용자 친화적이며 그 성능이 탁월한 모델이 등장하게 된 것이 '사람의 피드백을 기반으로 한 강화 학습(RLHF)' 덕분이라는 점이었습니다.
그러나 GPT-4가 이러한 시험(exam)을 볼 때는 RLHF 방식을 적용해도 성능 향상이 거의 무의미한 수준이었다고 하네요.
4.2. Multi-lingual
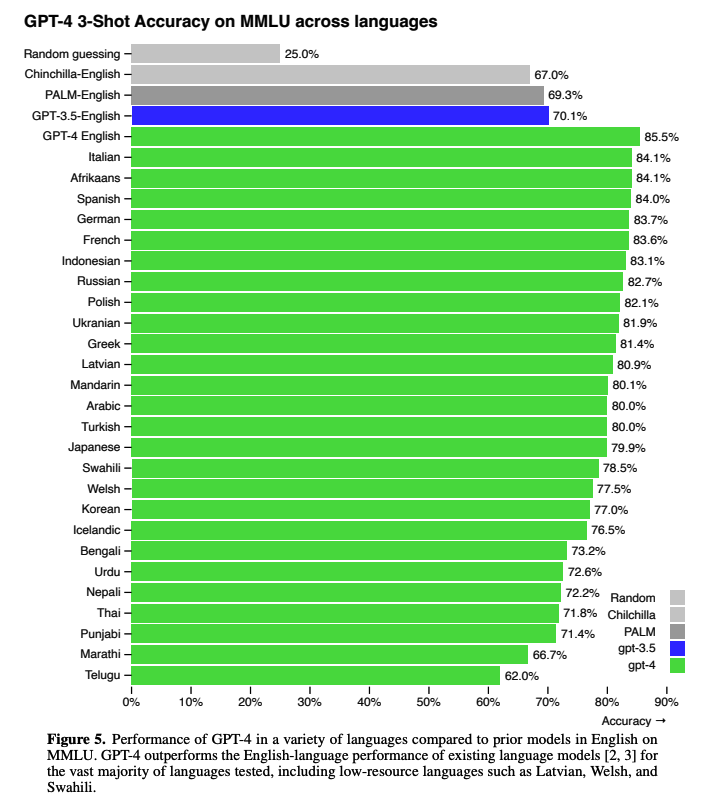
또다른 특징은 GPT-4가 다른 언어에 대한 처리 능력도 우수하다는 것입니다.
이를 확인하기 위해서 'Azure Translate'을 사용하여 기존의 영어로 쓰인 다양한 벤치마크들을 여러 언어로 번역했다고 합니다.
결과를 확인해보니 당연히도 GPT-4가 다른 모델들에 비해서 훨씬 좋은 성능을 보인다고 합니다.
4.3. Visual Inputs
아무래도 이전 모델과의 가장 큰 차이점이라면 이미지 데이터를 처리할 수 있다는 것이겠죠!
(개인적으로는 AI의 다음 행보는 멀티모달을 활용한 GPT일 것이라고 예측했었는데 이렇게 빠를 줄은 몰랐습니다...)

위 예시는 세 장의 이미지를 주고 어떤 웃음 포인트가 있는지 맞춰보라고 지시한 상황을 보여주고 있습니다.
저는 이 예시를 보고 '아니 이게 대체 어떻게 학습을 하면 가능한 일인가..' 싶었는데요..!
저자에 따르면 GPT-4가 '이미지와 텍스트를 함께 처리하는 능력'은 '텍스트만 입력으로 주어졌을 때'와 큰 차이가 없는 수준이라고 합니다.
어느 정도인지 가늠이 잘 되지 않네요..
5. Limitations
GPT-4가 이전에 비해 엄청난 성능 향상을 이뤄낸 것은 사실입니다만, 여전히 한계점들을 보유하고 있습니다.
신뢰성 문제는 모델 예측이 100% 정확할 수 없다는 것을 감안하면 당연한 것이라는 생각이 듭니다.
하지만 더 중요한 것은 '많은 사람들이 AI의 답변에 대해 객관적인 판단을 내리기가 힘들고, 이미 AI의 영향력이 너무 크다'라는 문제점이라고 생각합니다.

