
RNN unit
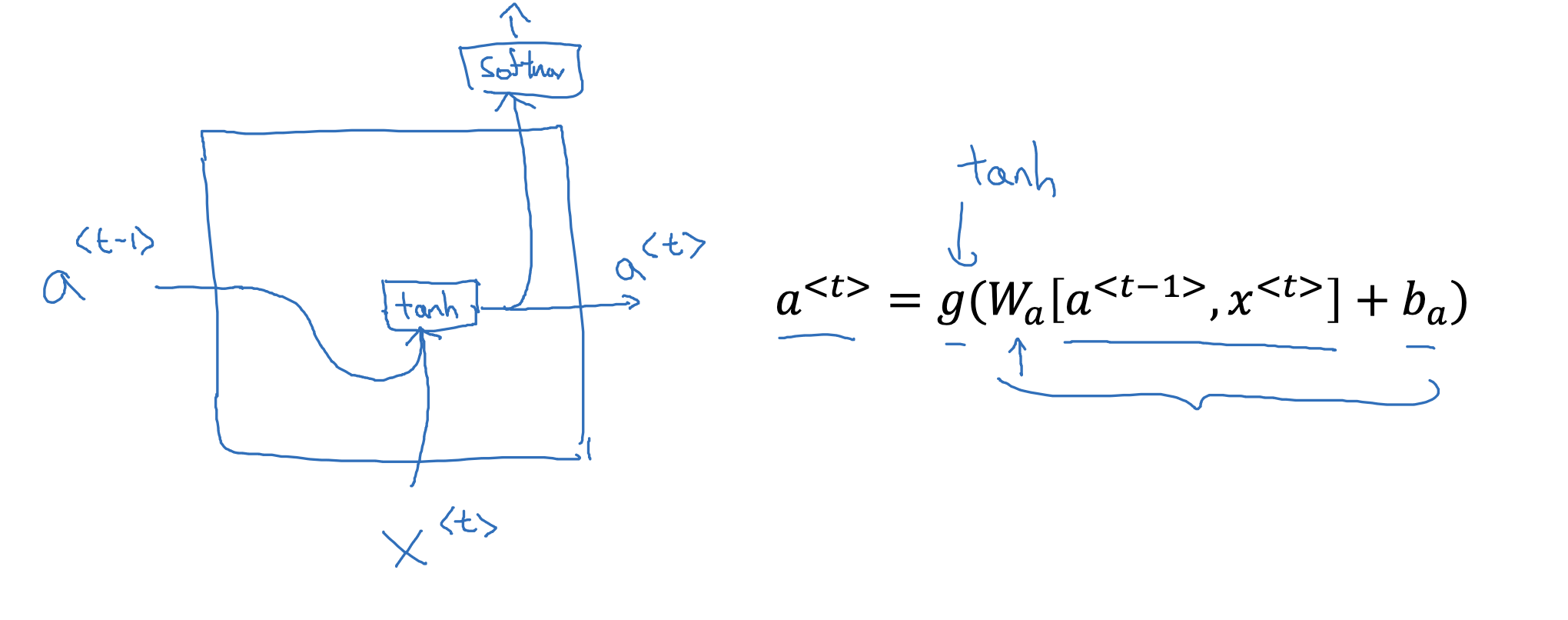
- 기존 RNN의 구조를 시각화하면 위와 같습니다.
- 이전 층의 a<t-1>과 현재 층의 입력 x<t>에 가중치를 곱하고 편향을 더한 것에 활성화 함수를 적용한 것이 a<t>가 됩니다.
