
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLM에서 갑자기 등장하는 파워풀한 능력, emergent ability는 실재하는 것이 아니다.
연구자들의 편협한 metric 선택이 불러온 결과.
- 배경
LLM이 지닌 엄청난 능력이 주목을 받게 된 것은 GPT-3와 같이 파격적인 모델 파라미터 구성으로 학습을 진행한 시점부터였다.
흥미로운 것은 모델의 사이즈가 작았을 때 눈 씻고 봐도 찾을 수 없었던 능력이, 모델의 사이즈를 키우면서 ‘갑작스럽게’ 등장한다는 점이었다.
대표적인 예로 in-context-learning(이를 학습으로 볼 수 있는지에 대한 의견도 분분하지만) 등을 들 수 있다.
현재까지도 이러한 현상에 대해 많은 사람들이 의문을 품고 있는 상황에서, 본 논문은 이런 현상이 허구라고 지적한다.
- 핵심 주장
- emergent ability는 nonlinear metric으로 평가했기 때문에 그렇게 보이는 것 뿐이다.
linear metric으로 평가하면 준선형(quasilinear) 그래프가 그려진다.
예를 들어 multi choice로 모델 성능을 평가하면 애초에 discrete한 평가 방식이라는 점을 지적한 것. - higher resolution evaluation을 하면 emergent ability가 사라진다. 어떤 accuracy를 선택하는지가 이 현상 발생 유무에 영향을 준다. (1번과 크게 구분되는 내용은 아닌 듯하다)
- 재밌는 실험 결과
정답의 길이가 길수록 모델 성능은 확 떨어질 수밖에 없는 구조이다.
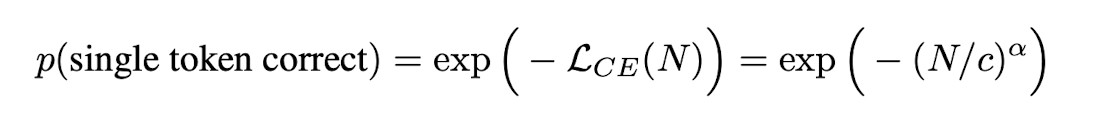
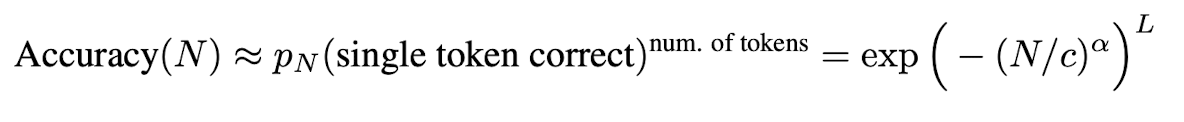
원래 각 토큰의 정확도를 토대로 답변의 accuracy를 구하는 식은 위와 같은데, 덕분에 토큰 길이에 비례하여 정확도가 급격하게(sharpness) 떨어질 것을 알 수 있다.
그래서 이를 Token Edit Distance로 수정하면 다른 결과가 나타난다.
