
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
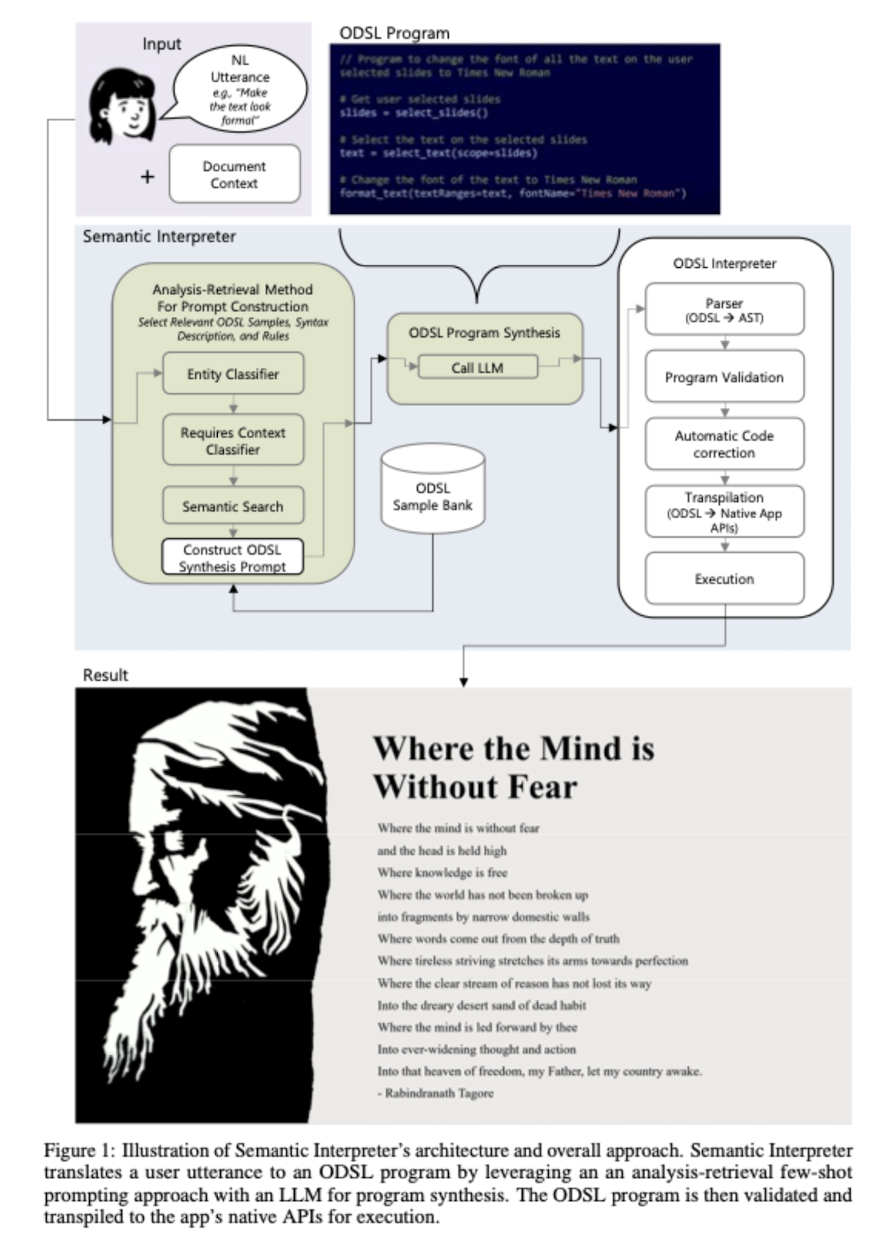
LLM으로 자연어를 이해해 Office Domain Specific Language(ODSL)으로 변환하여 office application(Power Point)을 쉽게 활용할 수 있도록 함.
이때 Semantic Interpreter는 Analysis-Retrieveal 프롬프트를 이용하여 자연어를 ODSL로 변환.
몇 달 전부터 사무용 어플리케이션에 LLM을 활용하는 서비스에 대한 언급이 이어지고 있었습니다.
copilot이라는 이름으로 AI 기술을 운용하는 Microsoft도 자체적인 서비스 내에 AI를 탑재하여 업무 편의성을 도모하겠다는 계획을 야심차게 발표한지도 몇 달이 지났죠.
(도대체 언제쯤 상용화할지 모르겠습니다. 이럴거면 데모는 왜 보여주고 광고는 왜 한건지..)
본 논문은 자연어를 OSDL로 변환하여 office 어플리케이션을 적절히 활용하는 것에 대한 연구입니다.
Microsoft가 보유한 여러 업무 툴 중에서도 power point에 대한 내용입니다.
사실 이전에 홍보한 내용에 비하면 초라한 결과가 아닌가 싶은 생각이 들었습니다.
흥미로운 것은 접근 방식인데, 기존의 LLM들이 명확한 한계를 보였던 입력 토큰 길이 제한을 극복하기 위해서 새로운 언어 체계를 적용하고자 했다는 것입니다.