위 그래프는 GPT 패밀리 모델들이 내놓은 답변이 사람들의 이상적인 반응에 얼마나 부합하는지를 확인한 결과입니다.
물론 이 부분에 대해서도 GPT-4가 전작들에 비해 우월한 결과를 보여줍니다.
위에서 GPT-4의 성능 향상에 RLHF, 즉 사람의 피드백이 그다지 큰 영향을 주지 못했다고 언급한 저자의 발언이 기억나실지 모르겠습니다.
재밌는 것은 '헷갈릴만한 선택지 중에서 올바른 답을 고르는 태스크인 Truthful QA'에서는 그 효과가 탁월했다고 합니다.
즉, GPT-4에 RLHF를 적용하기 전에는 Truthful QA에 대한 성능이 GPT-3.5와 차이가 없었는데, 적용 이후에는 눈에 띄는 차이를 보여줬다고 하네요.
다만 모델이 학습을 너무 잘 해서인지는 모르겠지만 오답에 대해서도 지나친 확신을 갖고 있는 것이 문제라고 합니다.
(논문 표현을 빌리자면 double-check 같은 건 AI가 하지 않는다고 하네요 ㅋㅋㅋ 😂)
그런 경향도 RLHF 이후에 어느 정도 완화되는 것이 확인되었다고 합니다만 어느정도 유의미한 차이인지는 잘 감이 오지 않네요.
한편 1. Instruction 에서 밝힌 바와 같이 '2021년 9월 이후에 대해서는 무지'하다거나, '새로운 추가 학습을 하지 못한다'는 점 등의 한계 또한 자세히 설명하고 있습니다.
그리고 어느정도 편향된 출력 결과를 나타낸다는 것도 빼놓을 수 없겠죠.
6. Risk & mitigations
이 섹션도 은근 기술적인 내용이라고 판단해서 최대한 간단히 요약해보고자 합니다.
AI가 가진 여러 한계 중 가장 치명적인 것으로 지적되는 것 중 하나가 '편향'입니다.
왜냐하면 모델은 빅데이터로 학습하기 때문에 확률 기반으로 최적화된 답변을 내놓기 때문이죠.
예를 들어 세상에 'doctor'를 'he'로 지칭하는 데이터가 훨씬 많이 존재한다면 이 모델은 의사가 남자라고 학습하게 되는 것입니다.
하지만 아이러니하게도 사람들은 그런 것을 원하지 않습니다.
아주 중립적이고, 편향되지 않은 학습을 하길 원하죠. 😶
(현실과 반대되는 것을 원한다는 생각이 드는데요..그게 이상적인 것이죠!)
그렇기 때문에 GPT-4를 만들 때는 각 분야의 전문가들을 모셔와서 이런 편향성을 감소시키고 정제되지 않은 표현을 출력할 가능성을 낮췄다고 합니다.
뭐 여전히 한계는 존재하긴 하지만, 부정적으로 활용될 여지를 줄이기 위해 적지 않은 노력이 들어갔다는 것은 분명해보입니다!
7. Conclusion
지금까지 거대 멀티모달 모델, GPT-4에 대해 알아보았습니다.
이는 기존의 LLM(거대 언어 모델)의 성능을 싸그리 능가했을 뿐만 아니라(심지어 다개국어...),
이미지까지 처리할 수 있게 된 무시무시한 모델입니다 😬
발전된 능력에 비례하여 커지는 AI의 영향력 덕분에, 모델들이 가진 위험성도 덩달아 커진다는 점에 유의할 필요가 있습니다.
물론 그만큼 또 발전될 여지가 많이 남은 것이겠죠? 🧐
개인적 감상
간단히 언급했습니다만..
개인적으로 최근 핫한 ChatGPT에 대해 이야기를 할 때, 저는 항상 다음 행보는 무조건 멀티모달이다! 라고 이야기하곤 했습니다.
요즘 여러 논문들을 보면 결국 자연어와 다른 도메인을 함께 처리하고자 하는 경향이 엄청 강하더라구요.
아주 최근에 Microsoft 에서 Kosmos-1이라는 모델을 'Language Is Not All You Need: Aligning Perception with Language Models' 이라는 제목으로 내놓기도 했었죠.