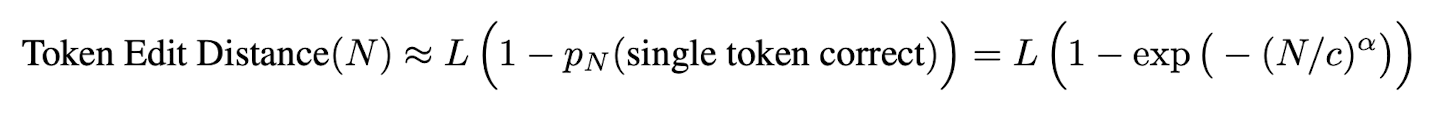
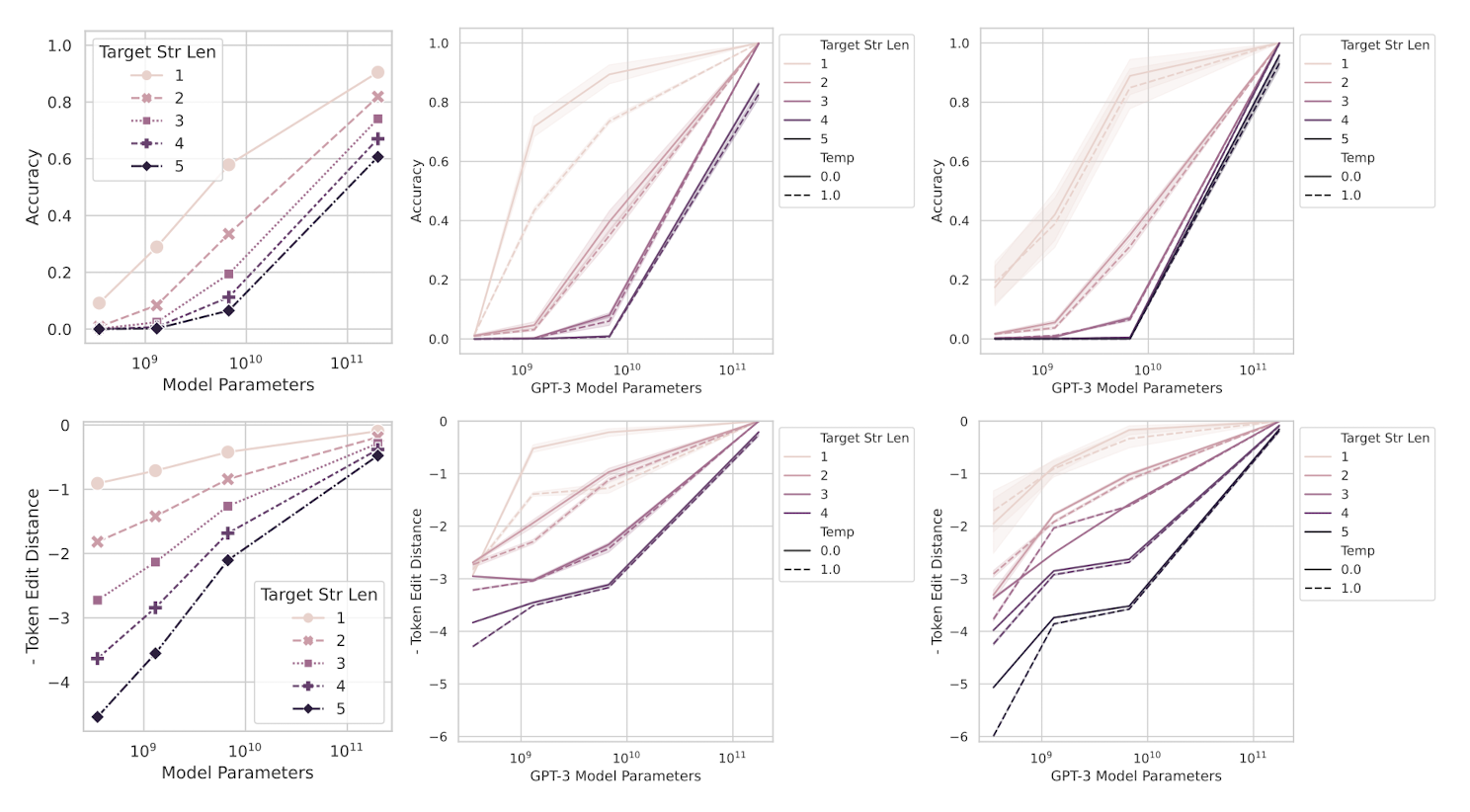
또한 기존의 평가 지표를 대상으로 emergent ability가 존재하는 metric을 확인해본 결과, 두 개의 metric이 전체의 92%를 차지했다.
