
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
이미지의 특정 포인트를 ‘잡아 당겨서’ 원하는대로 변환할 수 있도록 만드는 GAN 기반 모델

최근 가장 화제인 논문 중 하나로, 이미지를 변형하는 모델이라고 볼 수 있습니다.
이런 분야가 주목을 받은 이유 중 하나는 자연어로 이미지를 변형 시키는 기술이 나타났기 때문인데요, 예를 들어 Microsoft Designer라는 서비스를 보면, 인공지능에게 프롬프트를 입력하여 여러 이미지(디자인 관련)를 생성하거나 변형할 수 있습니다.
그러나 자연어만으로는 정밀한 컨트롤(예를 들어 물체를 몇 픽셀 정교하게 이동)이 불가능하기 때문에 기존의 모델을 더 발전시킨 연구가 진행되었던 것 같습니다.
주목할만한 특징들이 몇 가지 있습니다.
1. Drag 방식
사실 이게 별 거 아닌 것처럼 느껴질수도 있긴 한데, 사용자의 편의성을 위하여 UX적인 측면 또한 고려했음이 논문 내용에 포함되어 있습니다.
사용자가 굉장히 직관적으로 이미지 변형을 할 수 있도록 시스템을 구성한 것이죠.
게다가 원하는대로 변형이 굉장히 잘 이뤄지는, 즉 모델 성능이 뛰어난 상황임에도 불구하고 이전 모델들에 비해 추론(처리) 시간이 체감할 수준으로 더 길어진 것은 아니라고 합니다.
2. Dataset
가장 의아한 것은 학습에 필요한 데이터를 어떻게 구했느냐 하는 것이었습니다.
이 부분에서 놀랐던 것은 제가 이 분야에 대해 관심이 없었을 뿐이지, 이미 관련 태스크를 위한 데이터셋이나 모델 정보가 적지는 않았다는 것입니다.
3. 학습 방식
모델의 학습을 위해 자체적으로 loss를 설정한 것도 좋았지만(배경 지식이 부족해서 수식적 이해는 못했지만요), 다른 것보다도 이 분야에서의 학습 방식이 재밌었던 것 같습니다.
대표적인 것을 하나만 꼽자면, 1) 이미지에서 변경이 가능한 point의 개수를 설정합니다. 2) 시작 point → 도착 point로 모델이 이미지를 변형합니다. 3) 변형된 이미지를 target과 비교합니다.
이때 point라는 것이 잘 이해되지 않을 수도 있긴 한데, 이미지에서 인공지능 모델을 통해 추출하는 ‘landmark’입니다.
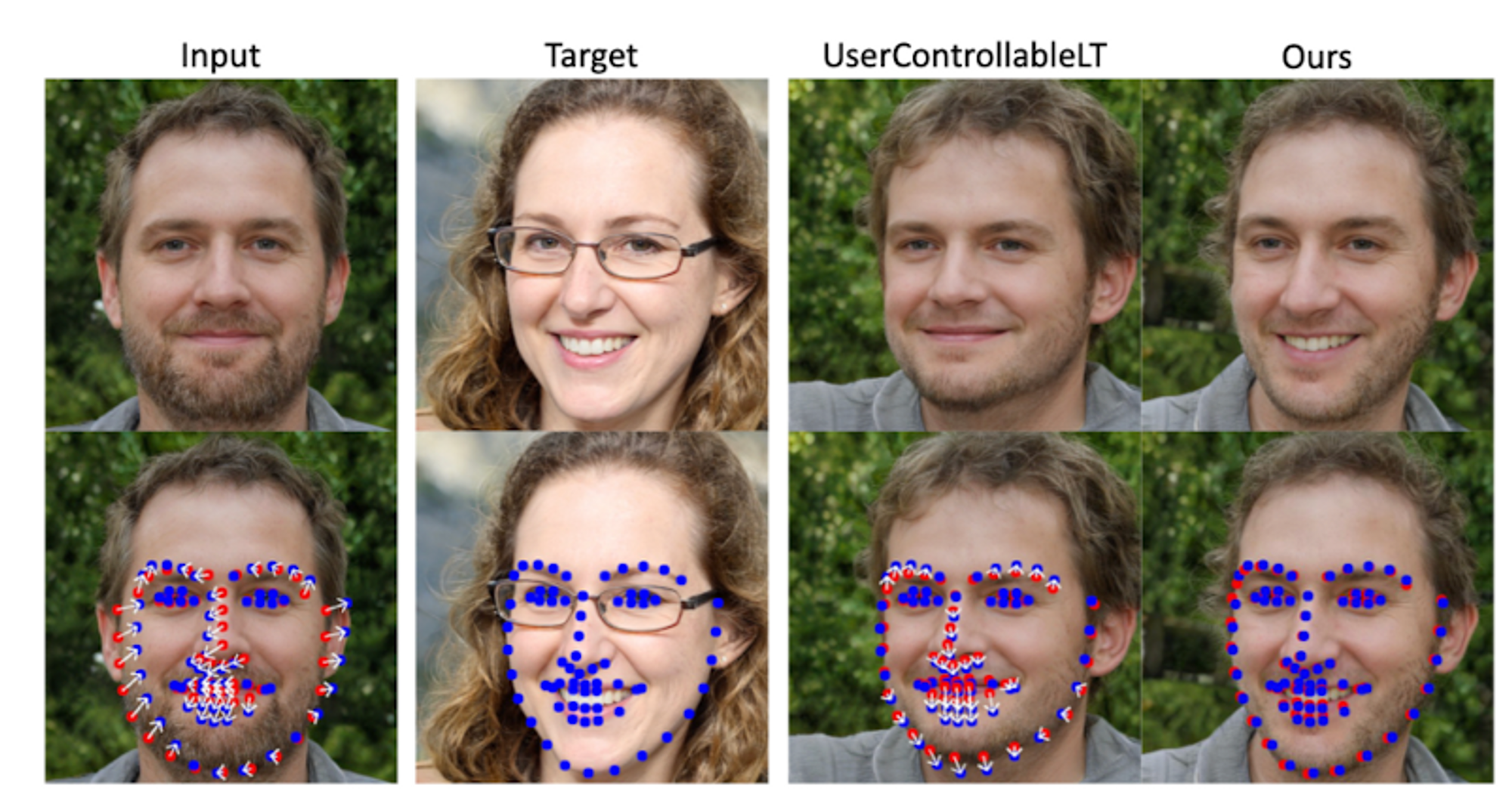
조금 징그럽긴 합니다만… 이처럼 사진에서 자동적으로 추출될 수 있는 포인트들을 기준으로 모델이 학습을 수행하게 되는 것이죠.
이상으로, 사실 제가 잘 알지 못하는 도메인인데 엄청 핫한 논문이라고 뜨는 것 같아서 알아보다가 읽고 정리해보았습니다.