GRU (simplified)
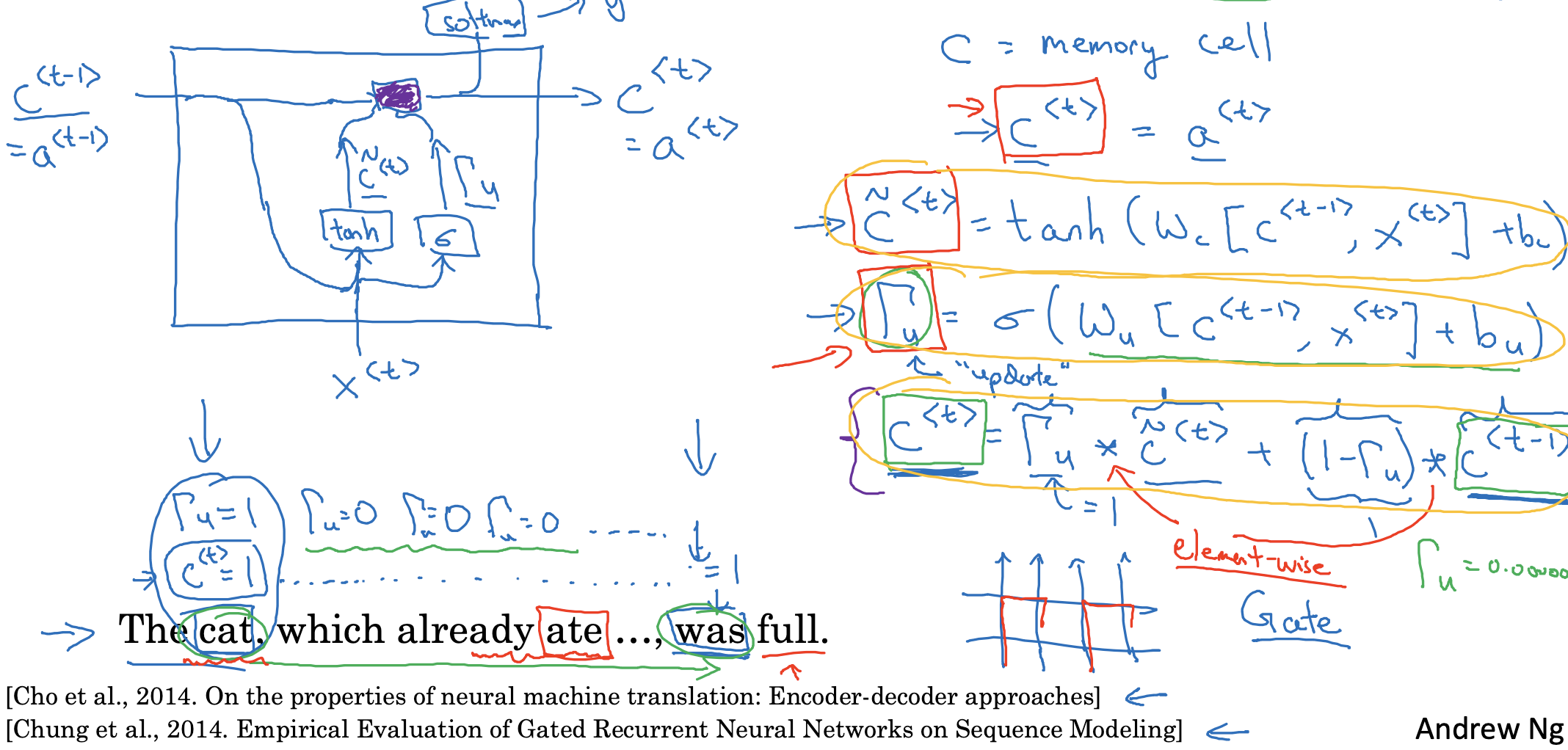
- 마찬가지로 GRU의 구조를 시각화한 것은 위와 같습니다.
- GRU에서는 cell의 개념을 사용하고 있기 때문에 RNN의 a 기호 대신 c를 사용합니다.
- 이전 층의 결과물 c<t-1>과 현재 층의 입력 x 둘을 계산한 것이 GRU에서는 tilda c와 gamma u가 됩니다.
여기서 u는 update의 u라고 생각해도 좋습니다. - tilda c는 tan h를, gamma u는 sigmoid를 활성화 함수로 사용합니다.