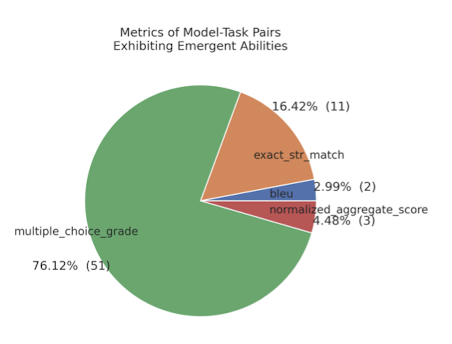
multiple choice grade와 exact string match인데, 위에서 언급했던 것처럼 non-linear & discrete한 metirc임을 알 수 있다.
- 개인적 감상
👍🏻
LLM, 혹은 최근 인공 지능의 발전 동향에 대해서 친구와 이야기를 종종 나눌 때, 이런 현상에 대해서도 논한 적이 있었다.
나는 이런 현상이 어찌 보면 정말 ‘인간과 유사’하다는 생각을 하곤 했었다.
언어 습득 이론과 관련해서 인간이 굉장히 급격한 언어 능력 발달을 겪고 이후에는 크게 달라지지 않는 것과 비슷하고, 그 이유에 대해서 설명하기도 어렵다는 점이 굉장히 닮아 있다고 느꼈기 때문이다.
하지만 본 논문에서 이를 수학적으로 접근해서 날카롭게 지적한 것이 굉장히 통쾌하고 재밌다고 느껴졌다.
항상 애매했던 것 중 하나는, ‘왜 모델 사이즈를 키우면 성능이 좋아지는데?’***라는 질문에 마땅한 답변이 없다는 것이었다.
만약 위 논리가 대부분의 인공 지능 분야에 적용될 수 있는 거라면 모델의 사이즈와 성능의 상관 관계에 대해 보다 설득력있는 설명을 할 수 있게 되는 것이 아닐까?
👎🏻
하지만 왜 vision 모델로 실험했는지 이해가 되지 않는다.
물론 실험을 통해서 자신들의 가설을 입증하는 데 성공했지만, 그렇다면 결국 태스크에 적합한 metric이 존재함을 반증하는 것 같기도 했다.
예를 들어 LLM이 반환하는 답변이 사람의 선호에 적합한지를 1~5점으로 매기는 multi choice 방식이라고 한다면, 이를 무엇으로 대체 가능하다는 것일까 의문이 들었다.
애초에 추상적인 감각을 수치화하는 과정에서 발생할 수밖에 없는 현상이 아닐까, 그렇다면 설명할 수 없는 emergent ability가 태스크에 따라 다르게 나타날 수 있다는 것도 옳은 설명이 될 수 있지 않을까, 생각이 들었다.
특히나 최근 연구들의 방향성이 ‘많은 사람들이 선호’하는 방향으로 pre-training/tuning 하기도 하므로 어찌 보면 가치 판단의 문제로 넘어갈 수도 있겠다 싶다.
출처 : https://arxiv.org/abs/2304.15004
Are Emergent Abilities of Large Language Models a Mirage?
Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguing is two-fold: their sharpness, transitioning seemingly
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
노션에 정리한 것을 그대로 긁어왔는데, 혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLM에서 갑자기 등장하는 파워풀한 능력, emergent ability는 실재하는 것이 아니다.
연구자들의 편협한 metric 선택이 불러온 결과.
- 배경
LLM이 지닌 엄청난 능력이 주목을 받게 된 것은 GPT-3와 같이 파격적인 모델 파라미터 구성으로 학습을 진행한 시점부터였다.
흥미로운 것은 모델의 사이즈가 작았을 때 눈 씻고 봐도 찾을 수 없었던 능력이, 모델의 사이즈를 키우면서 ‘갑작스럽게’ 등장한다는 점이었다.
대표적인 예로 in-context-learning(이를 학습으로 볼 수 있는지에 대한 의견도 분분하지만) 등을 들 수 있다.
현재까지도 이러한 현상에 대해 많은 사람들이 의문을 품고 있는 상황에서, 본 논문은 이런 현상이 허구라고 지적한다.
