
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLaMA-Adpater의 두 번째 버전. 기존과 달리 이미지까지 더 잘 처리할 수 있는 multi-modality 보유
- 배경
어떻게 하면 LLM을 instruction follower로 만들 수 있을지, 즉 어떻게 instruction tuning을 잘 할 수 있을지에 대해 많은 관심이 쏠리고 있다.
이전에 LLaMA-Adapter와 같은 모델도 굉장히 효율적인 tuning 방법론을 제시했는데 이를 더욱 발전시킨 모델을 제시한다.
V1과 비교했을 때 가장 큰 차이점은 이미지 관련 태스크도 굉장히 잘 처리할 수 있다는 것이다.
- 컨셉
1. bias tuning of linear layers
V1의 경우 LLaMA는 freeze하고 adapter만 학습을 진행했는데, 그 학습 대상이 결국 adaptation prompt와 gating factor에 한정된다는 단점이 있었다.
따라서 instruction cue를 adaptation prompt와 gating factor에 융합하는 bias tuning 전략을 제시한다.
각 transformer layer에 bias를 추가하고 이를 scale하며 식은 다음과 같이 표현된다.
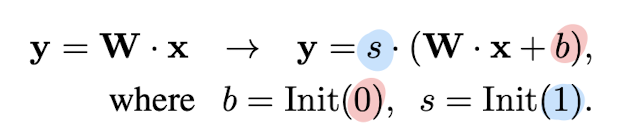
2. Joint Training with Disjoint Parameters
보다 긴 답변과 multi-modal적 이해를 위해 image-text caption 데이터(500K)와 language-only instruction 예시(50K)를 활용한다.
둘의 데이터의 양과 구성이 다르기 때문에 각각 다른 layer에서 학습을 진행하고 그 결과를 최적화한다.
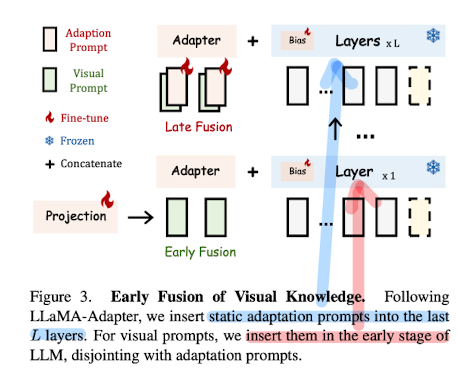
3. Early Fusion of Visual Knowledge
encoded visual token과 adaptation prompt, 둘을 합치지 않고 다른 Transformer layer에 각각 입력으로 제공한다.
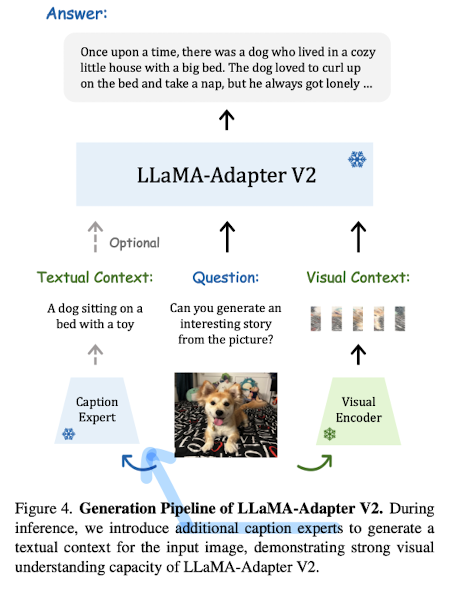
4. Integration with Experts
captioning, detection, OCR과 같은 expert system을 이용한다.
예를 들어 expert system에게 image에 대한 caption을 생성해달라고 요청하고, 이 정보를 활용하는 것이다.
상황에 따라 다른 expert가 사용될 수 있고, expert 사용 유무 자체도 선택적이다.
- 개인적 감상
GPT-4가 GPT-3.5와 달리 이미지를 처리할 수 있다고 한 것과 동일한 현상을 목격한 기분이다.
지금의 흐름은 LLM을 기반으로 자연어처리 분야의 태스크를 쉽게 처리하며, 이를 통해 image/video 혹은 그 외의 더 다양한 분야들이 발전하는 것 같다고 느낀다.
연구하는 사람들에 대해서는 특히 현 상황의 아쉬운 점이 LLM을 제대로 연구하거나 파헤쳐 볼 수 없다는 것이다.
그렇기 때문에 파라미터수를 M 단위로 극적으로 줄이면서 기존의 LLM과 유사한 성능을 발휘할 수 있는 모델에 대한 관심이 끊이지 않는 것 같다.
