
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
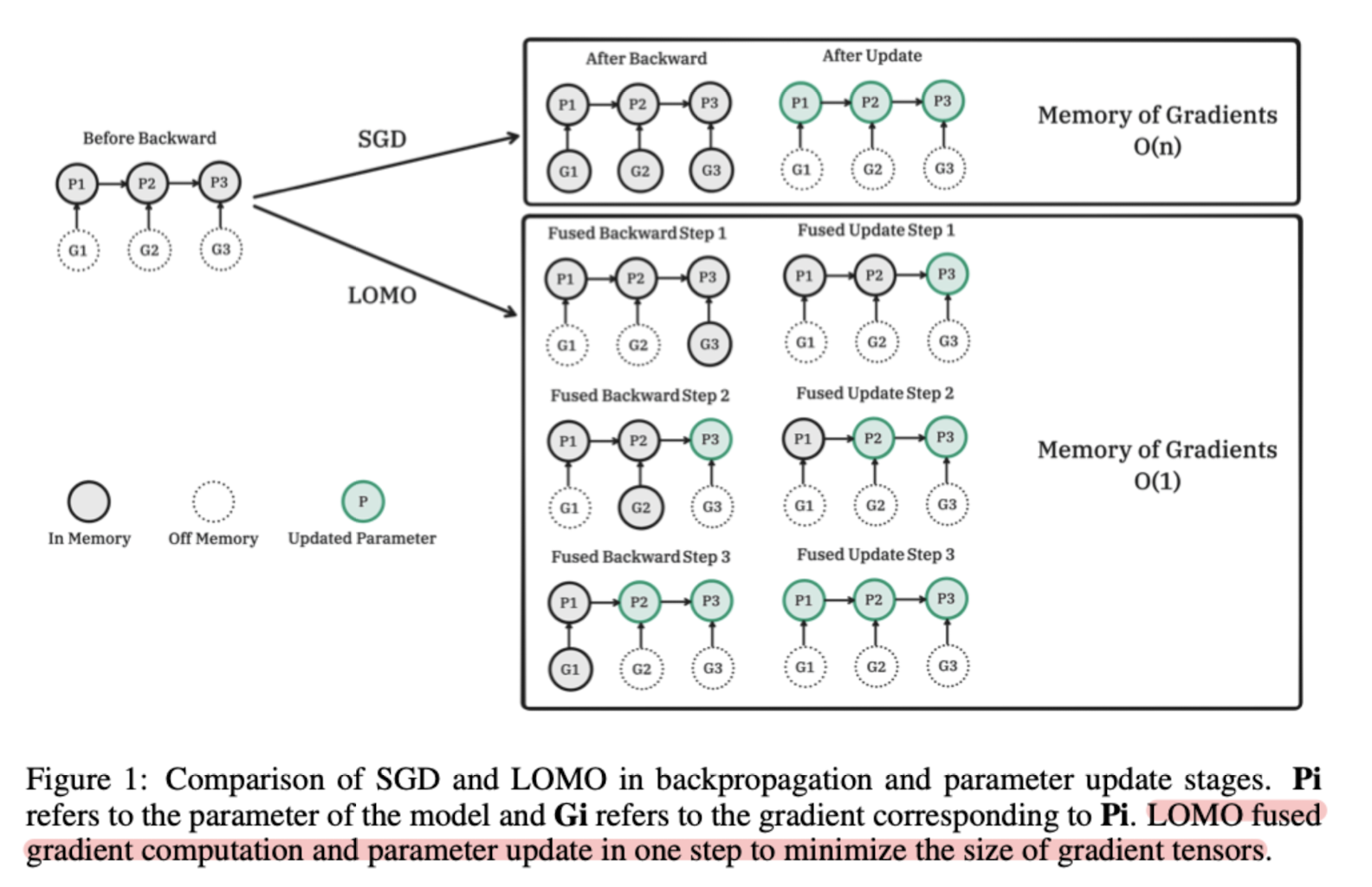
Low-Memory Optimization(LOMO) gradient 계산과 파라미터 업데이트를 한 번에 진행함으로써 ‘메모리 사용량’을 획기적으로 줄이는 기법을 제시. 65B 모델을 RTX 3090 24GB 8대로 fine-tuning.
