
이전에 OpenAI에서 게재한 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[OpenAI] 고품질의 언어-수학 문제(8.5K개)로 구성된 데이터셋 구축. verifier를 학습시켜서 모델의 문제 풀이 능력을 향상 시킴.
- 배경
2021년 당시에도 LLM(Large Language Model)들의 능력에 대해 많은 관심이 있었는데, 이 모델들의 한계 중 대표적으로 꼽히는 것이 수학 문제 풀이 능력이었습니다.
정확히는 multi-step mathematical reasoning인데요, 다른 분야에서 뛰어난 퍼포먼스를 보여준 것과 달리 이 태스크에 대해서는 문제를 굉장히 쉽게 준다고 하더라도 잘 맞히지 못했죠.
사실 이런 수학적/논리적 문제를 인공지능 모델이 잘 풀기는 원래 어려운데요, 특히 생성 모델들의 학습 방식은 주로 ‘다음 토큰을 예측’하는 방식이기 때문입니다.
어떤 맥락 혹은 문맥을 이해한다기 보다는 이전에 생성된 토큰들을 바탕으로 다음 토큰을 예측하기 때문에, 학습한 확률 분포에 기반하여 다음에 등장할 확률이 가장 높은 토큰을 고르는 것 뿐이라는 뜻입니다.
즉 문장을 구성하는 내용들의 논리적인 구조를 이해한다고 보기 어렵다는 거죠.
물론 지금에 이르러서는 mult-step이라고 하자마자 Chain-of-Thought(CoT) 기법을 떠올릴 수 있지만 이것도 22년도에 나온 것이니까요 ㅎㅎ..
본 논문에서는 verifier라는 장치를 통해 모델이 반환한 결과의 정확도를 스스로 판단하도록 학습시킵니다.
- 컨셉 & 결과
1) GSM8K
언어 모델의 수학적 능력을 검증하기 위해서 새로운 데이터셋을 구축했습니다.
특히 신경을 쓴 부분은 언어적인 능력을 기반으로 문제 풀이 능력을 확인하는 데이터셋이라는 것입니다.
왜냐하면 그것이 곧 LLM의 능력을 파악하는 것이라고 봤기 때문이죠.
(쉽게 말하자면 숫자, 문자로만 이뤄진 문제로 구성된 데이터셋과 다르다는 뜻입니다)
2) verifier
이전과 비교하자면 모델을 단순히 finetuning하는 것보다 훨씬 좋은 결과를 불러온 기법입니다.
모델이 solution으로 반환한 결과에 대해 스스로 정확도를 분석하고 top k개를 voting하도록 학습시켰습니다.
이때 각 문제에 대해 100개의 solution을 반환하도록 했습니다.
또한 반환 결과에 대해 최종적으로 한 번 verification하는 것과 각 토큰 별로 verification 하는 방식 중에서 후자가 훨씬 유의미한 성능 향상으로 이어진다는 것이 확인되었습니다.
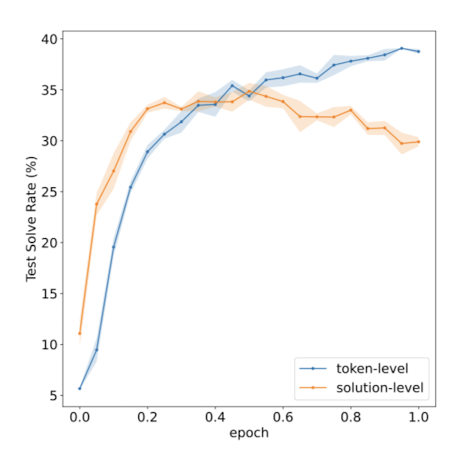
결과를 생성하는 generator와 이를 검증하는 verifier 중에는 전자의 사이즈를 키우는 것이 훨씬 중요하다고 합니다.
둘 중 하나만 사이즈를 키울 수 있다면 generator를 키우고 verifier를 작게 유지하는 것이 최적의 선택이 된다는 것이죠.