결국 이런 발전도 서비스로 이어져 실제 유저들에게 제공되며 수익이 창출되어야 할 것인데, 성능이 ‘나쁘지만 않더라도’ 많은 사람을 만족시킬 수 있을 것이다.
물론 사람들의 기대치가 이미 충분히 높아진 상황에서 그런 것들이 쉽진 않겠지만..
막연한 느낌으로는 예전에 모델을 거대한 데이터를 대상으로 사전 학습하고 이를 fine-tuning하여 여러 task에 대해 general한(심지어는 뛰어난) 성능을 내는 것이 주된 흐름으로 자리를 잡았다는데, 이것이 LLM과 parameter efficient tuning/instruction 등의 관계로 전환된 것이 아닐까 싶기도 하다.
출처 : https://arxiv.org/abs/2304.15010
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
How to efficiently transform large language models (LLMs) into instruction followers is recently a popular research direction, while training LLM for multi-modal reasoning remains less explored. Although the recent LLaMA-Adapter demonstrates the potential
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLaMA-Adpater의 두 번째 버전. 기존과 달리 이미지까지 더 잘 처리할 수 있는 multi-modality 보유
- 배경
어떻게 하면 LLM을 instruction follower로 만들 수 있을지, 즉 어떻게 instruction tuning을 잘 할 수 있을지에 대해 많은 관심이 쏠리고 있다.
이전에 LLaMA-Adapter와 같은 모델도 굉장히 효율적인 tuning 방법론을 제시했는데 이를 더욱 발전시킨 모델을 제시한다.
V1과 비교했을 때 가장 큰 차이점은 이미지 관련 태스크도 굉장히 잘 처리할 수 있다는 것이다.
- 컨셉
1. bias tuning of linear layers
V1의 경우 LLaMA는 freeze하고 adapter만 학습을 진행했는데, 그 학습 대상이 결국 adaptation prompt와 gating factor에 한정된다는 단점이 있었다.
따라서 instruction cue를 adaptation prompt와 gating factor에 융합하는 bias tuning 전략을 제시한다.
각 transformer layer에 bias를 추가하고 이를 scale하며 식은 다음과 같이 표현된다.
2. Joint Training with Disjoint Parameters
보다 긴 답변과 multi-modal적 이해를 위해 image-text caption 데이터(500K)와 language-only instruction 예시(50K)를 활용한다.
둘의 데이터의 양과 구성이 다르기 때문에 각각 다른 layer에서 학습을 진행하고 그 결과를 최적화한다.
3. Early Fusion of Visual Knowledge
encoded visual token과 adaptation prompt, 둘을 합치지 않고 다른 Transformer layer에 각각 입력으로 제공한다.
4. Integration with Experts
captioning, detection, OCR과 같은 expert system을 이용한다.
예를 들어 expert system에게 image에 대한 caption을 생성해달라고 요청하고, 이 정보를 활용하는 것이다.
상황에 따라 다른 expert가 사용될 수 있고, expert 사용 유무 자체도 선택적이다.
- 개인적 감상
GPT-4가 GPT-3.5와 달리 이미지를 처리할 수 있다고 한 것과 동일한 현상을 목격한 기분이다.
지금의 흐름은 LLM을 기반으로 자연어처리 분야의 태스크를 쉽게 처리하며, 이를 통해 image/video 혹은 그 외의 더 다양한 분야들이 발전하는 것 같다고 느낀다.
연구하는 사람들에 대해서는 특히 현 상황의 아쉬운 점이 LLM을 제대로 연구하거나 파헤쳐 볼 수 없다는 것이다.
그렇기 때문에 파라미터수를 M 단위로 극적으로 줄이면서 기존의 LLM과 유사한 성능을 발휘할 수 있는 모델에 대한 관심이 끊이지 않는 것 같다.
결국 이런 발전도 서비스로 이어져 실제 유저들에게 제공되며 수익이 창출되어야 할 것인데, 성능이 ‘나쁘지만 않더라도’ 많은 사람을 만족시킬 수 있을 것이다.
물론 사람들의 기대치가 이미 충분히 높아진 상황에서 그런 것들이 쉽진 않겠지만..
막연한 느낌으로는 예전에 모델을 거대한 데이터를 대상으로 사전 학습하고 이를 fine-tuning하여 여러 task에 대해 general한(심지어는 뛰어난) 성능을 내는 것이 주된 흐름으로 자리를 잡았다는데, 이것이 LLM과 parameter efficient tuning/instruction 등의 관계로 전환된 것이 아닐까 싶기도 하다.
출처 : https://arxiv.org/abs/2304.15010
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
How to efficiently transform large language models (LLMs) into instruction followers is recently a popular research direction, while training LLM for multi-modal reasoning remains less explored. Although the recent LLaMA-Adapter demonstrates the potential
arxiv.org