
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
워싱턴 대학에서 제출한, PEFT(Parameter Efficient Fine Tuning) 기법 중 하나를 다룬 논문. 65B개 파라미터를 갖는 모델을 48GB GPU 한 장으로 finetuning할 수 있도록 만들었다.
- 배경
최근 언어 모델 관련 분야에서는 가장 주목을 받는 기술이 모델 경량화인 것 같습니다.
모델 자체를 light하게 만드는 것보다는 사전 학습된 모델을 최대한 적은 자원으로 fine tuning할 수 있도록 만드는 기술들에 관련된 것이죠.
특히 메타에서 만든 LLaMA의 등장 이후로 정말 많은 개인(물론 이것도 자원을 아예 필요로 하지 않는 것은 아니지만..)들이 LLM을 각자 fine tuning하고 원하는대로 조정하는 일들이 많이 일어났습니다.
이때 가장 많이 활용된 PEFT 기법중 하나가 LoRA입니다.
본 논문에서는 LoRA에서 한 발 더 나아간 QLoRA를 제시하는데, 기존에 비해 훨씬 효율적인 결과가 나타났음을 보고했습니다.
논문에 제시된 수치들로만 판단해보자면 7B짜리 모델은 쉽게 튜닝이 가능할 것 같고, 그것보다 사이즈가 큰 33B 혹은 65B 모델들은 클라우드 자원에 비용을 좀 들이면 튜닝이 가능한 수준인 것 같습니다.
(돈은 꽤나 들겠지만 개인이 singe GPU로 LLM을 학습시킨다는 것 자체가 대박입니다..!)
- 특징 및 성능
기존의 모델 성능을 하락시키지 않으면서도 효율적으로 튜닝을 하기 위해 적용된 방법론은 크게 세 가지입니다.
- 4-bit NormalFloat
기존에는 4-bit Integers / 4-big Floats 등의 자료형을 사용했는데, 이보다 quantization에 적합한 자료형임이 확인되었습니다. (참고로 데이터셋의 사이즈보다도 데이터의 품질-기존의 정보를 잘 유지할 수 있는지-이 더 중요하다고 합니다) - Double Quantization
quantization 상수를 quantize 하는 방법론입니다.
평균적으로 각 파라미터마다 0.37 bit를 아낄 수 있다고 합니다. - Paged Optimizers
gradient checkpointing memory spike를 방지하기 위해 NVIDIA의 통합 메모리를 사용합니다.
이는 길이가 긴 sequence를 mini-batch로 처리할 때 적합한 테크닉입니다.
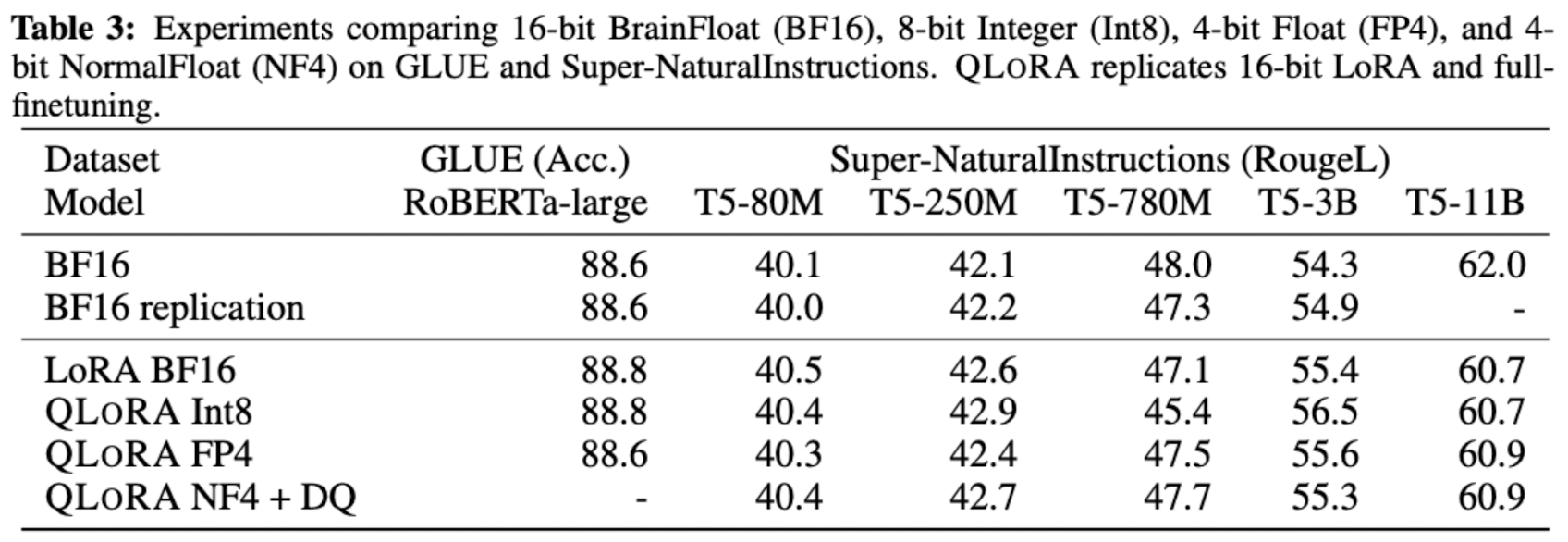
보시다시피 QLoRA가 4비트 짜리 normal float를 사용하고 double quantization을 적용한 결과가 16비트 float 자료형을 사용한 것에 이르는 것을 알 수 있습니다.
