
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
마인크래프트에서 LLM으로 오랫동안 생존할 수 있는 agent를 만든 논문.
기존에 비해 3배 이상의 아이템 종류 생성, 2배 이상의 탐색, 15배 이상의 테크 속도를 달성.

- 배경
최근 강화학습 분야에서 구체화된 agent를 생성하는 것에 LLM이 활용되는 경향이 로보틱스나 게임에 활용되고 있습니다.
그러나 agent가 지식을 쌓거나 업데이트하거나 전이하지 못해 오래 생존하지 못한다는 한계를 지니고 있었죠.
본 논문에서는 LLM으로
- 각 시점에 대해 적절한 태스크를 제안하고 - automatic curriculum
- 환경적 피드백을 통해 스킬을 연마하여 저장하고 - skill library
- self-driven 방식으로 세상을 지속적으로 탐험하는 - iterative prompting mechanism
agent를 만든 내용을 다루고 있습니다.
(이때 엄청나게 길면서도 체계화된 프롬프트가 활용되었습니다)
얼마 전 스탠포드 대학에서 Generative Agents라는 논문을 냈는데,
여기에서도 LLM으로 어떤 agent나 주변 환경을 세팅(본 논문에서는 feedback)해준다는 점이 굉장히 유사하다고 느껴집니다.

- 컨셉
1) Automatic Curriculum
GPT-4를 이용해 계속해서 새로운 태스크에 도전할 수 있도록 커리큘럼을 제시해줍니다.
이때 바람직한 행동, agent의 현재 상태, 이전에 성공/실패한 태스크들, 추가적인 문맥 등을 프롬프트로 제공합니다.
2) Skill Library
agent가 지속적으로 학습하고 진화하기 위해서는 습득한 스킬을 저장하는 것이 필수적입니다.
이때 코드 생성을 위한 가이드라인, API와 관련 스킬들을 컨트롤, GPT의 self-improve, agent의 현재 상태, Chain-of-thought 등을 프롬프트로 제공합니다.
3) Iterative Prompting Mechanism
세 종류의 피드백을 통해 self-improvement를 달성하는 프롬프트 매커니즘입니다.
이때 환경 피드백, 실행 에러, self-verification(태스크 성공 여부 확인)이 세 종류의 피드백에 해당합니다.