이제 둘을 곱하여 이전 층의 cell을 기억할지 말지 결정합니다. - 예를 들어 gamma = 0인 경우 현재 층의 tilda c는 버리고, 이전 층의 c<t-1>을 가져다 쓰게 됩니다.
따라서 'cat'의 정보를 문장 끝의 'was'까지 가져가는 동안 gamma의 값은 굉장히 작은 값으로 유지되어야 합니다. - gamma u의 경우 결국 각 토큰의 정보를 담을지 말지를 결정하는 다차원 벡터가 됩니다.
Full GRU
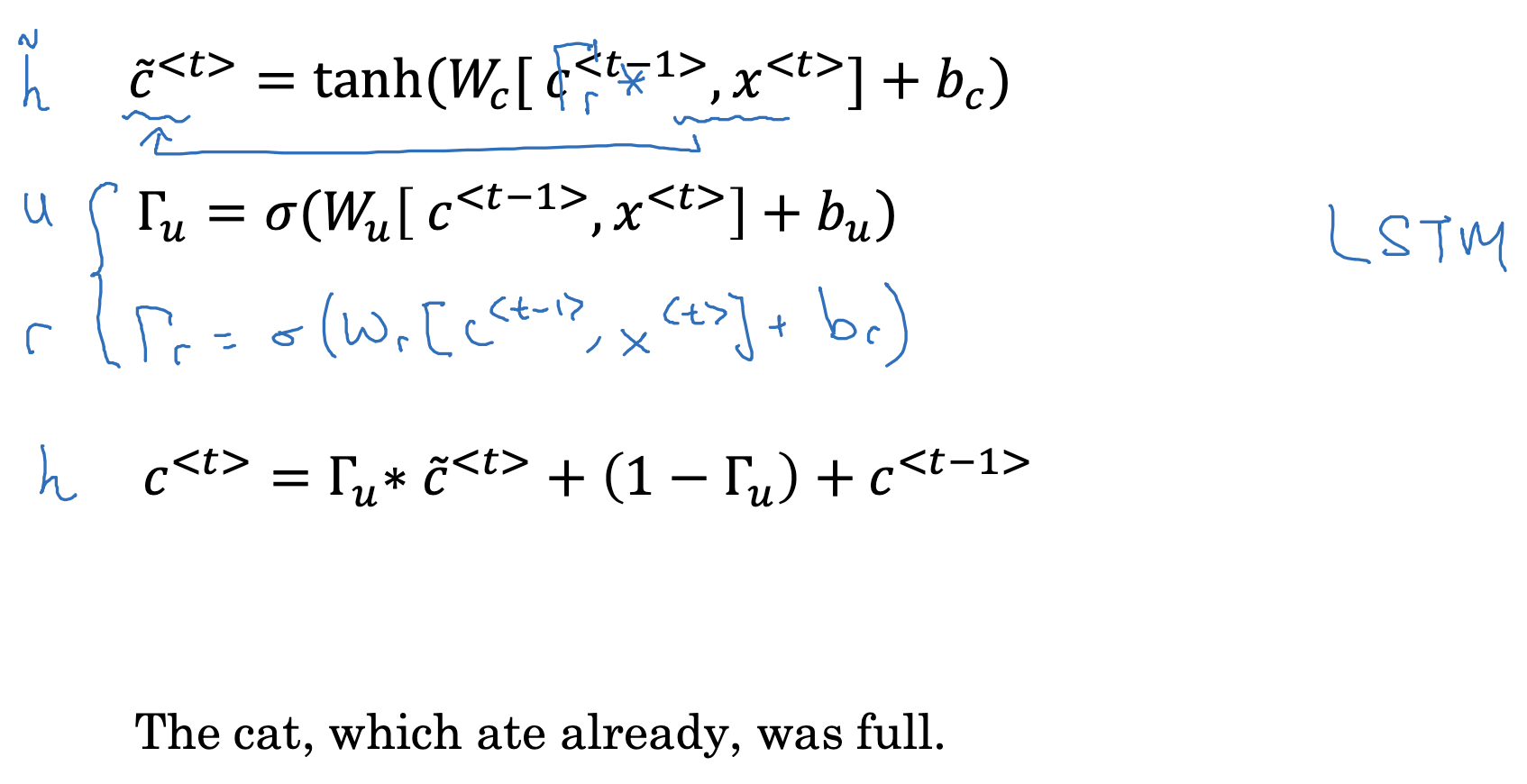
- 위에서 간단히 시각화된 GRU의 개념에서 가장 중요한 것은 크게 세 가지였습니다.
tilda c, gamma u, 그리고 c<t>. - 온전한 GRU의 경우 gamma r 항이 추가 됩니다.
