최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
모델이 추론하는 과정에서 스스로 생성한 QA(note)를 참고해 보다 정확한 추론을 가능하도록 만든 모델
- 배경
지금까지의 인공지능 모델들은 multi-step reasoning에 대해 취약한 모습을 보이고 있다.
왜냐하면 여러 단계를 한 번에 압축하여 추론하므로 모델의 입장에서 여러 요소를 충분히 고려할 수 없게 되기 때문이다.
즉 여러 state가 주어졌을 때, state-traking 혹은 highly nonlinear 문제들을 풀어낼 수가 없는 것이다.
따라서 본 논문에서는 multi-step reasoning을 진행하는 과정에서, 주어진 문장에 대해 모델 스스로 질문 & 답변하고, 이를 마지막 추론 과정에서 활용함으로써 추론의 정확도를 높였다.
이렇게 현재 상태를 더욱 잘 tracking할 수 있도록 만든 기법을 Self-Notes라고 부른다.
- 모델 컨셉
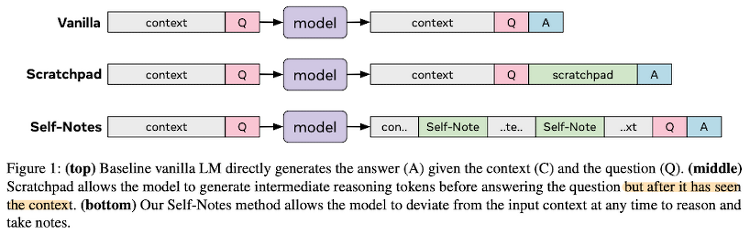
기존의 모델은 Vanilla라고 부르고, 기존 모델의 한계를 극복하기 위해 이전에 제안되었던 방법인 Scratchpad와 본 논문에서 제안하는 Self-Notes의 구조를 도식화한 것은 다음과 같다.
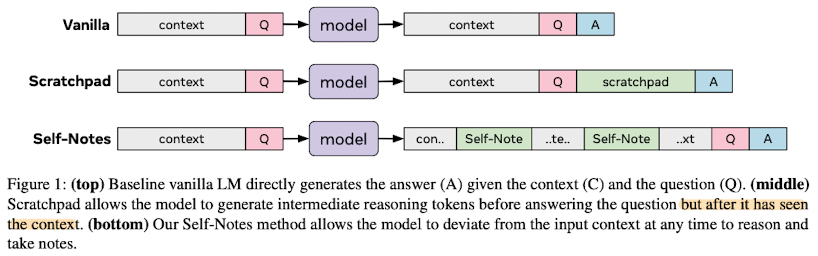
결과적으로 말하자면 Scratchpad 방식은 Question과 Answer 사이에 요약본을 집어 넣는 방식으로 Self-Notes에 비해 아쉬운 퍼포먼스를 보인다.(난이도가 상대적으로 낮은 특정 태스크에서는 유사한 수준의 결과가 나타남)
한편 Self-Notes 방식은 ground-truth가 존재하는 supervised, 일부 subset만 ground truth를 갖는 semi-supervised, ground truth가 존재하지 않는 unsupvervised 방식을 모두 사용하여 학습한다.
세 개를 혼합하여 학습하는 것은 아니고, 태스크에 적합한 학습 방식을 취해 모델의 성능을 검증했다.
- 개인적 감상
👍🏻
모델이 context를 구성하는 여러 문장에 대해 자동적으로 note를 생성하고 이를 기반으로 정확한 추론이 가능해진다는 개념은 아주 훌륭한 것 같다.
학습 방식에 따라 self-note의 퀄리티가 더 많이 개선되고 모델의 추론 정확도도 발전할 가능성이 있는 것으로 보인다.
특히 요즘은 이런식으로 모델이 학습 과정에서 뭔가 직접 만드는 방법론에 대한 관심도 꽤 높다는 생각이 든다.
예를 들면 instruct tuning을 하기 위한 문장 역시 자동적으로 만든다든가, CoT를 위한 데이터를 GPT로 뽑아낸다든가 하는 등의 연구도 굉장히 활발한 것 같다.
👎🏻
자원상의 한계 때문인지는 모르겠지만 GPT-2를 베이스로 사용한 것이 아쉬운 요인이라고 생각한다.
GPT-3.5 이상의 모델들의 경우(특히 GPT-4) 이전 context를 반영하는 능력이 엄청나게 뛰어나기 때문이다.
실제로 GPT-4 모델로 Chat-GPT를 사용하면서 가장 놀랐던 것 중 하나가 한참 전에 제공했던 내용을 반영한 답변이 나올 수 있다는 것이었다.
물론 이런 방법론이 유효한 것인지 확인하고 이를 확장하고자 한 것이라면 이해할 수도 있지만, GPT-3도 아니고 GPT-2를 붙잡고 원래 성능이 아쉬웠는데 이를 개선했다라고 주장하는 것이 다소 납득이 되지 않았다.
(엄청나게 많은 공부를 한 것은 아니지만 GPT-3 대신 GPT-2를 비교 기준/대상으로 삼은 것은 처음 봤다…)
출처 : https://arxiv.org/abs/2305.00833
Learning to Reason and Memorize with Self-Notes
Large language models have been shown to struggle with limited context memory and multi-step reasoning. We propose a simple method for solving both of these problems by allowing the model to take Self-Notes. Unlike recent scratchpad approaches, the model c
arxiv.org
'Paper Review' 카테고리의 다른 글
| <Multi-modal> [LLaVA] Visual Instruction Tuning (0) | 2023.05.10 |
|---|---|
| <Prompt> [Gist] Learning to Compress Prompts with Gist Tokens (1) | 2023.05.09 |
| <PEFT> LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model (0) | 2023.05.07 |
| <Evaluation> Are Emergent Abilities of Large Language Models a Mirage? (0) | 2023.05.03 |
| <Evaluation> Evaluating Verifiability in Generative Search Engines (0) | 2023.05.02 |