굉장히 재미있게 읽었었는데 한 달도 지나지 않아서 Microsoft와 협력하는 OpenAI에서 이런 모델을 또 내놓을 줄이야.. 💩
지금 시점에서는 솔직히 AI 업계에 서비스적인 발전이 엄청나지 않을까 하는 생각만 추상적으로 하고 있습니다.
OpenAI에서 ChatGPT의 API를 배포하면서 이를 활용하고자 하는 시도도 엄청나게 많고, 실제로 사람들도 관심이 많아서 다들 써보려고 하니까요.
특히나 문서 작업을 하거나 코딩을 하는 주변 사람들도 반응이 뜨겁구요.
이전과 달리 AI 기술을 실생활에 어떻게 활용할 것인가에 대한 관심이 더욱 더 뜨거워지고 있는 것 같습니다 🔥
결국 이를 위해서는 경량화에 대한 연구도 엄청 필요한 것 같구요.
(뭐 사람들에게 서비스로 제공되지 않는 AI 기술은 결국 시장 가치가 없는 것이나 다름 없으니까요)
실제 'Meta에서 만든 LLaMA와 같은 모델을 맥북 한 대로 inference 해보겠다!' 하는 글들이 심심치 않게 보이는 걸 보면 확실히 놀랍습니다.
한편으로는 모든 분야에 NLP가 접목되어 가치를 창출해내게 된 것 같기도 해서 신기하구요.
GPT-4 같은 경우 RLHF에 대해 독특한 결과를 보여준 것 같은데, 결국 이를 어떻게 잘 적용해야 할까 의문도 듭니다.
(원래 쉬운 태스크에는 그다지 효과가 없다는 것 같긴 합니다)
AI에 관심을 가지고 공부하는 사람으로서 발전 속도를 따라가기가 무척 버겁게 느껴집니다만,
또 그런다고 관심 끄고 뒤쳐질수도 없는 노릇이니 열심히 공부하고 서비스 활용도 해봐야겠습니다!
혹시나 글에 잘못된 내용이나 부족한 부분이 있으면 얼마든지 댓글로 지적 부탁드립니다 🙏🏻
+ 추가
GPT-4가 출시되면서 이를 Chat-GPT 유료 서비스로 이용할 수 있게끔 풀기도 했습니다.
(덕분에 접속자가 많아서인지 굉장히 느리더라구요)
그런데 연구 결과에 대한 사람들의 반응은 아주 냉소적입니다.
실제로 기술 보고서에는 어떤 식으로 학습을 했는지, 어떤 아키텍쳐를 가지는지, 모델 사이즈는 어떤지에 대한 설명을 하지 않겠다고 밝혀져 있죠.
그래서 한 문장으로 '90페이지에 걸쳐서 큰 모델을 학습했더니 좋았다를 설명한거야? 이게 다야?' 라는 입장의 연구자들이 많습니다 ㅎㅎ..
특히 새로운 버전으로 출시하면서 달라진거라곤 고작 모달리티(modality, 텍스트 -> '텍스트 + 이미지'가 되었다는 거죠) 하나 뿐이라는 견해도 있고..
확실히 서비스적인 측면에서는 사람들의 마음을 빠르게 사로잡고 깊은 인상을 주는 것 같지만 연구 대상으로서는 아쉬운 모습을 보여준 것 같네요!
출처 : https://openai.com/research/gpt-4
GPT-4
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less capable than humans in many real-world scenarios, exhi
openai.com
'Paper Review' 카테고리의 다른 글
ChatGPT에 대한 관심이 아직도 엄청나게 뜨거운데, 벌써 GPT-4가 등장했습니다 🚀
AI에 큰 관심이 없던 사람들도 업무를 효율적으로 처리할 수 있게 되었고,
많은 개발자들이 API를 활용해서 여러 서비스들을 개발하고 배포중입니다.
아직까지도 서비스적인 측면에서 활용될 여지가 무궁무진하다고 생각하는데 기술의 발전 속도를 따라 잡기가 힘드네요.. 🥲
이번 포스팅에서는 OpenAI에서 GPT-4와 함께 공개한 Technical Report를 간단하게 살펴보고,
그 내용을 최대한 요약해서 한글로 정리해보고자 합니다.
사실 Appendix(부록)까지 포함하면 90페이지가 넘기 때문에..
결론 파트까지만 다뤄볼 예정입니다!