여기서 r은 reference를 뜻합니다.
이 항은 c<t-1>이 c<t>의 다음 후보를 계산하는데 얼마나 적절한지를 나타냅니다. - 그래서 이 값을 c<t-1>과 곱해줍니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 1주차' 카테고리의 다른 글
| Recurrent Neural Networks(11) : Bidirectional RNN (0) | 2023.04.17 |
|---|---|
| Recurrent Neural Networks(10) : Long Short Term Memory (LSTM) (0) | 2023.04.17 |
| Recurrent Neural Networks(8) : Vanishing Gradients with RNNs (0) | 2023.04.14 |
| Recurrent Neural Networks(7) : Sampling Novel Sequences (0) | 2023.04.14 |
| Recurrent Neural Networks(6) : Language Model and Sequence Generation (0) | 2023.04.14 |
RNN unit
- 기존 RNN의 구조를 시각화하면 위와 같습니다.
- 이전 층의 a<t-1>과 현재 층의 입력 x<t>에 가중치를 곱하고 편향을 더한 것에 활성화 함수를 적용한 것이 a<t>가 됩니다.
GRU (simplified)
- 마찬가지로 GRU의 구조를 시각화한 것은 위와 같습니다.
- GRU에서는 cell의 개념을 사용하고 있기 때문에 RNN의 a 기호 대신 c를 사용합니다.
- 이전 층의 결과물 c<t-1>과 현재 층의 입력 x 둘을 계산한 것이 GRU에서는 tilda c와 gamma u가 됩니다.
여기서 u는 update의 u라고 생각해도 좋습니다. - tilda c는 tan h를, gamma u는 sigmoid를 활성화 함수로 사용합니다.
이제 둘을 곱하여 이전 층의 cell을 기억할지 말지 결정합니다. - 예를 들어 gamma = 0인 경우 현재 층의 tilda c는 버리고, 이전 층의 c<t-1>을 가져다 쓰게 됩니다.
따라서 'cat'의 정보를 문장 끝의 'was'까지 가져가는 동안 gamma의 값은 굉장히 작은 값으로 유지되어야 합니다. - gamma u의 경우 결국 각 토큰의 정보를 담을지 말지를 결정하는 다차원 벡터가 됩니다.
Full GRU
- 위에서 간단히 시각화된 GRU의 개념에서 가장 중요한 것은 크게 세 가지였습니다.
tilda c, gamma u, 그리고 c<t>. - 온전한 GRU의 경우 gamma r 항이 추가 됩니다.
여기서 r은 reference를 뜻합니다.
이 항은 c<t-1>이 c<t>의 다음 후보를 계산하는데 얼마나 적절한지를 나타냅니다. - 그래서 이 값을 c<t-1>과 곱해줍니다.
출처: Coursera, Sequence Models, DeepLearning.AI
'Sequence Models > 1주차' 카테고리의 다른 글
| Recurrent Neural Networks(11) : Bidirectional RNN (0) | 2023.04.17 |
|---|---|
| Recurrent Neural Networks(10) : Long Short Term Memory (LSTM) (0) | 2023.04.17 |
| Recurrent Neural Networks(8) : Vanishing Gradients with RNNs (0) | 2023.04.14 |
| Recurrent Neural Networks(7) : Sampling Novel Sequences (0) | 2023.04.14 |
| Recurrent Neural Networks(6) : Language Model and Sequence Generation (0) | 2023.04.14 |