재밌는 것은 이 논문에서도 결과에 대한 평가를 ‘사람 + GPT-4’로 했다고 합니다.
최근 정말 많은 논문들에서 GPT-4로 평가를 진행하고, 평가를 위한 데이터를 만들어내고, GPT-4로부터 나온 결과로 모델을 학습하고.. 정말 흔한 방법이 된 것 같습니다.
- 개인적 감상
솔직히 논문 저자 스스로 아쉬운 점을 기재해놓긴 했지만, 그래도 엄청 잘 검증된 것이 아닐까 싶습니다.
이 논문을 작성하며 진행한 실험들이 모든 벤치마크에 대한 결과는 아니라는 점을 언급했는데, 사실 그건 대부분이 그렇기 때문에.. 그렇게 큰 문제라고 지적하기는 어려운 것 같습니다.
대신 특정 태스크에 대해서 GPT-4에 준하는 모델을 이렇게 작은(상대적으로 ㅎㅎ..) 모델을 효율적으로 tuning하여 만들어 낼 수 있다는 것이 아주 놀랍습니다.
개인적으로는 매끄러운 대화 형식이 가능한 모델들의 능력도 일종의 emergent한 것으로 느껴지던데, 앞으로 모델들이 더 경량화되거나 더 훌륭한 quantization 기법 등이 연구된다면 정말 많은 사람들이 다양한 시도를 해볼 수 있지 않을까 싶습니다.
더욱 칭찬하고 싶은 것은 모든 것들을 오픈 소스로 공개했다는 점입니다.
거대 기업들이 만들어 놓은 것들에는 접근하기가 힘들었었는데, 이제는 AI 민주화(표현이 재밌는 것 같아요)가 시작되나..? 싶은 생각입니다 😂
출처 : https://arxiv.org/abs/2305.14314
QLoRA: Efficient Finetuning of Quantized LLMs
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quan
arxiv.org
'Paper Review' 카테고리의 다른 글
| <GAN> Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (0) | 2023.05.29 |
|---|---|
| <Benchmark> [GSM8K] Training Verifiers to Solve Math Word Problems (0) | 2023.05.28 |
| <Alignment> LIMA: Less Is More for Alignment (0) | 2023.05.24 |
| <Multi-modal> IMAGEBIND: One Embedding Space to Bind Them All (0) | 2023.05.23 |
| <LLM> AutoML-GPT: Automatic Machine Learning with GPT (0) | 2023.05.21 |
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
워싱턴 대학에서 제출한, PEFT(Parameter Efficient Fine Tuning) 기법 중 하나를 다룬 논문. 65B개 파라미터를 갖는 모델을 48GB GPU 한 장으로 finetuning할 수 있도록 만들었다.
- 배경
최근 언어 모델 관련 분야에서는 가장 주목을 받는 기술이 모델 경량화인 것 같습니다.
모델 자체를 light하게 만드는 것보다는 사전 학습된 모델을 최대한 적은 자원으로 fine tuning할 수 있도록 만드는 기술들에 관련된 것이죠.
특히 메타에서 만든 LLaMA의 등장 이후로 정말 많은 개인(물론 이것도 자원을 아예 필요로 하지 않는 것은 아니지만..)들이 LLM을 각자 fine tuning하고 원하는대로 조정하는 일들이 많이 일어났습니다.