0. Abstract
GPT-4는 이미지와 텍스트를 입력으로 받고 텍스트를 출력할 수 있는 거대 언어 모델입니다.
이는 Transformer 기반의 사전 학습 모델로 문서 내의 다음 토큰을 예측하는 방식으로 학습되었습니다.
또한 post-training을 적용한 것이 모델의 성능 향상에 크게 기여했습니다.
핵심적인 것은 작은 사이즈의 모델에 대한 평가 지표와 최적화 기법을 잘 고안했던 것이 큰 규모의 모델로 확장하는 데 크게 기여했다는 것입니다.
1. Introductoin
GPT-4와 같은 거대 멀티모달 모델들은 이미지, 텍스트를 동시에 입력으로 받을 수 있기 때문에 '대화 시스템, 텍스트 요약, 기계 번역' 등의 분야에 활용될 가능성이 높습니다.
흥미로운 것은 GPT가 '사람을 대상으로 고안된 여러 시험들'을 대상으로 평가되었다는 사실입니다.
몇몇 시험들에 대해서는 사람에 준하는, 혹은 그 이상의 퍼포먼스를 보여주었다는 것이 아주 인상적입니다.
심지어 'simulated bar exam(모의 변호사 시험 ㄷㄷㄷ)'에서 GPT-3.5가 하위 10% 성적을 기록한 것과 대조적으로,
GPT-4는 상위 10%의 성적을 기록했다고 합니다..
(AI 변호사님..?)
여러 태스크에서 기존 모델들보다 훨씬 우월한 성능을 뽐낸 것은 어찌보면 당연한 일 같습니다.
그러나 단순히 영어만 잘 처리하는 것에 그치지 않고 다른 언어들에 대해서도 탁월한 퍼포먼스를 보여주었다고 합니다.
하지만 논문에서는 이런 뛰어난 성능의 이면에 단점이 여전히 존재한다고 언급하고 있습니다.
아직까지 모델의 출력 결과를 온전히 신뢰할 수 없고, 또한 모델 context window(문맥을 파악하는 범위로 이해할 수 있을 듯 합니다)는 제한되어 있으며, 경험으로부터 학습하지 못한다는 단점을 가지고 있습니다.
쉽게 말하자면 모델의 답변을 100% 사실로 받아 들이기엔 어렵고,
또한 굉장히 긴 문장 조합에서는 성능이 제대로 발휘되기 어려우며,
2021년 9월 이전(사전 학습을 시작한 시점)의 데이터로만 학습된 것 뿐만 아니라,
새로운 입출력을 추가 학습 데이터로 사용하지 않는다는 한계를 언급한 것입니다.
2. Scope and Limitations of this Technical Report
이 레포트는 GPT의 능력(capabilities), 한계, 그리고 안전과 관련된 특성을 다룬다고 합니다.
GPT-4는 학습 데이터로 '대중적으로 이용 가능한(public하게 공개된)' 데이터와 '특정 라이센스가 존재하는(돈 주고 샀다는 뜻)' 데이터를 둘 다 활용했다고 합니다.
또한 Transformer 기반으로 문서 내의 다음 토큰을 예측하는 방식으로 학습했을 뿐만 아니라, 사람의 피드백을 통해 강화 학습(RLHF, Reinforcement Learning from Human Feedback) 역시 진행되었다고 합니다.
단, 이 레포트에는 모델의 아키텍쳐나 파라미터 사이즈, 하드웨어, 컴퓨팅 방식, 데이터셋 구축 방식, 학습 방식 등에 대한 내용은 다루지 않습니다.
3. Predictable Scaling
아시다시피, GPT-4처럼 엄청나게 거대한 모델들은 한 번 학습하는 데 엄청난 자원이 필요합니다.
그렇기에 성능을 확인하기 위해 여러 조건들을 매번 바꿔가면서 테스트하면 굉장히 비효율적이겠죠.
그래서 1,000배 ~ 10,000배 정도 작은 사이즈의 모델로 학습 성과를 검증하되,
사이즈를 키웠을 때도 그 성과를 예측할 수 있도록 infrastructure와 최적화 방식을 잘 구축한 것이 GPT-4 학습에 핵심적인 테크닉이었다고 합니다.
