
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
최근 생성 AI를 이용한 다양한 검색 엔진이 존재한다.
이 검색 엔진의 검색 결과에 대한 신뢰도를 검증하고 엔진별로 비교한 논문.
- 배경
ChatGPT의 등장 이후로 LLM 기반의 검색 서비스가 핫하게 떠오르고 있다.
예를 들어 New Bing의 경우 최근 GPT-4 모델을 사용해서 검색을 하고 그 결과를 채팅 형식으로 반환하는 서비스를 제공하고 있다.
이러한 변화 덕분에 부동의 1위 검색 엔진이었던 구글의 입지가 심각하게 흔들리고 있고, 구글 역시 이와 같은 흐름에 뒤처지지 않기 위해 애쓰고 있음이 기사화되기도 했다.
따라서 단순한 챗봇을 넘어서 최신 정보를 검색해주는 LLM에 대한 신뢰도 문제를 반드시 짚고 넘어가야 할 것이다.
- 평가 지표
본 논문에서는 크게 네 가지의 항목을 기준으로 검색 엔진의 신뢰도 및 타당성을 확인한다.
- fluency(유창성) : 생성된 답변이 유창하고 일관적인가
- perceived utility(유용성) : 응답이 질문에 답변하는 데 도움이 되고 유익한 것이 맞는가
- citation recall(인용 재현성) : reference가 필요한 전체 문장에 대한 실제 인용의 비율
- citation precision(인용 정확성) : 전체 인용 중 실제로 타당한 인용의 비율
recall, precision은 원래 f1 score를 구성하는 요소인데, 여기서는 citation을 덧붙인 자체 metric을 구성한다.

- 논문 컨셉
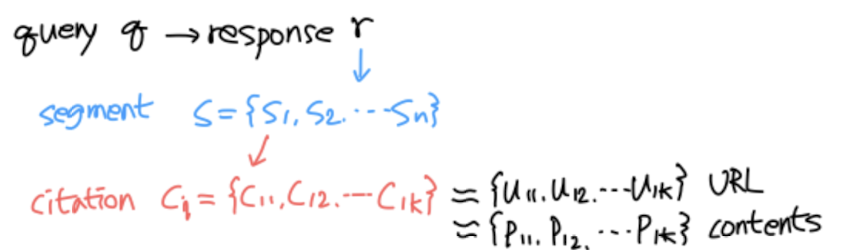
사용자의 질문 q(query)가 주어짐
→ 이에 대해 모델이 생성한 답변 r(response)
→ 이를 n개 단위로 쪼갬(segment)
→ 각 조각(segment)에 대해 k개의 citation(c)를 찾아옴
→ 이때의 citation 개수만큼 URL(u), contents(p)가 k개 존재
- 결과
- 현재 엄청나게 많은 유저들이 사용하는 검색 엔진들은 처참한 인용 신뢰도를 갖고 있다. 모델의 답변 중 인용이 완벽히 이뤄진 경우는 50% 수준, 부분적으로 잘 이뤄진 경우는 74% 수준이다.
- citation recall & precision은 fluency & perceived utility와 음의 상관관계를 갖는다. 인용이 많아질수록 부정확한 정보를 단순히 복사해서 긁어오는 경우가 많아진다는 듯이다.
- 개인적 감상
👍🏻
생각보다 훨씬 많은 검색 엔진이 존재한다는 것을 알게 되었고, 이에 대한 시야도 넓힐 수 있었다.
New Bing을 사용하면서도 각 문장에 대해 citation이 되어야 한다고 생각해 본 적이 없었는데, 확실히 신뢰도를 검증하는 입장에서는 이런 것들이 중요하구나, 생각하게 되었다.
그 과정이 또 Human Feedback에 의해 이뤄졌다는 것을 보고 놀라기도 했다.
확실히 기존에 없던 것들을 검증하기 위한 실험에서는 설득력있는 타당한 평가 지표를 만드는 것이 엄청 중요하다는 생각을 했다.
👎🏻
한 가지 조금 아쉽다고 생각했던 것은 앞으로의 발전 가능성에 대한 언급이 없다는 점이었다.
어찌보면 문제점으로 지적했던 것 중 하나가 인용의 빈도와 퀄리티의 반비례 관계였었는데, 둘 다를 만족하는 방법이야말로 향후 발전 방향성이 아닐까 생각한다.
우리가 인공 지능 모델을 신뢰할 수 있으려면 의미 없는 인용만 많아서도 안 되고, 의미는 있지만 일부 편파적인 인용만 이뤄져도 안 되기 때문이다.
