
오래전(2019.04)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
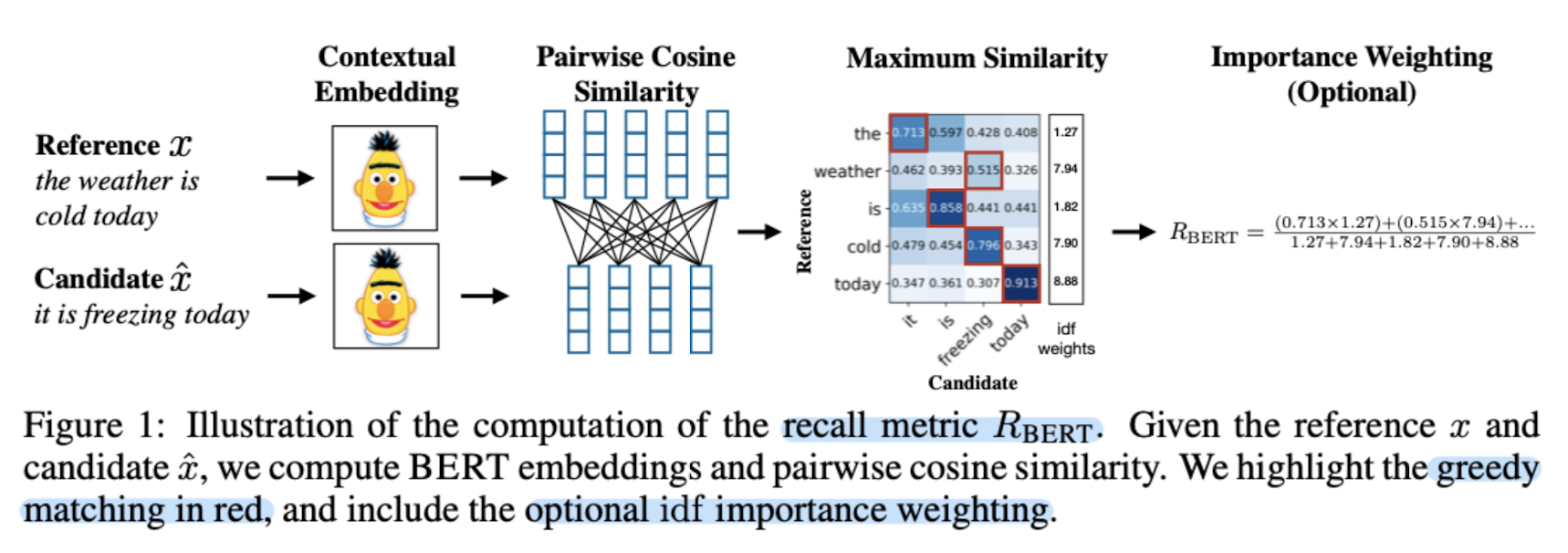
[Cornell Univ.] contextual embedding을 이용하여 토큰 간 유사도를 계산하여 문장 생성을 평가하는 metric으로 BERT를 사용.
- 배경
기존에 언어 생성을 평가하는 지표는 이미 여러가지가 존재했지만 표면적인 유사도를 측정하는 수준에 그치는 것이 많았다고 합니다.
대표적인 metric으로 n-gram 기반의 것들을 생각해보면, 단순히 글자 생김새가 다르다는 이유로 낮은 유사도 스코어를 갖게 될 것임을 알 수 있습니다.
하지만 실제로는 동일하게 생긴 단어가 아니라고 하더라도 유사한 의미를 지닐 수가 있죠(즉 임베딩 공간 내에서 유사한 포인트에 위치하고 있을 수 있죠)
따라서 본 논문에서는 만능 NLP 모델 BERT를 이용하여 두 문장 간 유사도를 뽑아내고 이를 metric으로 사용하는데, 이것이 다른 metric들에 비해 사람들의 판단에 훨씬 더 잘 부합한다는 결론을 냈습니다.