- 배경
요즘 언어 모델 관련 논문을 읽으면 항상 비슷한 이야기로 시작할 수밖에 없는 것 같습니다.
말 그대로 거대 언어 모델은 어마무시한 자원을 필요로 하기 때문에, 개인이나 작은 연구 시설 혹은 조직들은 관련 연구를 진행할 엄두도 내지 못했습니다.
이에 따라서 모델의 사이즈를 줄이거나 연산량을 감소시키는 등의 다양한 연구가 이뤄지고 있고 본 논문도 그러한 흐름의 일부입니다.
본 논문은 무려 65B 사이즈의 모델을 고작 24G 메모리의 RTX 3090 8대로 fine-tuning 할 수 있었고, 그 성능도 기존의 다른 방식에 뒤처지지 않는다고 주장합니다.
- 컨셉
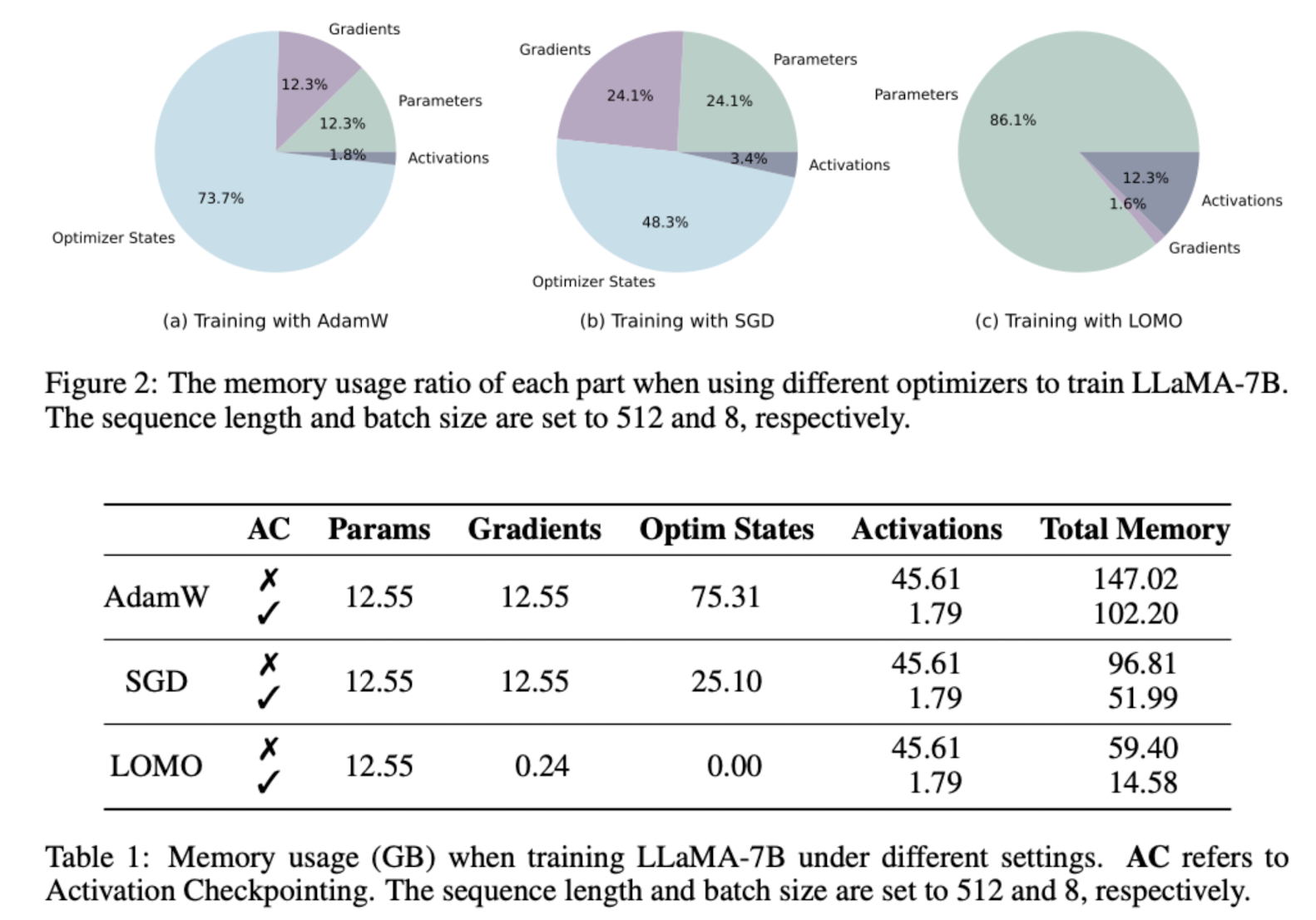
모델의 파라미터수가 늘어난다는 것은 곧 필요한 메모리의 크기가 커진다는 것을 의미합니다.