- 베이스라인 및 실험 결과
- ReAct : reasoning trace와 action plan을 LLM으로 생성하여 chain-of-thought prompting을 사용
- Reflexion : self-reflection을 통해 직관적인 미래 행동을 추론
- AutoGPT : high-level goal을 여러 개의 subgoal로 나누어 ReAct 스타일의 loop를 실행
- Voyager : 역시 high-level 컨트롤
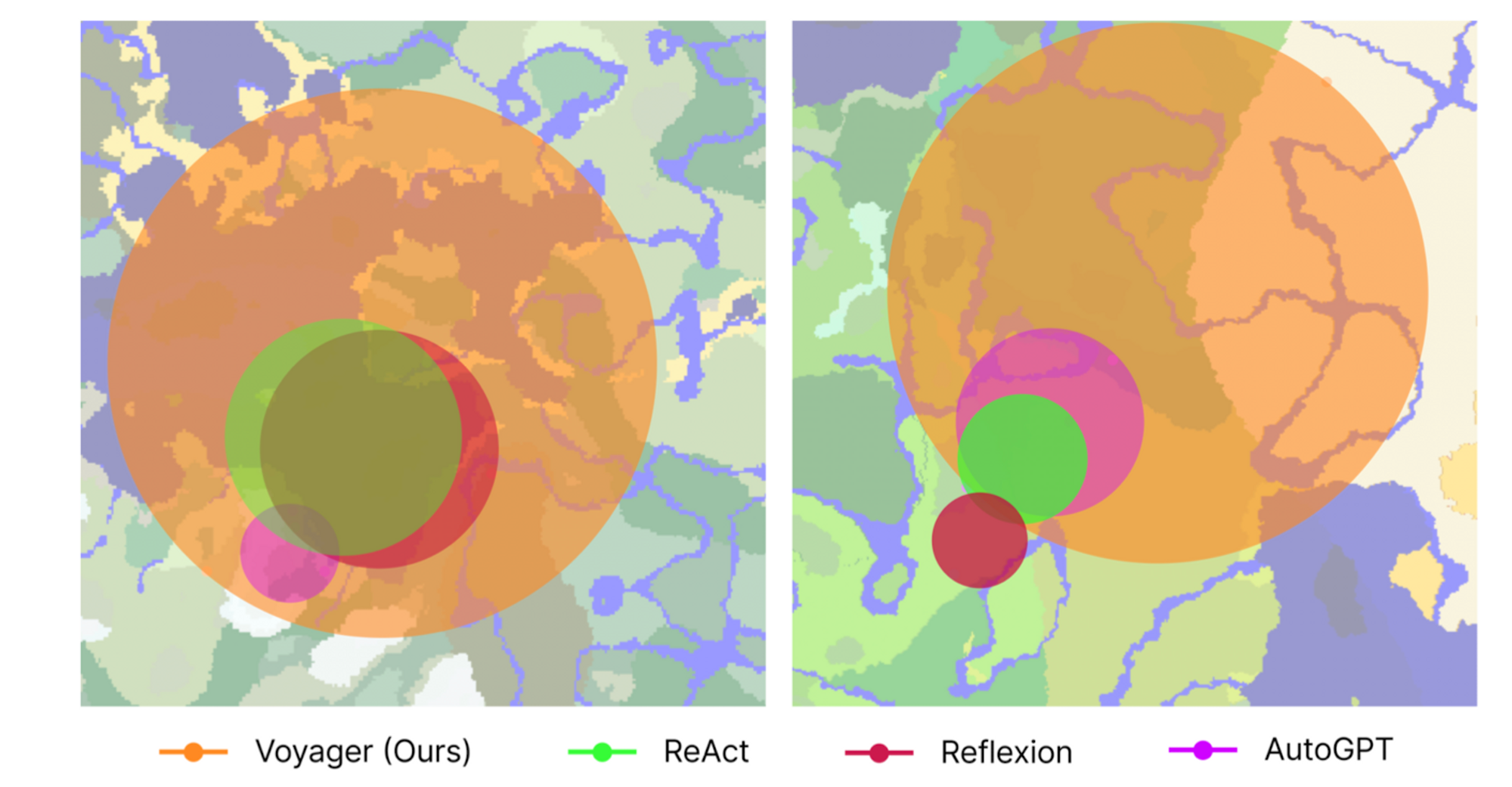

결과적으로 탐험 반경, 테크 트리 마스터 속도, 새로운 아이템 제작에서 엄청난 성능 향상을 보여주었습니다.
또한 이전에 만나보지 못했던 태스크에 대한 일반화 성능이 뛰어납니다.
이는 학습된 것들만 잘 수행했던 다른 베이스라인들과 구분되는 강점입니다.
두드러지는 특징 중 하나는 Multimodal Feedback from Humans입니다.
GPT-4는 현재까지 이미지 인식을 지원하고 있지 않기 때문에(도대체 언제 되는 건데..?), 본 모델도 시각적 정보를 활용하지 않고 오직 언어적인 정보만을 가지고 agent를 조종하는 것입니다.
그런데 여기에 human feedback(진짜 만능인가?)을 제공하면 본 모델이 3D 구조물을 만들 수 있다고 합니다.
이때는 self-verification 역할을 Human critic이 대신하고, Human curriculum이 automatic curriculum module 역할을 대신합니다.

- 개인적 감상
👍🏻
이 논문을 보게 된 큰 이유 중 하나가 스탠포드 대학의 Generative Agents 논문입니다.
개인적으로 너무 재밌게 봤었던 논문인데, 컨셉에 유사한 점이 있고 마인크래프트 소재가 재밌어서 읽게 되었네요.
어찌보면 이것도 프롬프트 엔지니어링(거부감을 느끼시는 분들이 많은 바로 그것..!)의 일환이라고도 느껴집니다.
물론 연구 결과를 보면 self-verification의 적용 여부가 성능에 가장 큰 영향을 주었다고는 하지만, 개인적으로는 도메인에 가장 적합한 기술은 오히려 skill library를 만들어 준 것이라는 생각이 듭니다.