3) dropout
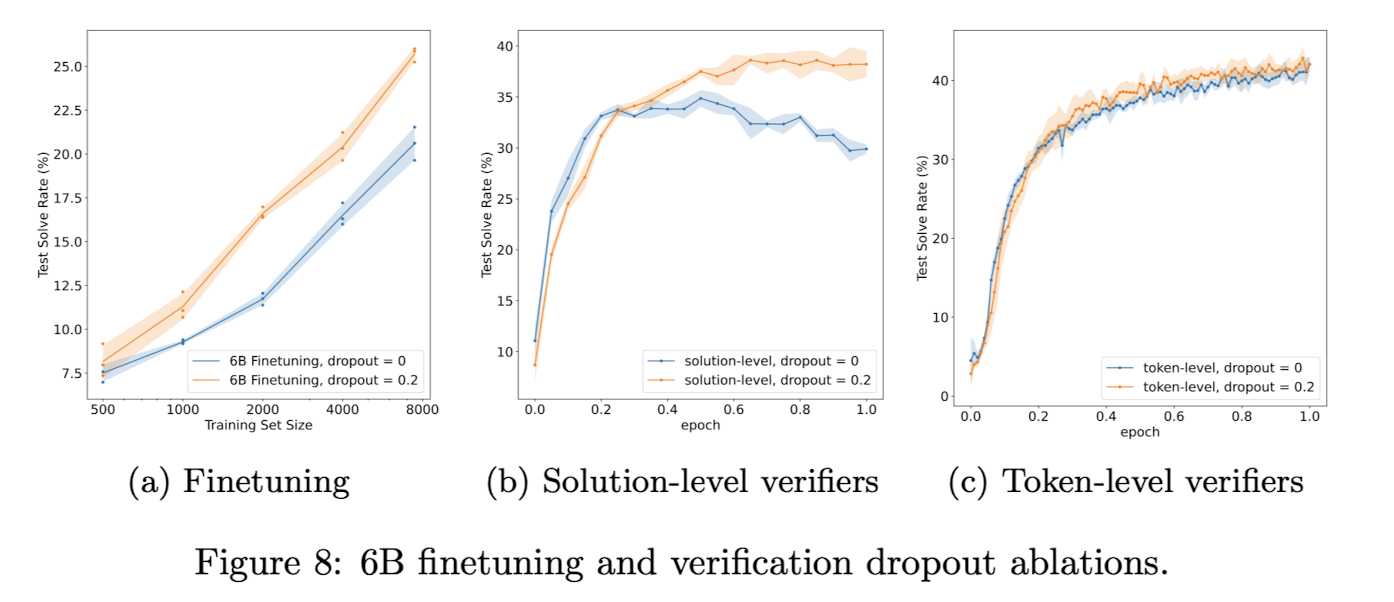
본 논문에서는 베이스라인으로 GPT-3를 사용하는데, 원래 GPT-3에는 dropout 기법 없이 사전학습 되었다고 합니다.
따라서 residual dropout을 0.2 비율로 적용하되, 모델을 finetuning하기 전에 dropout을 적용하여 추가 사전학습을 진행해줘야 했다고 하네요.
이때 토큰 단위로 verify 하는 것과 solution 단위로 verify 하는 것 중에서는 전자가 원래 더 overfitting에 강건한 학습 방식이었기 때문에 dropout으로 얻는 성능 향상의 폭은 더 작았으나, 어쨌든 어떤 방식에 대해서든지 dropout이 성능 향상으로 이어진 것은 맞다고 합니다.
- 개인적 감상
최근 생성 관련해서 코드들을 찾아보고 직접 구현을 시도하고 있는데 생각보다 접근 방법이 많이 달라서 어렵다고 느꼈습니다.
LLM에 대한 관심이 많다면서 이런 것도 잘 모르고 있다는게 부끄럽기도 하고..
어쨌든 거대 언어 모델의 능력을 파악하기 위해서 양질의 데이터셋을 새로 구축하여 공개했다는 점도 정말 대단하다는 생각이 들고, 모델 스스로 정답에 대한 신뢰도를 구할 수 있도록 유도했다는 점도 훌륭한 것 같습니다.
다만 이런 방식도 결국엔 모델이 주어진 문제에 대해 내용을 이해하고 논리적으로 답을 도출하는 것과는 무관하다는 한계를 극복한 것은 아니라서 아쉽다는 생각이 듭니다.
억까를 하자면 마치 특정 데이터셋에 적합한 학습 방식일 뿐이었달까..? 🙃
왜냐하면 기존의 너무 어려운 문제들은 모델이 잘 풀지 못해 평가 지표에서 제외한 것도 있다고 했기 때문인데요, 그런식으로 접근하자면 코드를 해석하고 적절한 코드를 제시할 수 있는 LLM의 능력도 언어적인 것과는 괴리가 있다고 볼 수 있지 않나, 그런 생각이 드네요.
출처 : https://arxiv.org/abs/2110.14168
Training Verifiers to Solve Math Word Problems
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5
arxiv.org
'Paper Review' 카테고리의 다른 글
이전에 OpenAI에서 게재한 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[OpenAI] 고품질의 언어-수학 문제(8.5K개)로 구성된 데이터셋 구축. verifier를 학습시켜서 모델의 문제 풀이 능력을 향상 시킴.
- 배경
2021년 당시에도 LLM(Large Language Model)들의 능력에 대해 많은 관심이 있었는데, 이 모델들의 한계 중 대표적으로 꼽히는 것이 수학 문제 풀이 능력이었습니다.
정확히는 multi-step mathematical reasoning인데요, 다른 분야에서 뛰어난 퍼포먼스를 보여준 것과 달리 이 태스크에 대해서는 문제를 굉장히 쉽게 준다고 하더라도 잘 맞히지 못했죠.