이때 가장 많이 활용된 PEFT 기법중 하나가 LoRA입니다.
본 논문에서는 LoRA에서 한 발 더 나아간 QLoRA를 제시하는데, 기존에 비해 훨씬 효율적인 결과가 나타났음을 보고했습니다.
논문에 제시된 수치들로만 판단해보자면 7B짜리 모델은 쉽게 튜닝이 가능할 것 같고, 그것보다 사이즈가 큰 33B 혹은 65B 모델들은 클라우드 자원에 비용을 좀 들이면 튜닝이 가능한 수준인 것 같습니다.
(돈은 꽤나 들겠지만 개인이 singe GPU로 LLM을 학습시킨다는 것 자체가 대박입니다..!)
- 특징 및 성능
기존의 모델 성능을 하락시키지 않으면서도 효율적으로 튜닝을 하기 위해 적용된 방법론은 크게 세 가지입니다.
- 4-bit NormalFloat
기존에는 4-bit Integers / 4-big Floats 등의 자료형을 사용했는데, 이보다 quantization에 적합한 자료형임이 확인되었습니다. (참고로 데이터셋의 사이즈보다도 데이터의 품질-기존의 정보를 잘 유지할 수 있는지-이 더 중요하다고 합니다) - Double Quantization
quantization 상수를 quantize 하는 방법론입니다.
평균적으로 각 파라미터마다 0.37 bit를 아낄 수 있다고 합니다. - Paged Optimizers
gradient checkpointing memory spike를 방지하기 위해 NVIDIA의 통합 메모리를 사용합니다.
이는 길이가 긴 sequence를 mini-batch로 처리할 때 적합한 테크닉입니다.
보시다시피 QLoRA가 4비트 짜리 normal float를 사용하고 double quantization을 적용한 결과가 16비트 float 자료형을 사용한 것에 이르는 것을 알 수 있습니다.
재밌는 것은 이 논문에서도 결과에 대한 평가를 ‘사람 + GPT-4’로 했다고 합니다.
최근 정말 많은 논문들에서 GPT-4로 평가를 진행하고, 평가를 위한 데이터를 만들어내고, GPT-4로부터 나온 결과로 모델을 학습하고.. 정말 흔한 방법이 된 것 같습니다.
- 개인적 감상
솔직히 논문 저자 스스로 아쉬운 점을 기재해놓긴 했지만, 그래도 엄청 잘 검증된 것이 아닐까 싶습니다.
이 논문을 작성하며 진행한 실험들이 모든 벤치마크에 대한 결과는 아니라는 점을 언급했는데, 사실 그건 대부분이 그렇기 때문에.. 그렇게 큰 문제라고 지적하기는 어려운 것 같습니다.
대신 특정 태스크에 대해서 GPT-4에 준하는 모델을 이렇게 작은(상대적으로 ㅎㅎ..) 모델을 효율적으로 tuning하여 만들어 낼 수 있다는 것이 아주 놀랍습니다.
개인적으로는 매끄러운 대화 형식이 가능한 모델들의 능력도 일종의 emergent한 것으로 느껴지던데, 앞으로 모델들이 더 경량화되거나 더 훌륭한 quantization 기법 등이 연구된다면 정말 많은 사람들이 다양한 시도를 해볼 수 있지 않을까 싶습니다.
더욱 칭찬하고 싶은 것은 모든 것들을 오픈 소스로 공개했다는 점입니다.
거대 기업들이 만들어 놓은 것들에는 접근하기가 힘들었었는데, 이제는 AI 민주화(표현이 재밌는 것 같아요)가 시작되나..? 싶은 생각입니다 😂
출처 : https://arxiv.org/abs/2305.14314
QLoRA: Efficient Finetuning of Quantized LLMs
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quan
arxiv.org
'Paper Review' 카테고리의 다른 글
| <GAN> Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (0) | 2023.05.29 |
|---|---|
| <Benchmark> [GSM8K] Training Verifiers to Solve Math Word Problems (0) | 2023.05.28 |
| <Alignment> LIMA: Less Is More for Alignment (0) | 2023.05.24 |
| <Multi-modal> IMAGEBIND: One Embedding Space to Bind Them All (0) | 2023.05.23 |
| <LLM> AutoML-GPT: Automatic Machine Learning with GPT (0) | 2023.05.21 |