논문을 직접 보시면 아실 수도 있겠지만, 실제로 적용했다고 하는 system prompt 등을 보면 그 길이가 말도 안 되게 길고 체계적입니다.

GPT-4를 따로 모델적으로 건드리지 않고 API를 사용한 것 같은데,
그것만으로 기존 연구들의 결과를 한참 웃도는 성능을 뿜어낸 것은 프롬프트 엔지니어링을 잘 적용한 덕분일까, 싶습니다.
👎🏻
비용 문제가 가장 먼저 지적될 것 같습니다.
논문에도 명시되어 있습니다만 GPT-4는 GPT-3.5에 비해 약 15배나 비싸죠.
agent가 모험을 얼마나 오랫동안 했는지는 모르겠습니다만, 이정도 길이의 프롬프트를 받고 행동을 수행하며 여러 메세지를 다시 입력으로 제공한다면 꽤나 많은 비용이 들 것입니다.
또 skill library의 경우 데이터가 계속해서 누적되는 형태인데(self-verification도 마찬가지겠죠. 태스크의 성공 여부를 담게 되니까), 이에 대한 언급이 없습니다.
간단히 생각해보면 담고 있는 내용이 엄청나게 길어지게 되면 해석력이 떨어져서 부정확한 명령을 수행할수도 있을 것이고, 한편으로는 정확한 명령을 수행하더라도 retrieval/inference 시간이 길어지거나 비용이 누적 증가하는 문제점이 발생할 수 있겠다는 생각이 들었습니다.
출처 : https://arxiv.org/abs/2305.16291?utm_source=substack&utm_medium=email
Voyager: An Open-Ended Embodied Agent with Large Language Models
We introduce Voyager, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Voyager consists of three key components: 1) an
arxiv.org
https://arxiv.org/abs/2304.03442
Generative Agents: Interactive Simulacra of Human Behavior
Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents--computational software ag
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
마인크래프트에서 LLM으로 오랫동안 생존할 수 있는 agent를 만든 논문.
기존에 비해 3배 이상의 아이템 종류 생성, 2배 이상의 탐색, 15배 이상의 테크 속도를 달성.
- 배경
최근 강화학습 분야에서 구체화된 agent를 생성하는 것에 LLM이 활용되는 경향이 로보틱스나 게임에 활용되고 있습니다.
그러나 agent가 지식을 쌓거나 업데이트하거나 전이하지 못해 오래 생존하지 못한다는 한계를 지니고 있었죠.
본 논문에서는 LLM으로
- 각 시점에 대해 적절한 태스크를 제안하고 - automatic curriculum
- 환경적 피드백을 통해 스킬을 연마하여 저장하고 - skill library
- self-driven 방식으로 세상을 지속적으로 탐험하는 - iterative prompting mechanism
agent를 만든 내용을 다루고 있습니다.
(이때 엄청나게 길면서도 체계화된 프롬프트가 활용되었습니다)
얼마 전 스탠포드 대학에서 Generative Agents라는 논문을 냈는데,
여기에서도 LLM으로 어떤 agent나 주변 환경을 세팅(본 논문에서는 feedback)해준다는 점이 굉장히 유사하다고 느껴집니다.
- 컨셉
1) Automatic Curriculum
GPT-4를 이용해 계속해서 새로운 태스크에 도전할 수 있도록 커리큘럼을 제시해줍니다.
이때 바람직한 행동, agent의 현재 상태, 이전에 성공/실패한 태스크들, 추가적인 문맥 등을 프롬프트로 제공합니다.
2) Skill Library
agent가 지속적으로 학습하고 진화하기 위해서는 습득한 스킬을 저장하는 것이 필수적입니다.
이때 코드 생성을 위한 가이드라인, API와 관련 스킬들을 컨트롤, GPT의 self-improve, agent의 현재 상태, Chain-of-thought 등을 프롬프트로 제공합니다.
3) Iterative Prompting Mechanism
세 종류의 피드백을 통해 self-improvement를 달성하는 프롬프트 매커니즘입니다.
