
Vanishing gradients with RNNs
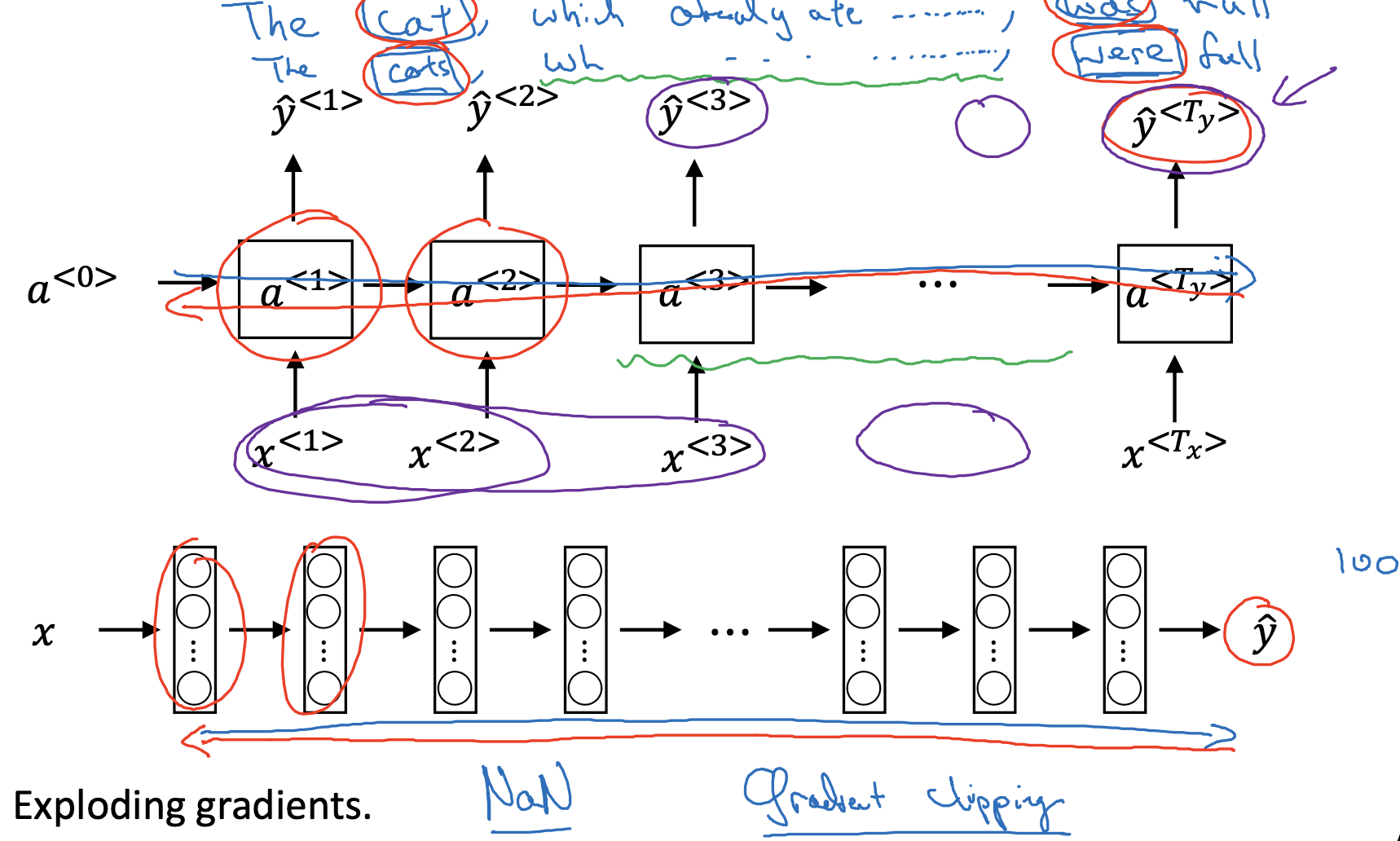
- RNN은 Vanishing gradients, Exploding gradients라는 대표적인 문제점을 안고 있습니다.
- sequence의 길이가 길어지면 길어질수록 초반부의 정보를 후반부까지 유지하기 힘들다는 것이 기본적인 문제점입니다.
위 예시에서 cat, cats라는 주어들을 보면 수일치를 위해 동사가 was, were로 달라져야 합니다.
만약 두 단어 사이의 sequence의 길이가 엄청나게 길다면 모델의 입장에서 모든 정보를 포함한 타당한 추론을 하기 어려워집니다. - 수학적으로는 층(layer)이 여러 개 쌓일수록 기울기가 폭발적으로 증가하거나, 역전파(back propagation) 시 0에 수렴하는 문제점이 발생하곤 합니다.
기울기가 폭발적으로 증가하면 숫자가 NaN으로 표시되기 때문에 그나마 알아차리기 쉽지만 vanishing gradients는 알아차리기가 더욱 까다롭습니다.
- sequence의 길이가 길어지면 길어질수록 초반부의 정보를 후반부까지 유지하기 힘들다는 것이 기본적인 문제점입니다.
- 이러한 RNN의 문제점들을 극복하기 위해 등장한 것이 GRU(Gated Recurrent Unit) 모델입니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 1주차' 카테고리의 다른 글
| Recurrent Neural Networks(10) : Long Short Term Memory (LSTM) (0) | 2023.04.17 |
|---|---|
| Recurrent Neural Networks(9) : Gated Recurrent Unit (GRU) (0) | 2023.04.17 |
| Recurrent Neural Networks(7) : Sampling Novel Sequences (0) | 2023.04.14 |
| Recurrent Neural Networks(6) : Language Model and Sequence Generation (0) | 2023.04.14 |
| Recurrent Neural Networks(5) : Different Types of RNNs (0) | 2023.04.14 |