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
이미지의 특정 포인트를 ‘잡아 당겨서’ 원하는대로 변환할 수 있도록 만드는 GAN 기반 모델
최근 가장 화제인 논문 중 하나로, 이미지를 변형하는 모델이라고 볼 수 있습니다.
이런 분야가 주목을 받은 이유 중 하나는 자연어로 이미지를 변형 시키는 기술이 나타났기 때문인데요, 예를 들어 Microsoft Designer라는 서비스를 보면, 인공지능에게 프롬프트를 입력하여 여러 이미지(디자인 관련)를 생성하거나 변형할 수 있습니다.
그러나 자연어만으로는 정밀한 컨트롤(예를 들어 물체를 몇 픽셀 정교하게 이동)이 불가능하기 때문에 기존의 모델을 더 발전시킨 연구가 진행되었던 것 같습니다.
주목할만한 특징들이 몇 가지 있습니다.
1. Drag 방식
사실 이게 별 거 아닌 것처럼 느껴질수도 있긴 한데, 사용자의 편의성을 위하여 UX적인 측면 또한 고려했음이 논문 내용에 포함되어 있습니다.
사용자가 굉장히 직관적으로 이미지 변형을 할 수 있도록 시스템을 구성한 것이죠.
게다가 원하는대로 변형이 굉장히 잘 이뤄지는, 즉 모델 성능이 뛰어난 상황임에도 불구하고 이전 모델들에 비해 추론(처리) 시간이 체감할 수준으로 더 길어진 것은 아니라고 합니다.
2. Dataset
가장 의아한 것은 학습에 필요한 데이터를 어떻게 구했느냐 하는 것이었습니다.
이 부분에서 놀랐던 것은 제가 이 분야에 대해 관심이 없었을 뿐이지, 이미 관련 태스크를 위한 데이터셋이나 모델 정보가 적지는 않았다는 것입니다.
3. 학습 방식
모델의 학습을 위해 자체적으로 loss를 설정한 것도 좋았지만(배경 지식이 부족해서 수식적 이해는 못했지만요), 다른 것보다도 이 분야에서의 학습 방식이 재밌었던 것 같습니다.
대표적인 것을 하나만 꼽자면, 1) 이미지에서 변경이 가능한 point의 개수를 설정합니다. 2) 시작 point → 도착 point로 모델이 이미지를 변형합니다. 3) 변형된 이미지를 target과 비교합니다.
이때 point라는 것이 잘 이해되지 않을 수도 있긴 한데, 이미지에서 인공지능 모델을 통해 추출하는 ‘landmark’입니다.
조금 징그럽긴 합니다만… 이처럼 사진에서 자동적으로 추출될 수 있는 포인트들을 기준으로 모델이 학습을 수행하게 되는 것이죠.
이상으로, 사실 제가 잘 알지 못하는 도메인인데 엄청 핫한 논문이라고 뜨는 것 같아서 알아보다가 읽고 정리해보았습니다.