이때 환경 피드백, 실행 에러, self-verification(태스크 성공 여부 확인)이 세 종류의 피드백에 해당합니다.
- 베이스라인 및 실험 결과
- ReAct : reasoning trace와 action plan을 LLM으로 생성하여 chain-of-thought prompting을 사용
- Reflexion : self-reflection을 통해 직관적인 미래 행동을 추론
- AutoGPT : high-level goal을 여러 개의 subgoal로 나누어 ReAct 스타일의 loop를 실행
- Voyager : 역시 high-level 컨트롤
결과적으로 탐험 반경, 테크 트리 마스터 속도, 새로운 아이템 제작에서 엄청난 성능 향상을 보여주었습니다.
또한 이전에 만나보지 못했던 태스크에 대한 일반화 성능이 뛰어납니다.
이는 학습된 것들만 잘 수행했던 다른 베이스라인들과 구분되는 강점입니다.
두드러지는 특징 중 하나는 Multimodal Feedback from Humans입니다.
GPT-4는 현재까지 이미지 인식을 지원하고 있지 않기 때문에(도대체 언제 되는 건데..?), 본 모델도 시각적 정보를 활용하지 않고 오직 언어적인 정보만을 가지고 agent를 조종하는 것입니다.
그런데 여기에 human feedback(진짜 만능인가?)을 제공하면 본 모델이 3D 구조물을 만들 수 있다고 합니다.
이때는 self-verification 역할을 Human critic이 대신하고, Human curriculum이 automatic curriculum module 역할을 대신합니다.
- 개인적 감상
👍🏻
이 논문을 보게 된 큰 이유 중 하나가 스탠포드 대학의 Generative Agents 논문입니다.
개인적으로 너무 재밌게 봤었던 논문인데, 컨셉에 유사한 점이 있고 마인크래프트 소재가 재밌어서 읽게 되었네요.
어찌보면 이것도 프롬프트 엔지니어링(거부감을 느끼시는 분들이 많은 바로 그것..!)의 일환이라고도 느껴집니다.
물론 연구 결과를 보면 self-verification의 적용 여부가 성능에 가장 큰 영향을 주었다고는 하지만, 개인적으로는 도메인에 가장 적합한 기술은 오히려 skill library를 만들어 준 것이라는 생각이 듭니다.
논문을 직접 보시면 아실 수도 있겠지만, 실제로 적용했다고 하는 system prompt 등을 보면 그 길이가 말도 안 되게 길고 체계적입니다.
GPT-4를 따로 모델적으로 건드리지 않고 API를 사용한 것 같은데,
그것만으로 기존 연구들의 결과를 한참 웃도는 성능을 뿜어낸 것은 프롬프트 엔지니어링을 잘 적용한 덕분일까, 싶습니다.
👎🏻
비용 문제가 가장 먼저 지적될 것 같습니다.
논문에도 명시되어 있습니다만 GPT-4는 GPT-3.5에 비해 약 15배나 비싸죠.
agent가 모험을 얼마나 오랫동안 했는지는 모르겠습니다만, 이정도 길이의 프롬프트를 받고 행동을 수행하며 여러 메세지를 다시 입력으로 제공한다면 꽤나 많은 비용이 들 것입니다.
또 skill library의 경우 데이터가 계속해서 누적되는 형태인데(self-verification도 마찬가지겠죠. 태스크의 성공 여부를 담게 되니까), 이에 대한 언급이 없습니다.
간단히 생각해보면 담고 있는 내용이 엄청나게 길어지게 되면 해석력이 떨어져서 부정확한 명령을 수행할수도 있을 것이고, 한편으로는 정확한 명령을 수행하더라도 retrieval/inference 시간이 길어지거나 비용이 누적 증가하는 문제점이 발생할 수 있겠다는 생각이 들었습니다.
출처 : https://arxiv.org/abs/2305.16291?utm_source=substack&utm_medium=email
Voyager: An Open-Ended Embodied Agent with Large Language Models
We introduce Voyager, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Voyager consists of three key components: 1) an
arxiv.org
https://arxiv.org/abs/2304.03442
Generative Agents: Interactive Simulacra of Human Behavior
Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents--computational software ag
arxiv.org