출처 : https://arxiv.org/abs/2304.09848
Evaluating Verifiability in Generative Search Engines
Generative search engines directly generate responses to user queries, along with in-line citations. A prerequisite trait of a trustworthy generative search engine is verifiability, i.e., systems should cite comprehensively (high citation recall; all state
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
최근 생성 AI를 이용한 다양한 검색 엔진이 존재한다.
이 검색 엔진의 검색 결과에 대한 신뢰도를 검증하고 엔진별로 비교한 논문.
- 배경
ChatGPT의 등장 이후로 LLM 기반의 검색 서비스가 핫하게 떠오르고 있다.
예를 들어 New Bing의 경우 최근 GPT-4 모델을 사용해서 검색을 하고 그 결과를 채팅 형식으로 반환하는 서비스를 제공하고 있다.
이러한 변화 덕분에 부동의 1위 검색 엔진이었던 구글의 입지가 심각하게 흔들리고 있고, 구글 역시 이와 같은 흐름에 뒤처지지 않기 위해 애쓰고 있음이 기사화되기도 했다.
따라서 단순한 챗봇을 넘어서 최신 정보를 검색해주는 LLM에 대한 신뢰도 문제를 반드시 짚고 넘어가야 할 것이다.
- 평가 지표
본 논문에서는 크게 네 가지의 항목을 기준으로 검색 엔진의 신뢰도 및 타당성을 확인한다.
- fluency(유창성) : 생성된 답변이 유창하고 일관적인가
- perceived utility(유용성) : 응답이 질문에 답변하는 데 도움이 되고 유익한 것이 맞는가
- citation recall(인용 재현성) : reference가 필요한 전체 문장에 대한 실제 인용의 비율
- citation precision(인용 정확성) : 전체 인용 중 실제로 타당한 인용의 비율
recall, precision은 원래 f1 score를 구성하는 요소인데, 여기서는 citation을 덧붙인 자체 metric을 구성한다.
- 논문 컨셉
사용자의 질문 q(query)가 주어짐
→ 이에 대해 모델이 생성한 답변 r(response)
→ 이를 n개 단위로 쪼갬(segment)
→ 각 조각(segment)에 대해 k개의 citation(c)를 찾아옴
→ 이때의 citation 개수만큼 URL(u), contents(p)가 k개 존재
- 결과
- 현재 엄청나게 많은 유저들이 사용하는 검색 엔진들은 처참한 인용 신뢰도를 갖고 있다. 모델의 답변 중 인용이 완벽히 이뤄진 경우는 50% 수준, 부분적으로 잘 이뤄진 경우는 74% 수준이다.
- citation recall & precision은 fluency & perceived utility와 음의 상관관계를 갖는다. 인용이 많아질수록 부정확한 정보를 단순히 복사해서 긁어오는 경우가 많아진다는 듯이다.
- 개인적 감상
👍🏻
생각보다 훨씬 많은 검색 엔진이 존재한다는 것을 알게 되었고, 이에 대한 시야도 넓힐 수 있었다.
New Bing을 사용하면서도 각 문장에 대해 citation이 되어야 한다고 생각해 본 적이 없었는데, 확실히 신뢰도를 검증하는 입장에서는 이런 것들이 중요하구나, 생각하게 되었다.
그 과정이 또 Human Feedback에 의해 이뤄졌다는 것을 보고 놀라기도 했다.
확실히 기존에 없던 것들을 검증하기 위한 실험에서는 설득력있는 타당한 평가 지표를 만드는 것이 엄청 중요하다는 생각을 했다.
👎🏻
한 가지 조금 아쉽다고 생각했던 것은 앞으로의 발전 가능성에 대한 언급이 없다는 점이었다.
어찌보면 문제점으로 지적했던 것 중 하나가 인용의 빈도와 퀄리티의 반비례 관계였었는데, 둘 다를 만족하는 방법이야말로 향후 발전 방향성이 아닐까 생각한다.
우리가 인공 지능 모델을 신뢰할 수 있으려면 의미 없는 인용만 많아서도 안 되고, 의미는 있지만 일부 편파적인 인용만 이뤄져도 안 되기 때문이다.
출처 : https://arxiv.org/abs/2304.09848
Evaluating Verifiability in Generative Search Engines
Generative search engines directly generate responses to user queries, along with in-line citations. A prerequisite trait of a trustworthy generative search engine is verifiability, i.e., systems should cite comprehensively (high citation recall; all state
arxiv.org