Loss Prediction, Scaling of Capabilities on HumanEval 에 대해 다루고 있는데 구체적으로 어떤 기법들을 적용했는지는 논문을 직접 보시는 것을 추천 드립니다!
대신 이 글에서는 간단한 그래프를 통해 무슨 뜻인지만 이해하고 넘어가겠습니다.
위 두 그래프에서 검은 색 점은 작은 모델들의 성능을 확인한 것입니다.
그리고 초록색 점은 실제 GPT-4의 성능을 확인한 것이구요.
모델의 사이즈를 키울수록 성능이 향상된다는 것을 알 수가 있습니다.
이때 최적화 기법이나 평가 지표를 잘못 설정했다면 이와 같이 부드러운 예측 곡선에 일치하는 결과가 나오지 못했을 것입니다.
(log에 거의 정확히 일치하는 것을 볼 수 있죠!)
따라서 연구 단계에서 이뤄지는 여러 실험들이 어떤 영향을 줄 수 있는지에 대해 작은 모델로 먼저 테스트하고,
최종 단계에서 가장 큰 사이즈의 GPT-4로 결과를 측정하여 효율성을 높였다고 볼 수 있겠습니다.
또 한 가지 재미있는 특징이 Hindsight Neglect task에 대한 성능을 확인했을 때 나타났습니다.
기존 모델들을 통한 연구 결과에서는 모델 사이즈를 키우게 되면(scaling) 오히려 성능이 하락했다고 합니다.
그러나 GPT의 그 사이즈를 키웠을 때 말도 안 되는 정확도를 보였다고 하네요.
이런 특징이 왜 나타나게 되었는지에 대한 설명은 논문 저자도 설명하기 어렵다고 밝혔습니다.
4. Capabilities
처음 언급했던 것처럼 GPT-4는 심지어 사람을 대상으로 한 테스트로도 그 성능을 확인해봤다고 합니다.
이런 테스트를 진행할 때는 그런 테스트에 대해 특정학습을 따로 수행하지도 않았다고 하네요.
이러한 시험은 publicly-available materials, 즉 누구나 이용가능한 것들로부터 획득한 데이터라고 합니다.
질문들은 '다중 선택(multiple-choice)'과 '자유 답변(free-response)' 형태로 구성되어 있으며 각각 알맞은 프롬프트를 디자인했답니다.
또한 최종적으로 성능을 평가할 때는 학습 단계에서 보지 못했던 데이터들을 사용했습니다.
4.1. Exam results
대략적인 개요만 살펴보면 위와 같습니다.
파란색은 GPT-3.5, 초록색은 GPT-4의 시험 결과를 나타냅니다.
확실히 대부분의 시험에서 GPT-4가 압도적인 성능 향상을 보였다는 것을 알 수 있습니다.
재밌는 것은 모델의 성능 향상이 'pre-training process', 즉 사전 학습 과정에 기인하는 것으로 판단된다는 점입니다.
지금까지 알려진 것은 사용자 친화적이며 그 성능이 탁월한 모델이 등장하게 된 것이 '사람의 피드백을 기반으로 한 강화 학습(RLHF)' 덕분이라는 점이었습니다.
그러나 GPT-4가 이러한 시험(exam)을 볼 때는 RLHF 방식을 적용해도 성능 향상이 거의 무의미한 수준이었다고 하네요.
4.2. Multi-lingual
또다른 특징은 GPT-4가 다른 언어에 대한 처리 능력도 우수하다는 것입니다.
이를 확인하기 위해서 'Azure Translate'을 사용하여 기존의 영어로 쓰인 다양한 벤치마크들을 여러 언어로 번역했다고 합니다.
결과를 확인해보니 당연히도 GPT-4가 다른 모델들에 비해서 훨씬 좋은 성능을 보인다고 합니다.
4.3. Visual Inputs
아무래도 이전 모델과의 가장 큰 차이점이라면 이미지 데이터를 처리할 수 있다는 것이겠죠!
(개인적으로는 AI의 다음 행보는 멀티모달을 활용한 GPT일 것이라고 예측했었는데 이렇게 빠를 줄은 몰랐습니다...)
위 예시는 세 장의 이미지를 주고 어떤 웃음 포인트가 있는지 맞춰보라고 지시한 상황을 보여주고 있습니다.
