
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
textbook 수준의 우수한 품질의 데이터로 fine-tuning한 모델 phi-1.
데이터의 양보다도 질이 중요하다는 것을 코드 생성 분야에서 입증한 케이스.
- 배경
사실 여러 거대 인공지능 모델들이 성장함에 따라 이를 활용하거나, 경량화하거나 하는 등의 다양한 연구가 이뤄지고 있지만, 한편으로는 데이터셋에 대한 연구도 활발히 진행중입니다.
물론 데이터셋의 품질을 가르는 기준이 굉장히 주관적으로 느껴질 수 있습니다만,
LIMA와 같은 모델에서 입증한 것처럼 잘 curated된 데이터셋은 그 작고 귀여운 양에 비해 모델 성능을 폭발적으로 향상시켜줄 수 있습니다.
특히나 생성 모델이 각광받고, 사람들의 니즈에 맞는 모델을 만들기 위한 다양한 연구가 이뤄지고 있는 현시점에서는 이와 같은 연구들이 참 흥미롭게 느껴집니다.
본 논문은 파이썬 코드를 다양하게 학습한 모델(phi-1)에 대해 소개하고 있습니다.
결론적으로 말하자면 아주 적은 양의 데이터로 fine-tuning한 모델이 기존의 모델들의 성능을 압도하는 결과를 보여줬습니다.
- 컨셉 및 성능
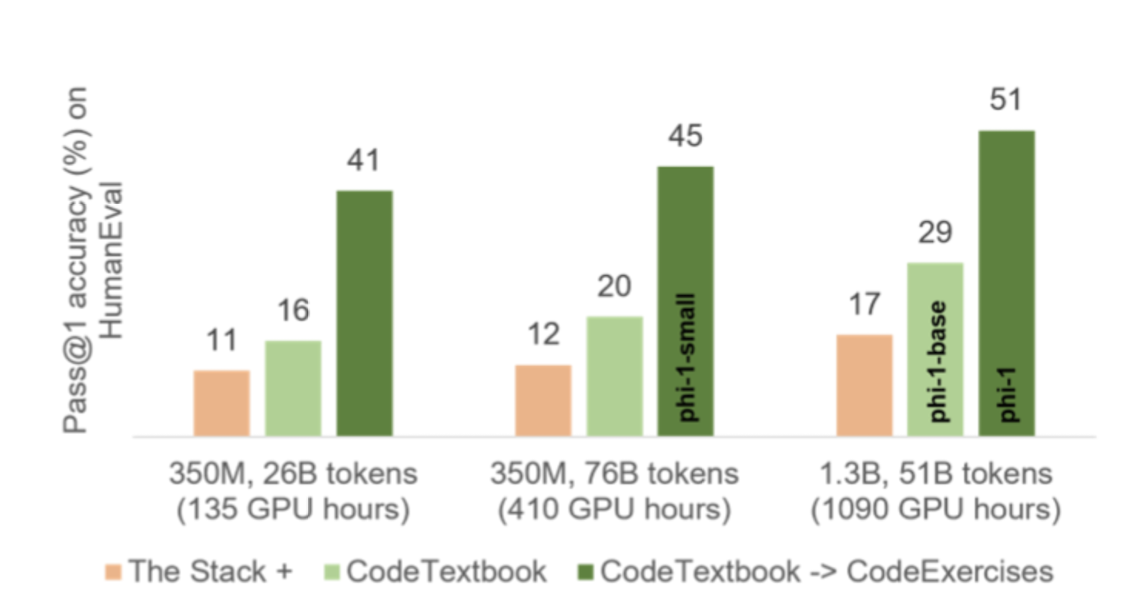
데이터셋은 크게 세 가지로 구분할 수 있습니다.
- The Stack : StackOverflow로부터 얻은 기존의 데이터셋
- CodeTextbook : GPT-3.5 생성 데이터, 사전학습용
- CodeExercise : GPT-3.5 생성 데이터, fine-tuning용
데이터를 생성할 때는 GPT-3.5를 사용했고, 생성된 결과물들이 어떤지에 대한 성능 평가를 할 때는 GPT-4를 사용했습니다.
데이터셋은 추론 능력과 기본적인 알고리즘적 스킬을 필요로 하는 주제들을 주로 다루고 있습니다.
또한 다양성을 보장하기 위한 기법(randomness)도 적용되었다고 합니다.

phi-1은 fine-tuning한 모델, phi-1-base, small은 사전학습만 적용된 모델입니다.
여러 실험들을 통해서 phi-1이 다양한 요구에 대해 좋은 성능을 강건하게 보였음이 확인되었습니다.
특히 import한 라이브러리 등에 대해서도 연구한 결과가 있는데, 학습 당시에 접하지 못했던 것들에 대해서도 잘 처리하는 경향을 보였다고 합니다.
즉, 단순히 어떤 패턴이나 상황 및 조건을 보고 암기를 한 것이 아니라, 코드 작성에 필요한 일종의 로직을 제대로 습득한 것 같은 경향이 나타났다는 뜻입니다.