- 기존 legacy
- n-GRAM Matching Approaches : BLEU, METEOR, NIST 등
- Edit-Distance-Based Metrics : Levenshtein, TER 등
- Embedding-Based Metrics : Word embedding, MEANT 등
- Learned Metrics : BEER, BELND 등
- BERT SCORE
- Recall, Precision, F1 중에서 F1이 최고.
- IDF(Inverse Document Frequency)로 부여하는 가중치는 옵션
- Baseline Rescaling : lower bound b를 구하여 더 넓은 범위의 값을 가질 수 있도록 함(-1~1 값을 제대로 가질 수 있도록, 학습된 contextual embedding에 따르면 제한된 스코어 범위를 가졌기 때문)
- Machine Translation, Image Captioning 태스크로 실험
- 다른 metric에 비해 훨씬 강건하다는 특징 : 난이도 높은 adversarial example로 실험
- 개인적 감상
이전에 문장 유사도 태스크를 직접 해보면서 난이도가 꽤 높지도 않은, 진입 장벽이 낮은 태스크라고 느낀 적 있었습니다.
그래서 사실 이 문장 유사도라는 것이 개인적으로 텍스트를 생성하는 분야에서 metric으로 딱인데, 라는 생각을 하고 있는 찰나에 주변 친구에게 이 논문을 추천받았습니다.
사실 제가 그런 고민을 하고 있는지 모르는 상태에서 추천을 해준 것인데, 타이밍이 정말 좋았던 것 같습니다.
생각해보면 생성 분야는 모델의 성능을 평가하기 난해한 부분이 있습니다.
굉장히 주관적인 판단이 요구되기 때문이죠.
예를 들어 제가 지금 사용하고 있는 컴퓨터의 경우 애플의 맥북입니다.
이걸 컴퓨터라고 하는 것과, 노트북으로 하는 것과, 맥북이라고 하는 것 사이에 어떤 차이가 있을까요?
만약 맥북이 label(target)이라고 한다면, 노트북이라고 생성한 결과에 대해서는 몇 점을, 그리고 컴퓨터라고 예측한 결과에 대해서는 몇 점을 부여해야 할까요?
이런 판단이 굉장히 주관적이고 정량적으로 평가하기 힘든 요소이기 때문에, 다양한 데이터로 학습하여 임베딩 공간을 이미 구축하고 있는 언어 모델로 scoring하겠다는 것은 아주 훌륭한 판단이라고 생각합니다.
또한 논문에서 밝힌 바와 같이, 다른 평가지표들에 비하면 추론에 소요되는 시간이 많긴 하지만, 실질적으로 다른 것들에 비해 요구되는 연산량을 고려해 봤을 땐 엄청나게 효율적인 것이라고 합니다.
추론해야 하는 데이터의 개수에 큰 영향을 받겠지만, 논문이 쓰였던 당시에 비해 더 좋은 자원들이 흔한 지금에 이르러서는 이러한 평가 metric을 더욱 편하게 활용할 수 있지 않을까 싶습니다.
출처 : https://arxiv.org/abs/1904.09675
BERTScore: Evaluating Text Generation with BERT
We propose BERTScore, an automatic evaluation metric for text generation. Analogously to common metrics, BERTScore computes a similarity score for each token in the candidate sentence with each token in the reference sentence. However, instead of exact mat
arxiv.org
'Paper Review' 카테고리의 다른 글
오래전(2019.04)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Cornell Univ.] contextual embedding을 이용하여 토큰 간 유사도를 계산하여 문장 생성을 평가하는 metric으로 BERT를 사용.
- 배경
기존에 언어 생성을 평가하는 지표는 이미 여러가지가 존재했지만 표면적인 유사도를 측정하는 수준에 그치는 것이 많았다고 합니다.
대표적인 metric으로 n-gram 기반의 것들을 생각해보면, 단순히 글자 생김새가 다르다는 이유로 낮은 유사도 스코어를 갖게 될 것임을 알 수 있습니다.