저는 이 예시를 보고 '아니 이게 대체 어떻게 학습을 하면 가능한 일인가..' 싶었는데요..!
저자에 따르면 GPT-4가 '이미지와 텍스트를 함께 처리하는 능력'은 '텍스트만 입력으로 주어졌을 때'와 큰 차이가 없는 수준이라고 합니다.
어느 정도인지 가늠이 잘 되지 않네요..
5. Limitations
GPT-4가 이전에 비해 엄청난 성능 향상을 이뤄낸 것은 사실입니다만, 여전히 한계점들을 보유하고 있습니다.
신뢰성 문제는 모델 예측이 100% 정확할 수 없다는 것을 감안하면 당연한 것이라는 생각이 듭니다.
하지만 더 중요한 것은 '많은 사람들이 AI의 답변에 대해 객관적인 판단을 내리기가 힘들고, 이미 AI의 영향력이 너무 크다'라는 문제점이라고 생각합니다.
위 그래프는 GPT 패밀리 모델들이 내놓은 답변이 사람들의 이상적인 반응에 얼마나 부합하는지를 확인한 결과입니다.
물론 이 부분에 대해서도 GPT-4가 전작들에 비해 우월한 결과를 보여줍니다.
위에서 GPT-4의 성능 향상에 RLHF, 즉 사람의 피드백이 그다지 큰 영향을 주지 못했다고 언급한 저자의 발언이 기억나실지 모르겠습니다.
재밌는 것은 '헷갈릴만한 선택지 중에서 올바른 답을 고르는 태스크인 Truthful QA'에서는 그 효과가 탁월했다고 합니다.
즉, GPT-4에 RLHF를 적용하기 전에는 Truthful QA에 대한 성능이 GPT-3.5와 차이가 없었는데, 적용 이후에는 눈에 띄는 차이를 보여줬다고 하네요.
다만 모델이 학습을 너무 잘 해서인지는 모르겠지만 오답에 대해서도 지나친 확신을 갖고 있는 것이 문제라고 합니다.
(논문 표현을 빌리자면 double-check 같은 건 AI가 하지 않는다고 하네요 ㅋㅋㅋ 😂)
그런 경향도 RLHF 이후에 어느 정도 완화되는 것이 확인되었다고 합니다만 어느정도 유의미한 차이인지는 잘 감이 오지 않네요.
한편 1. Instruction 에서 밝힌 바와 같이 '2021년 9월 이후에 대해서는 무지'하다거나, '새로운 추가 학습을 하지 못한다'는 점 등의 한계 또한 자세히 설명하고 있습니다.
그리고 어느정도 편향된 출력 결과를 나타낸다는 것도 빼놓을 수 없겠죠.
6. Risk & mitigations
이 섹션도 은근 기술적인 내용이라고 판단해서 최대한 간단히 요약해보고자 합니다.
AI가 가진 여러 한계 중 가장 치명적인 것으로 지적되는 것 중 하나가 '편향'입니다.
왜냐하면 모델은 빅데이터로 학습하기 때문에 확률 기반으로 최적화된 답변을 내놓기 때문이죠.
예를 들어 세상에 'doctor'를 'he'로 지칭하는 데이터가 훨씬 많이 존재한다면 이 모델은 의사가 남자라고 학습하게 되는 것입니다.
하지만 아이러니하게도 사람들은 그런 것을 원하지 않습니다.
아주 중립적이고, 편향되지 않은 학습을 하길 원하죠. 😶
(현실과 반대되는 것을 원한다는 생각이 드는데요..그게 이상적인 것이죠!)
그렇기 때문에 GPT-4를 만들 때는 각 분야의 전문가들을 모셔와서 이런 편향성을 감소시키고 정제되지 않은 표현을 출력할 가능성을 낮췄다고 합니다.
뭐 여전히 한계는 존재하긴 하지만, 부정적으로 활용될 여지를 줄이기 위해 적지 않은 노력이 들어갔다는 것은 분명해보입니다!
7. Conclusion
지금까지 거대 멀티모달 모델, GPT-4에 대해 알아보았습니다.
이는 기존의 LLM(거대 언어 모델)의 성능을 싸그리 능가했을 뿐만 아니라(심지어 다개국어...),
이미지까지 처리할 수 있게 된 무시무시한 모델입니다 😬
발전된 능력에 비례하여 커지는 AI의 영향력 덕분에, 모델들이 가진 위험성도 덩달아 커진다는 점에 유의할 필요가 있습니다.
