
GRU and LSTM
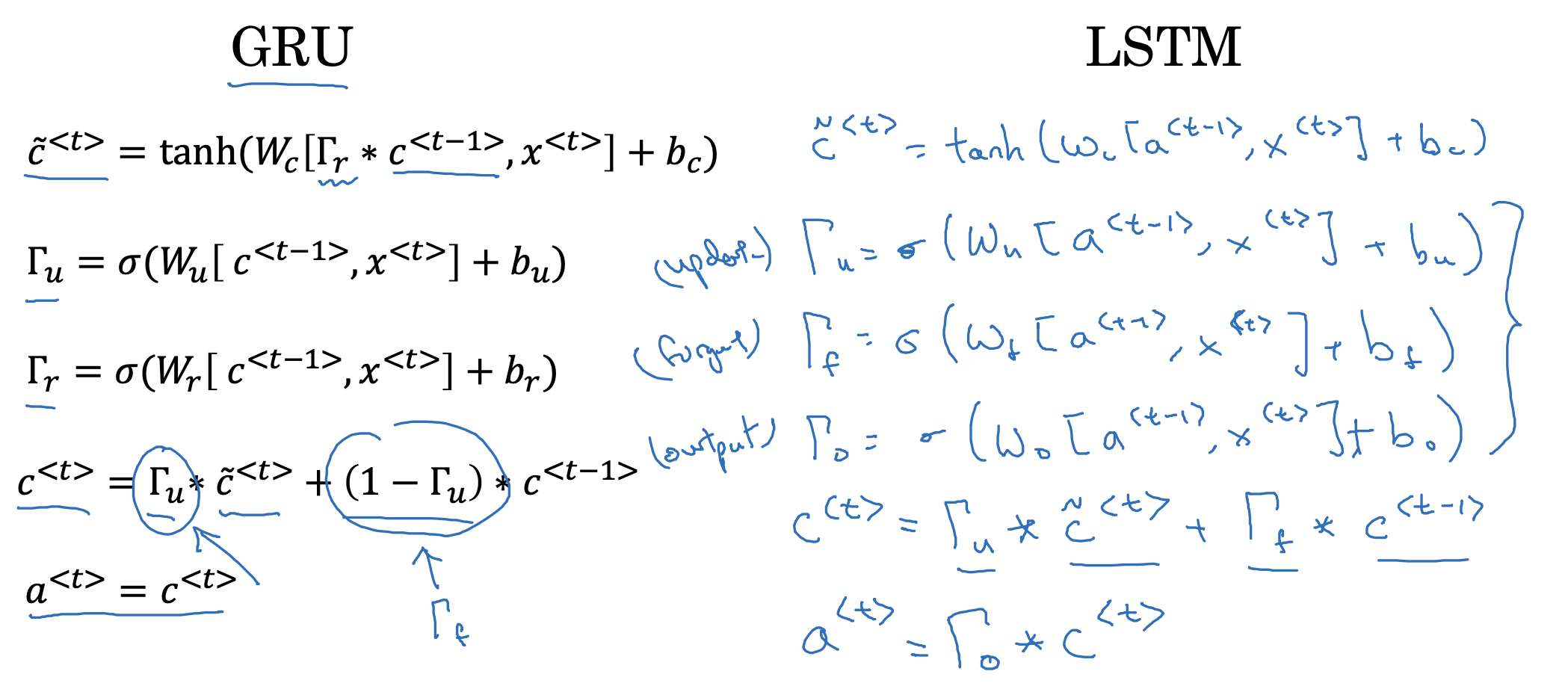
- GRU와 LSTM의 차이를 비교하고 있습니다.
GRU에서 update, reference 두 개의 gate를 사용한 것과 달리, LSTM은 update, forget, output 세 개의 gate를 사용합니다. - 재밌는 특징은 세 개의 gate에 들어가는 입력이 a<t-1> , x<t>로 동일하다는 것이죠.
물론 가중치와 편향은 gate마다 다릅니다. - 또한 GRU에서는 c<t>가 RNN의 a<t>와 동일한 것을 의미했지만,
LSTM에서는 c와 a가구분되어 사용되는 것을 알 수 있습니다.
이는 두 개의 항이 다음 층으로 각각 전달되기 때문입니다.
LSTM in pictures

- peephole connection : c<t-1>의 각 원소는 게이트 내의 각 요소에 순서대로 영향을 줍니다.
예를 들어 c<t-1>의 첫 번째 요소는 게이트의 첫 번째 요소에만, 두 번째 요소는 두 번째 요소에만 영향을 주게 됩니다. - 그림을 보면 c, a가 계속해서 다음 layer로 전달되는 것을 알 수 있습니다.
- LSTM은 GRU와 달리 세 개의 gate를 가지고 있어 유연하다는 특징이 있으며 훨씬 보편적으로 사용됩니다.
LSTM이 GRU보다 먼저 등장한 개념임에도 불구하고 그렇다는 것은 재밌는 사실이네요.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 1주차' 카테고리의 다른 글
| Recurrent Neural Networks(12) : Deep RNNs (0) | 2023.04.17 |
|---|---|
| Recurrent Neural Networks(11) : Bidirectional RNN (0) | 2023.04.17 |
| Recurrent Neural Networks(9) : Gated Recurrent Unit (GRU) (0) | 2023.04.17 |
| Recurrent Neural Networks(8) : Vanishing Gradients with RNNs (0) | 2023.04.14 |
| Recurrent Neural Networks(7) : Sampling Novel Sequences (0) | 2023.04.14 |