하지만 실제로는 동일하게 생긴 단어가 아니라고 하더라도 유사한 의미를 지닐 수가 있죠(즉 임베딩 공간 내에서 유사한 포인트에 위치하고 있을 수 있죠)
따라서 본 논문에서는 만능 NLP 모델 BERT를 이용하여 두 문장 간 유사도를 뽑아내고 이를 metric으로 사용하는데, 이것이 다른 metric들에 비해 사람들의 판단에 훨씬 더 잘 부합한다는 결론을 냈습니다.
- 기존 legacy
- n-GRAM Matching Approaches : BLEU, METEOR, NIST 등
- Edit-Distance-Based Metrics : Levenshtein, TER 등
- Embedding-Based Metrics : Word embedding, MEANT 등
- Learned Metrics : BEER, BELND 등
- BERT SCORE
- Recall, Precision, F1 중에서 F1이 최고.
- IDF(Inverse Document Frequency)로 부여하는 가중치는 옵션
- Baseline Rescaling : lower bound b를 구하여 더 넓은 범위의 값을 가질 수 있도록 함(-1~1 값을 제대로 가질 수 있도록, 학습된 contextual embedding에 따르면 제한된 스코어 범위를 가졌기 때문)
- Machine Translation, Image Captioning 태스크로 실험
- 다른 metric에 비해 훨씬 강건하다는 특징 : 난이도 높은 adversarial example로 실험
- 개인적 감상
이전에 문장 유사도 태스크를 직접 해보면서 난이도가 꽤 높지도 않은, 진입 장벽이 낮은 태스크라고 느낀 적 있었습니다.
그래서 사실 이 문장 유사도라는 것이 개인적으로 텍스트를 생성하는 분야에서 metric으로 딱인데, 라는 생각을 하고 있는 찰나에 주변 친구에게 이 논문을 추천받았습니다.
사실 제가 그런 고민을 하고 있는지 모르는 상태에서 추천을 해준 것인데, 타이밍이 정말 좋았던 것 같습니다.
생각해보면 생성 분야는 모델의 성능을 평가하기 난해한 부분이 있습니다.
굉장히 주관적인 판단이 요구되기 때문이죠.
예를 들어 제가 지금 사용하고 있는 컴퓨터의 경우 애플의 맥북입니다.
이걸 컴퓨터라고 하는 것과, 노트북으로 하는 것과, 맥북이라고 하는 것 사이에 어떤 차이가 있을까요?
만약 맥북이 label(target)이라고 한다면, 노트북이라고 생성한 결과에 대해서는 몇 점을, 그리고 컴퓨터라고 예측한 결과에 대해서는 몇 점을 부여해야 할까요?
이런 판단이 굉장히 주관적이고 정량적으로 평가하기 힘든 요소이기 때문에, 다양한 데이터로 학습하여 임베딩 공간을 이미 구축하고 있는 언어 모델로 scoring하겠다는 것은 아주 훌륭한 판단이라고 생각합니다.
또한 논문에서 밝힌 바와 같이, 다른 평가지표들에 비하면 추론에 소요되는 시간이 많긴 하지만, 실질적으로 다른 것들에 비해 요구되는 연산량을 고려해 봤을 땐 엄청나게 효율적인 것이라고 합니다.
추론해야 하는 데이터의 개수에 큰 영향을 받겠지만, 논문이 쓰였던 당시에 비해 더 좋은 자원들이 흔한 지금에 이르러서는 이러한 평가 metric을 더욱 편하게 활용할 수 있지 않을까 싶습니다.
출처 : https://arxiv.org/abs/1904.09675
BERTScore: Evaluating Text Generation with BERT
We propose BERTScore, an automatic evaluation metric for text generation. Analogously to common metrics, BERTScore computes a similarity score for each token in the candidate sentence with each token in the reference sentence. However, instead of exact mat
arxiv.org