- 개인적 감상
위에서 언급한 LIMA와 같이 최소한의 데이터를 활용하여(물론 이를 curate하는 것이 보통 일이 아니겠지만요..) 거대 언어 모델을 최적의 상태로 학습하는 것은 굉장히 파격적인 접근법이라고 생각합니다.
요즘 LLM들 중에 아주 작은 축에 속하는 6~7B짜리 모델도 큰 돈이 없는 개인, 학생 등에게는 엄청난 부담이기 때문이죠.
이미 생성 모델의 성능 향상에 가장 큰 영향을 준 것이 human feedback(RLHF..)라는 점을 생각해보면 모델 성능에 주관이 개입된지는 좀 지난 것 같습니다.
물론 본 논문의 경우 파이썬에 한정되어 있고, 다양한 스타일의 코드를 작성하지 못한다는 한계점이 있긴 하지만 앞으로 이와 같은 접근법들이 더욱 많이 활용될 것 같아 기대가 됩니다.
출처 : https://arxiv.org/abs//2306.11644
Textbooks Are All You Need
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the w
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research]
textbook 수준의 우수한 품질의 데이터로 fine-tuning한 모델 phi-1.
데이터의 양보다도 질이 중요하다는 것을 코드 생성 분야에서 입증한 케이스.
- 배경
사실 여러 거대 인공지능 모델들이 성장함에 따라 이를 활용하거나, 경량화하거나 하는 등의 다양한 연구가 이뤄지고 있지만, 한편으로는 데이터셋에 대한 연구도 활발히 진행중입니다.
물론 데이터셋의 품질을 가르는 기준이 굉장히 주관적으로 느껴질 수 있습니다만,
LIMA와 같은 모델에서 입증한 것처럼 잘 curated된 데이터셋은 그 작고 귀여운 양에 비해 모델 성능을 폭발적으로 향상시켜줄 수 있습니다.
특히나 생성 모델이 각광받고, 사람들의 니즈에 맞는 모델을 만들기 위한 다양한 연구가 이뤄지고 있는 현시점에서는 이와 같은 연구들이 참 흥미롭게 느껴집니다.
본 논문은 파이썬 코드를 다양하게 학습한 모델(phi-1)에 대해 소개하고 있습니다.
결론적으로 말하자면 아주 적은 양의 데이터로 fine-tuning한 모델이 기존의 모델들의 성능을 압도하는 결과를 보여줬습니다.
- 컨셉 및 성능
데이터셋은 크게 세 가지로 구분할 수 있습니다.
- The Stack : StackOverflow로부터 얻은 기존의 데이터셋
- CodeTextbook : GPT-3.5 생성 데이터, 사전학습용
- CodeExercise : GPT-3.5 생성 데이터, fine-tuning용
데이터를 생성할 때는 GPT-3.5를 사용했고, 생성된 결과물들이 어떤지에 대한 성능 평가를 할 때는 GPT-4를 사용했습니다.
데이터셋은 추론 능력과 기본적인 알고리즘적 스킬을 필요로 하는 주제들을 주로 다루고 있습니다.
또한 다양성을 보장하기 위한 기법(randomness)도 적용되었다고 합니다.
phi-1은 fine-tuning한 모델, phi-1-base, small은 사전학습만 적용된 모델입니다.
여러 실험들을 통해서 phi-1이 다양한 요구에 대해 좋은 성능을 강건하게 보였음이 확인되었습니다.
특히 import한 라이브러리 등에 대해서도 연구한 결과가 있는데, 학습 당시에 접하지 못했던 것들에 대해서도 잘 처리하는 경향을 보였다고 합니다.
즉, 단순히 어떤 패턴이나 상황 및 조건을 보고 암기를 한 것이 아니라, 코드 작성에 필요한 일종의 로직을 제대로 습득한 것 같은 경향이 나타났다는 뜻입니다.
- 개인적 감상
위에서 언급한 LIMA와 같이 최소한의 데이터를 활용하여(물론 이를 curate하는 것이 보통 일이 아니겠지만요..) 거대 언어 모델을 최적의 상태로 학습하는 것은 굉장히 파격적인 접근법이라고 생각합니다.
요즘 LLM들 중에 아주 작은 축에 속하는 6~7B짜리 모델도 큰 돈이 없는 개인, 학생 등에게는 엄청난 부담이기 때문이죠.
이미 생성 모델의 성능 향상에 가장 큰 영향을 준 것이 human feedback(RLHF..)라는 점을 생각해보면 모델 성능에 주관이 개입된지는 좀 지난 것 같습니다.
물론 본 논문의 경우 파이썬에 한정되어 있고, 다양한 스타일의 코드를 작성하지 못한다는 한계점이 있긴 하지만 앞으로 이와 같은 접근법들이 더욱 많이 활용될 것 같아 기대가 됩니다.
출처 : https://arxiv.org/abs//2306.11644
Textbooks Are All You Need
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the w
arxiv.org