
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Research] LM이 코드를 생성하여 풀이하는 방식으로 VQA 태스크를 처리

기존에도 어떤 이미지, 그리고 이와 관련된 Question Answering 태스크는 꾸준히 발전하고 있었습니다.
하지만 여러 이미지에 대해 annotation을 수행하여 이미지-텍스트 pair를 만드는 것은 분명히 많은 자원을 필요로 하는 일입니다.
본 논문에서는 굉장히 재밌게도, 이 태스크를 LM을 통해 해결합니다.
LM이 주어진 문제를 (필요하다면) 여러 작은 문제로 쪼개고, 각 문제를 처리하기 위한 코드를 작성하여 이를 실행시킨 뒤 결과를 취합하는 방식입니다.
위 이미지를 보면 Few-Shot Prompting 베이스의 코드가 생성되고, 이를 실행시킬 땐 다른 모델을 사용하며, 그 실행 결과를 취합하여 최종적으로 ‘No’라는 답변이 도출된 것을 알 수 있습니다.
이러한 방식은 모델을 추가적으로 학습할 필요도 없고 이미 학습된 모델들을 기능적으로 묶어주는 것 뿐이라서 굉장히 편리하다고 볼 수 있습니다.
본 논문은 GQA, COVR, NLVR2 등의 다양한 VQA 데이터셋으로 실험한 결과를 담고 있습니다.
당연한 말이겠지만 CodeVQA 방식이 기존의 다른 베이스라인보다 우수한 성능을 보여줍니다.
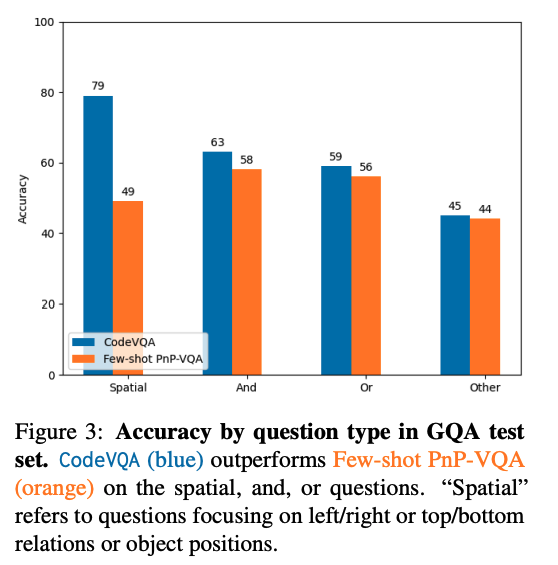
하지만 그래프에서 볼 수 있는 것처럼 실제로 실험한 데이터셋의 질문 난이도가 높지는 않을 것입니다.
Spatial question은 단순히 두 사물의 좌우/상하 관계에 대한 질문이고, and/or 등도 yes/no로 답변할 수 있는 간단한 형태의 질문들을 많이 포함하기 때문입니다.
위 이미지와 question은 spatial question의 대표적인 예시입니다.
모델이 이미지에서 정보를 추출하는 과정에 비하면 굉장히 쉬운 편에 속하는 질문이라고 볼 수 있겠습니다.
한편 에러를 분석한 결과에 따르면 CodeVQA 모델이 코드를 잘못 작성해준 것보다 코드를 실행하는 과정에서 불러온 모델의 정확도가 낮아 발생한 오류가 많다고는 합니다.
어쨌든 이런 식으로 LM을 중심으로 여러 모델을 혼합하여(API를 활용하기도 하지만) 태스크를 처리하는 방식들에 대해서는 항상 자원상의 한계가 가장 큰 부담으로 다가올 것 같다는 생각입니다.
출처 : https://arxiv.org/abs/2306.05392
Modular Visual Question Answering via Code Generation
We present a framework that formulates visual question answering as modular code generation. In contrast to prior work on modular approaches to VQA, our approach requires no additional training and relies on pre-trained language models (LMs), visual models
arxiv.org
'Paper Review' 카테고리의 다른 글
최근에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Research] LM이 코드를 생성하여 풀이하는 방식으로 VQA 태스크를 처리
기존에도 어떤 이미지, 그리고 이와 관련된 Question Answering 태스크는 꾸준히 발전하고 있었습니다.
하지만 여러 이미지에 대해 annotation을 수행하여 이미지-텍스트 pair를 만드는 것은 분명히 많은 자원을 필요로 하는 일입니다.
본 논문에서는 굉장히 재밌게도, 이 태스크를 LM을 통해 해결합니다.
LM이 주어진 문제를 (필요하다면) 여러 작은 문제로 쪼개고, 각 문제를 처리하기 위한 코드를 작성하여 이를 실행시킨 뒤 결과를 취합하는 방식입니다.
위 이미지를 보면 Few-Shot Prompting 베이스의 코드가 생성되고, 이를 실행시킬 땐 다른 모델을 사용하며, 그 실행 결과를 취합하여 최종적으로 ‘No’라는 답변이 도출된 것을 알 수 있습니다.
이러한 방식은 모델을 추가적으로 학습할 필요도 없고 이미 학습된 모델들을 기능적으로 묶어주는 것 뿐이라서 굉장히 편리하다고 볼 수 있습니다.
본 논문은 GQA, COVR, NLVR2 등의 다양한 VQA 데이터셋으로 실험한 결과를 담고 있습니다.
당연한 말이겠지만 CodeVQA 방식이 기존의 다른 베이스라인보다 우수한 성능을 보여줍니다.
하지만 그래프에서 볼 수 있는 것처럼 실제로 실험한 데이터셋의 질문 난이도가 높지는 않을 것입니다.
Spatial question은 단순히 두 사물의 좌우/상하 관계에 대한 질문이고, and/or 등도 yes/no로 답변할 수 있는 간단한 형태의 질문들을 많이 포함하기 때문입니다.
위 이미지와 question은 spatial question의 대표적인 예시입니다.
모델이 이미지에서 정보를 추출하는 과정에 비하면 굉장히 쉬운 편에 속하는 질문이라고 볼 수 있겠습니다.
한편 에러를 분석한 결과에 따르면 CodeVQA 모델이 코드를 잘못 작성해준 것보다 코드를 실행하는 과정에서 불러온 모델의 정확도가 낮아 발생한 오류가 많다고는 합니다.
어쨌든 이런 식으로 LM을 중심으로 여러 모델을 혼합하여(API를 활용하기도 하지만) 태스크를 처리하는 방식들에 대해서는 항상 자원상의 한계가 가장 큰 부담으로 다가올 것 같다는 생각입니다.
출처 : https://arxiv.org/abs/2306.05392
Modular Visual Question Answering via Code Generation
We present a framework that formulates visual question answering as modular code generation. In contrast to prior work on modular approaches to VQA, our approach requires no additional training and relies on pre-trained language models (LMs), visual models
arxiv.org