이때 메모리를 가장 많이 차지하는 요인중 하나는 back-propagation(역전파)에 필요한 파라미터값을 forward(순전파) 연산 과정중에 저장하는 것입니다.
이는 현대 딥러닝 모델의 학습 방식의 근간을 이루고 있기 때문에 어찌보면 굉장히 당연하게 여겨져 왔습니다.
그러나 최근에는 forward 연산 중에 파라미터를 바로 업데이트함으로써 전체 연산에 필요한 메모리의 양을 획기적으로 줄이는 것에 대한 연구가 좋은 성과를 보인 예가 있고, 본 논문도 마찬가지입니다.
여기서는 학습 단계에서 gradient normalization, loss scaling, transition certain computation을 full precision으로 통합하며 필요 메모리의 양을 많이 줄이면서도 좋은 성능을 유지할 수 있었다고 합니다.
가장 핵심적인 것 하나만 짚자면 optimizer를 Adam이 아니라 SGD(Stochastic Gradient Descent)를 사용했다는 점입니다.
사실 SGD도 딥러닝 역사에 한 획을 그은 기법이지만 요즘에는 optimizer로 Adam 계열을 쓰지 않는 것을 거의 본적이 없을 정도입니다.
그런데 기존의 SGD가 학습에 적합하지 않다고 지적된 한계점들이 모델의 사이즈가 커짐에 따라 오히려 커버될 수 있다고 본 논문에서는 주장하며 관련된 실험 결과를 제시했습니다.
물론 단순히 SGD만 사용한 것이 아니라 파라미터를 forward 과정에서 즉시 업데이트 하는 기법과 합친 것을 Low-Memory Optimization(LOMO)라고 부르는 것입니다.
- 개인적 감상
얼마 전에도 forward 과정에서 바로 파라미터를 업데이트를 하며 좋은 퍼포먼스를 보인 사례에 대한 논문을 본 적이 있는데 굉장히 유사하다는 생각이 들었습니다.
각각이 어떤 점이 다른지를 확인해 볼 필요가 있는 것 같네요.
다만 이러한 방식의 한계에 대해 지적한 바가 없다는 점이 조금 걸립니다.
본 논문에서는 SGD가 LLM에서 Adam의 자리를 차지하기에 충분하다고 했지만 그것이 과연 모든 태스크에 대해 적용될지는 미지수입니다.
반면 다른 경량화 기법(논문에서는 LoRA를 언급)들과 독립적인 실험 결과를 보이며, 다른 기법들과의 결합 가능성에 대해 언급했는데 이것이 가장 기대됩니다.
Full Parameter Fine-tuning for Large Language Models with Limited Resources
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but demand massive GPU resources for training. Lowering the threshold for LLMs training would encourage greater participation from researchers, benefiting both academia and
arxiv.org