- 핵심 주장
- emergent ability는 nonlinear metric으로 평가했기 때문에 그렇게 보이는 것 뿐이다.
linear metric으로 평가하면 준선형(quasilinear) 그래프가 그려진다.
예를 들어 multi choice로 모델 성능을 평가하면 애초에 discrete한 평가 방식이라는 점을 지적한 것. - higher resolution evaluation을 하면 emergent ability가 사라진다. 어떤 accuracy를 선택하는지가 이 현상 발생 유무에 영향을 준다. (1번과 크게 구분되는 내용은 아닌 듯하다)
- 재밌는 실험 결과
정답의 길이가 길수록 모델 성능은 확 떨어질 수밖에 없는 구조이다.
원래 각 토큰의 정확도를 토대로 답변의 accuracy를 구하는 식은 위와 같은데, 덕분에 토큰 길이에 비례하여 정확도가 급격하게(sharpness) 떨어질 것을 알 수 있다.
그래서 이를 Token Edit Distance로 수정하면 다른 결과가 나타난다.
또한 기존의 평가 지표를 대상으로 emergent ability가 존재하는 metric을 확인해본 결과, 두 개의 metric이 전체의 92%를 차지했다.
multiple choice grade와 exact string match인데, 위에서 언급했던 것처럼 non-linear & discrete한 metirc임을 알 수 있다.
- 개인적 감상
👍🏻
LLM, 혹은 최근 인공 지능의 발전 동향에 대해서 친구와 이야기를 종종 나눌 때, 이런 현상에 대해서도 논한 적이 있었다.
나는 이런 현상이 어찌 보면 정말 ‘인간과 유사’하다는 생각을 하곤 했었다.
언어 습득 이론과 관련해서 인간이 굉장히 급격한 언어 능력 발달을 겪고 이후에는 크게 달라지지 않는 것과 비슷하고, 그 이유에 대해서 설명하기도 어렵다는 점이 굉장히 닮아 있다고 느꼈기 때문이다.
하지만 본 논문에서 이를 수학적으로 접근해서 날카롭게 지적한 것이 굉장히 통쾌하고 재밌다고 느껴졌다.
항상 애매했던 것 중 하나는, ‘왜 모델 사이즈를 키우면 성능이 좋아지는데?’***라는 질문에 마땅한 답변이 없다는 것이었다.
만약 위 논리가 대부분의 인공 지능 분야에 적용될 수 있는 거라면 모델의 사이즈와 성능의 상관 관계에 대해 보다 설득력있는 설명을 할 수 있게 되는 것이 아닐까?
👎🏻
하지만 왜 vision 모델로 실험했는지 이해가 되지 않는다.
물론 실험을 통해서 자신들의 가설을 입증하는 데 성공했지만, 그렇다면 결국 태스크에 적합한 metric이 존재함을 반증하는 것 같기도 했다.
예를 들어 LLM이 반환하는 답변이 사람의 선호에 적합한지를 1~5점으로 매기는 multi choice 방식이라고 한다면, 이를 무엇으로 대체 가능하다는 것일까 의문이 들었다.
애초에 추상적인 감각을 수치화하는 과정에서 발생할 수밖에 없는 현상이 아닐까, 그렇다면 설명할 수 없는 emergent ability가 태스크에 따라 다르게 나타날 수 있다는 것도 옳은 설명이 될 수 있지 않을까, 생각이 들었다.
특히나 최근 연구들의 방향성이 ‘많은 사람들이 선호’하는 방향으로 pre-training/tuning 하기도 하므로 어찌 보면 가치 판단의 문제로 넘어갈 수도 있겠다 싶다.
출처 : https://arxiv.org/abs/2304.15004
Are Emergent Abilities of Large Language Models a Mirage?
Recent work claims that large language models display emergent abilities, abilities not present in smaller-scale models that are present in larger-scale models. What makes emergent abilities intriguing is two-fold: their sharpness, transitioning seemingly
arxiv.org