물론 그만큼 또 발전될 여지가 많이 남은 것이겠죠? 🧐
개인적 감상
간단히 언급했습니다만..
개인적으로 최근 핫한 ChatGPT에 대해 이야기를 할 때, 저는 항상 다음 행보는 무조건 멀티모달이다! 라고 이야기하곤 했습니다.
요즘 여러 논문들을 보면 결국 자연어와 다른 도메인을 함께 처리하고자 하는 경향이 엄청 강하더라구요.
아주 최근에 Microsoft 에서 Kosmos-1이라는 모델을 'Language Is Not All You Need: Aligning Perception with Language Models' 이라는 제목으로 내놓기도 했었죠.
굉장히 재미있게 읽었었는데 한 달도 지나지 않아서 Microsoft와 협력하는 OpenAI에서 이런 모델을 또 내놓을 줄이야.. 💩
지금 시점에서는 솔직히 AI 업계에 서비스적인 발전이 엄청나지 않을까 하는 생각만 추상적으로 하고 있습니다.
OpenAI에서 ChatGPT의 API를 배포하면서 이를 활용하고자 하는 시도도 엄청나게 많고, 실제로 사람들도 관심이 많아서 다들 써보려고 하니까요.
특히나 문서 작업을 하거나 코딩을 하는 주변 사람들도 반응이 뜨겁구요.
이전과 달리 AI 기술을 실생활에 어떻게 활용할 것인가에 대한 관심이 더욱 더 뜨거워지고 있는 것 같습니다 🔥
결국 이를 위해서는 경량화에 대한 연구도 엄청 필요한 것 같구요.
(뭐 사람들에게 서비스로 제공되지 않는 AI 기술은 결국 시장 가치가 없는 것이나 다름 없으니까요)
실제 'Meta에서 만든 LLaMA와 같은 모델을 맥북 한 대로 inference 해보겠다!' 하는 글들이 심심치 않게 보이는 걸 보면 확실히 놀랍습니다.
한편으로는 모든 분야에 NLP가 접목되어 가치를 창출해내게 된 것 같기도 해서 신기하구요.
GPT-4 같은 경우 RLHF에 대해 독특한 결과를 보여준 것 같은데, 결국 이를 어떻게 잘 적용해야 할까 의문도 듭니다.
(원래 쉬운 태스크에는 그다지 효과가 없다는 것 같긴 합니다)
AI에 관심을 가지고 공부하는 사람으로서 발전 속도를 따라가기가 무척 버겁게 느껴집니다만,
또 그런다고 관심 끄고 뒤쳐질수도 없는 노릇이니 열심히 공부하고 서비스 활용도 해봐야겠습니다!
혹시나 글에 잘못된 내용이나 부족한 부분이 있으면 얼마든지 댓글로 지적 부탁드립니다 🙏🏻
+ 추가
GPT-4가 출시되면서 이를 Chat-GPT 유료 서비스로 이용할 수 있게끔 풀기도 했습니다.
(덕분에 접속자가 많아서인지 굉장히 느리더라구요)
그런데 연구 결과에 대한 사람들의 반응은 아주 냉소적입니다.
실제로 기술 보고서에는 어떤 식으로 학습을 했는지, 어떤 아키텍쳐를 가지는지, 모델 사이즈는 어떤지에 대한 설명을 하지 않겠다고 밝혀져 있죠.
그래서 한 문장으로 '90페이지에 걸쳐서 큰 모델을 학습했더니 좋았다를 설명한거야? 이게 다야?' 라는 입장의 연구자들이 많습니다 ㅎㅎ..
특히 새로운 버전으로 출시하면서 달라진거라곤 고작 모달리티(modality, 텍스트 -> '텍스트 + 이미지'가 되었다는 거죠) 하나 뿐이라는 견해도 있고..
확실히 서비스적인 측면에서는 사람들의 마음을 빠르게 사로잡고 깊은 인상을 주는 것 같지만 연구 대상으로서는 아쉬운 모습을 보여준 것 같네요!
출처 : https://openai.com/research/gpt-4
GPT-4
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less capable than humans in many real-world scenarios, exhi
openai.com