
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Second-order Clipped Stochastic Optimization, Sophia. diagonal Hessian을 이용하여 Adam보다 2배 이상 빠른 optimizer.
현재 딥러닝 분야에서 가장 널리 쓰이는 optimizer는 Adam family입니다.
더 큰 사이즈의 모델들이 더 좋은 성능을 보인다는 scaling law에 따라 요구되는 연산량은 점점 증가하는 추세이고, 본 논문과 같은 연구는 이를 최소화하기 위한 노력의 일환으로 볼 수 있습니다.
오늘은 Sophia라는 optimizer의 특징을 간단히 정리해보고자 합니다.
(저도 수식적인 부분에 대한 이해가 한참 부족해서 관련 내용은 최소화했고, 논문에 적힌 내용을 온전히 이해하기 위해서는 optimizer와 관련된 깊은 이해가 뒷받침 되어야 할 것입니다)
- Exponential Moving Average을 이용해 파라미터를 업데이트
- 기존의 프레임워크나 모델 아키텍쳐를 변형하지 않고 그대로 활용 가능
- sharp dimension에 대해 더 강한 penalization을 적용하여 flat dimension과 유사한 수준의 파라미터 업데이트가 일어날 수 있도록 설계
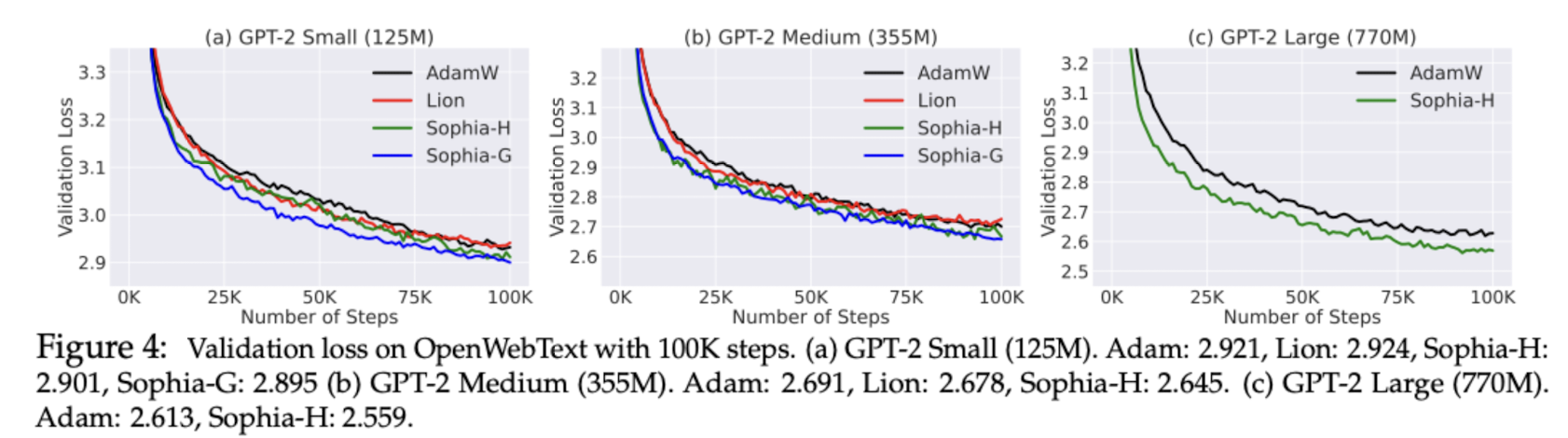
→ 기존의 Adam이나 GD는 두 차원의 특성이 다른 경우에 발생하는 이 문제를 극복하지 못했음 - AdamW, Lion과 성능을 비교해본 결과 일관적으로 validation loss가 낮게 나타남.
- 모델의 사이즈를 키울수록 그 gap은 커짐.
- step을 기준으로 비교한 결과 학습 속도가 약 두 배 가량 빠른 모습을 보여줬을 뿐만 아니라(유사한 비용, 더 적은 step으로 minimum에 도달), few-shot evaluation에서도 Sophia로 학습된 모델이 더 좋은 성능을 보였음
- 모델의 안정성(stability) 측면에서 Sophia-H가 다른 두 방식보다 안정적인 결과를 보였는데, 이는 기존의 gradient 정보가 심각하게 훼손되지 않는 선에서 성능을 유지할 수 있도록 하는 gradient clipping 기법과 관련이 깊음.
- 관련 연구
- Stochastic Adaptive First-order Optimizers in Deep Learning
- Second-order Optimizers in Deep Learning
- Gradient Clipping
- Optimization Algorithms in LM Pre-training
출처 : https://arxiv.org/abs/2305.14342
Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
Given the massive cost of language model pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophist
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
Second-order Clipped Stochastic Optimization, Sophia. diagonal Hessian을 이용하여 Adam보다 2배 이상 빠른 optimizer.
현재 딥러닝 분야에서 가장 널리 쓰이는 optimizer는 Adam family입니다.
더 큰 사이즈의 모델들이 더 좋은 성능을 보인다는 scaling law에 따라 요구되는 연산량은 점점 증가하는 추세이고, 본 논문과 같은 연구는 이를 최소화하기 위한 노력의 일환으로 볼 수 있습니다.
오늘은 Sophia라는 optimizer의 특징을 간단히 정리해보고자 합니다.
(저도 수식적인 부분에 대한 이해가 한참 부족해서 관련 내용은 최소화했고, 논문에 적힌 내용을 온전히 이해하기 위해서는 optimizer와 관련된 깊은 이해가 뒷받침 되어야 할 것입니다)
- Exponential Moving Average을 이용해 파라미터를 업데이트
- 기존의 프레임워크나 모델 아키텍쳐를 변형하지 않고 그대로 활용 가능
- sharp dimension에 대해 더 강한 penalization을 적용하여 flat dimension과 유사한 수준의 파라미터 업데이트가 일어날 수 있도록 설계
→ 기존의 Adam이나 GD는 두 차원의 특성이 다른 경우에 발생하는 이 문제를 극복하지 못했음 - AdamW, Lion과 성능을 비교해본 결과 일관적으로 validation loss가 낮게 나타남.
- 모델의 사이즈를 키울수록 그 gap은 커짐.
- step을 기준으로 비교한 결과 학습 속도가 약 두 배 가량 빠른 모습을 보여줬을 뿐만 아니라(유사한 비용, 더 적은 step으로 minimum에 도달), few-shot evaluation에서도 Sophia로 학습된 모델이 더 좋은 성능을 보였음
- 모델의 안정성(stability) 측면에서 Sophia-H가 다른 두 방식보다 안정적인 결과를 보였는데, 이는 기존의 gradient 정보가 심각하게 훼손되지 않는 선에서 성능을 유지할 수 있도록 하는 gradient clipping 기법과 관련이 깊음.
- 관련 연구
- Stochastic Adaptive First-order Optimizers in Deep Learning
- Second-order Optimizers in Deep Learning
- Gradient Clipping
- Optimization Algorithms in LM Pre-training
출처 : https://arxiv.org/abs/2305.14342
Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
Given the massive cost of language model pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophist
arxiv.org