이전에도 입력의 길이 제한을 극복하여 길이가 꽤 긴 문서 등을 모델의 입력으로 제공하고자 하는 시도도 많았는데, 이를 특정 도메인에 한정한 언어로 변환하는 방식은 굉장히 참신하다는 생각이 들었습니다.
어쩌면 일부 프로그래밍 언어에 적합한 데이터를 기반으로 학습한 코드 생성 모델도 갈래가 비슷하지 않나 싶은 생각도 들고요.
본 논문에서 사용된 여러 개념 중 entity라는 개념이 주목할 만합니다. (ex. 슬라이드 → 제목, 부제목 내용 등 쪼개는 단위)
사실 사용자가 LLM에게 요구하는 내용은 굉장히 추상적일 수도 있고(ex. ppt 이쁘게 해줘) 이에 대한 해결책도 여러 가지일 수 있습니다.(폰트 변경, 색상 변경 등)
이 분야는 아직 태동기라도 보는 것이 적합할텐데, 이러한 상황에서는 현재 프로그램이 처리 가능한 간단한 수준의 태스크로 모델 성능을 파악하도록 했습니다.
또한 자가 code correction 등을 적용하는 등 모델의 출력물을 고도화하는 여러 기법들이 적용되었습니다.
개인적으로는, 최근에 또 구글이 spread sheet에 AI를 적용한 기술을 실험실에 공개했는데, 이런 문서툴에서 얼마나 좋은 효율을 보여줄지 너무 기대가 됩니다.
출처 : https://arxiv.org/abs/2306.03460
Natural Language Commanding via Program Synthesis
We present Semantic Interpreter, a natural language-friendly AI system for productivity software such as Microsoft Office that leverages large language models (LLMs) to execute user intent across application features. While LLMs are excellent at understand
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
LLM으로 자연어를 이해해 Office Domain Specific Language(ODSL)으로 변환하여 office application(Power Point)을 쉽게 활용할 수 있도록 함.
이때 Semantic Interpreter는 Analysis-Retrieveal 프롬프트를 이용하여 자연어를 ODSL로 변환.
몇 달 전부터 사무용 어플리케이션에 LLM을 활용하는 서비스에 대한 언급이 이어지고 있었습니다.
copilot이라는 이름으로 AI 기술을 운용하는 Microsoft도 자체적인 서비스 내에 AI를 탑재하여 업무 편의성을 도모하겠다는 계획을 야심차게 발표한지도 몇 달이 지났죠.
(도대체 언제쯤 상용화할지 모르겠습니다. 이럴거면 데모는 왜 보여주고 광고는 왜 한건지..)
본 논문은 자연어를 OSDL로 변환하여 office 어플리케이션을 적절히 활용하는 것에 대한 연구입니다.
Microsoft가 보유한 여러 업무 툴 중에서도 power point에 대한 내용입니다.
사실 이전에 홍보한 내용에 비하면 초라한 결과가 아닌가 싶은 생각이 들었습니다.
흥미로운 것은 접근 방식인데, 기존의 LLM들이 명확한 한계를 보였던 입력 토큰 길이 제한을 극복하기 위해서 새로운 언어 체계를 적용하고자 했다는 것입니다.
이전에도 입력의 길이 제한을 극복하여 길이가 꽤 긴 문서 등을 모델의 입력으로 제공하고자 하는 시도도 많았는데, 이를 특정 도메인에 한정한 언어로 변환하는 방식은 굉장히 참신하다는 생각이 들었습니다.
어쩌면 일부 프로그래밍 언어에 적합한 데이터를 기반으로 학습한 코드 생성 모델도 갈래가 비슷하지 않나 싶은 생각도 들고요.
본 논문에서 사용된 여러 개념 중 entity라는 개념이 주목할 만합니다. (ex. 슬라이드 → 제목, 부제목 내용 등 쪼개는 단위)
사실 사용자가 LLM에게 요구하는 내용은 굉장히 추상적일 수도 있고(ex. ppt 이쁘게 해줘) 이에 대한 해결책도 여러 가지일 수 있습니다.(폰트 변경, 색상 변경 등)
이 분야는 아직 태동기라도 보는 것이 적합할텐데, 이러한 상황에서는 현재 프로그램이 처리 가능한 간단한 수준의 태스크로 모델 성능을 파악하도록 했습니다.
또한 자가 code correction 등을 적용하는 등 모델의 출력물을 고도화하는 여러 기법들이 적용되었습니다.
개인적으로는, 최근에 또 구글이 spread sheet에 AI를 적용한 기술을 실험실에 공개했는데, 이런 문서툴에서 얼마나 좋은 효율을 보여줄지 너무 기대가 됩니다.
출처 : https://arxiv.org/abs/2306.03460
Natural Language Commanding via Program Synthesis
We present Semantic Interpreter, a natural language-friendly AI system for productivity software such as Microsoft Office that leverages large language models (LLMs) to execute user intent across application features. While LLMs are excellent at understand
arxiv.org