사실 이런 수학적/논리적 문제를 인공지능 모델이 잘 풀기는 원래 어려운데요, 특히 생성 모델들의 학습 방식은 주로 ‘다음 토큰을 예측’하는 방식이기 때문입니다.
어떤 맥락 혹은 문맥을 이해한다기 보다는 이전에 생성된 토큰들을 바탕으로 다음 토큰을 예측하기 때문에, 학습한 확률 분포에 기반하여 다음에 등장할 확률이 가장 높은 토큰을 고르는 것 뿐이라는 뜻입니다.
즉 문장을 구성하는 내용들의 논리적인 구조를 이해한다고 보기 어렵다는 거죠.
물론 지금에 이르러서는 mult-step이라고 하자마자 Chain-of-Thought(CoT) 기법을 떠올릴 수 있지만 이것도 22년도에 나온 것이니까요 ㅎㅎ..
본 논문에서는 verifier라는 장치를 통해 모델이 반환한 결과의 정확도를 스스로 판단하도록 학습시킵니다.
- 컨셉 & 결과
1) GSM8K
언어 모델의 수학적 능력을 검증하기 위해서 새로운 데이터셋을 구축했습니다.
특히 신경을 쓴 부분은 언어적인 능력을 기반으로 문제 풀이 능력을 확인하는 데이터셋이라는 것입니다.
왜냐하면 그것이 곧 LLM의 능력을 파악하는 것이라고 봤기 때문이죠.
(쉽게 말하자면 숫자, 문자로만 이뤄진 문제로 구성된 데이터셋과 다르다는 뜻입니다)
2) verifier
이전과 비교하자면 모델을 단순히 finetuning하는 것보다 훨씬 좋은 결과를 불러온 기법입니다.
모델이 solution으로 반환한 결과에 대해 스스로 정확도를 분석하고 top k개를 voting하도록 학습시켰습니다.
이때 각 문제에 대해 100개의 solution을 반환하도록 했습니다.
또한 반환 결과에 대해 최종적으로 한 번 verification하는 것과 각 토큰 별로 verification 하는 방식 중에서 후자가 훨씬 유의미한 성능 향상으로 이어진다는 것이 확인되었습니다.
결과를 생성하는 generator와 이를 검증하는 verifier 중에는 전자의 사이즈를 키우는 것이 훨씬 중요하다고 합니다.
둘 중 하나만 사이즈를 키울 수 있다면 generator를 키우고 verifier를 작게 유지하는 것이 최적의 선택이 된다는 것이죠.
3) dropout
본 논문에서는 베이스라인으로 GPT-3를 사용하는데, 원래 GPT-3에는 dropout 기법 없이 사전학습 되었다고 합니다.
따라서 residual dropout을 0.2 비율로 적용하되, 모델을 finetuning하기 전에 dropout을 적용하여 추가 사전학습을 진행해줘야 했다고 하네요.
이때 토큰 단위로 verify 하는 것과 solution 단위로 verify 하는 것 중에서는 전자가 원래 더 overfitting에 강건한 학습 방식이었기 때문에 dropout으로 얻는 성능 향상의 폭은 더 작았으나, 어쨌든 어떤 방식에 대해서든지 dropout이 성능 향상으로 이어진 것은 맞다고 합니다.
- 개인적 감상
최근 생성 관련해서 코드들을 찾아보고 직접 구현을 시도하고 있는데 생각보다 접근 방법이 많이 달라서 어렵다고 느꼈습니다.
LLM에 대한 관심이 많다면서 이런 것도 잘 모르고 있다는게 부끄럽기도 하고..
어쨌든 거대 언어 모델의 능력을 파악하기 위해서 양질의 데이터셋을 새로 구축하여 공개했다는 점도 정말 대단하다는 생각이 들고, 모델 스스로 정답에 대한 신뢰도를 구할 수 있도록 유도했다는 점도 훌륭한 것 같습니다.
다만 이런 방식도 결국엔 모델이 주어진 문제에 대해 내용을 이해하고 논리적으로 답을 도출하는 것과는 무관하다는 한계를 극복한 것은 아니라서 아쉽다는 생각이 듭니다.
억까를 하자면 마치 특정 데이터셋에 적합한 학습 방식일 뿐이었달까..? 🙃
왜냐하면 기존의 너무 어려운 문제들은 모델이 잘 풀지 못해 평가 지표에서 제외한 것도 있다고 했기 때문인데요, 그런식으로 접근하자면 코드를 해석하고 적절한 코드를 제시할 수 있는 LLM의 능력도 언어적인 것과는 괴리가 있다고 볼 수 있지 않나, 그런 생각이 드네요.
출처 : https://arxiv.org/abs/2110.14168
Training Verifiers to Solve Math Word Problems
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5
arxiv.org