
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
다양한 특성을 반영할 수 있는 프롬프트를 이용해 LLM으로 NLP task를 위한 데이터 생성하기
- 배경
LLM이 활용되는 여러 분야 중 하나는 데이터 생성(generator)입니다.
문장 단위의 텍스트를 생성하는 능력이 워낙 탁월하고 그 품질이 사실상 보장된 것이기 때문에 적은 비용으로 고품질 데이터를 생성할 수 있음이 알려졌습니다.
그러나 기존의 연구들은 단순히 class-conditional prompt에 의존하고 있을 뿐이라고 지적합니다.
이에 의해 생성되는 데이터의 다양성이 보장되지도 않고 텍스트를 생성하는 LLM의 편향을 그대로 상속하는 문제점이 있다고 지적합니다.
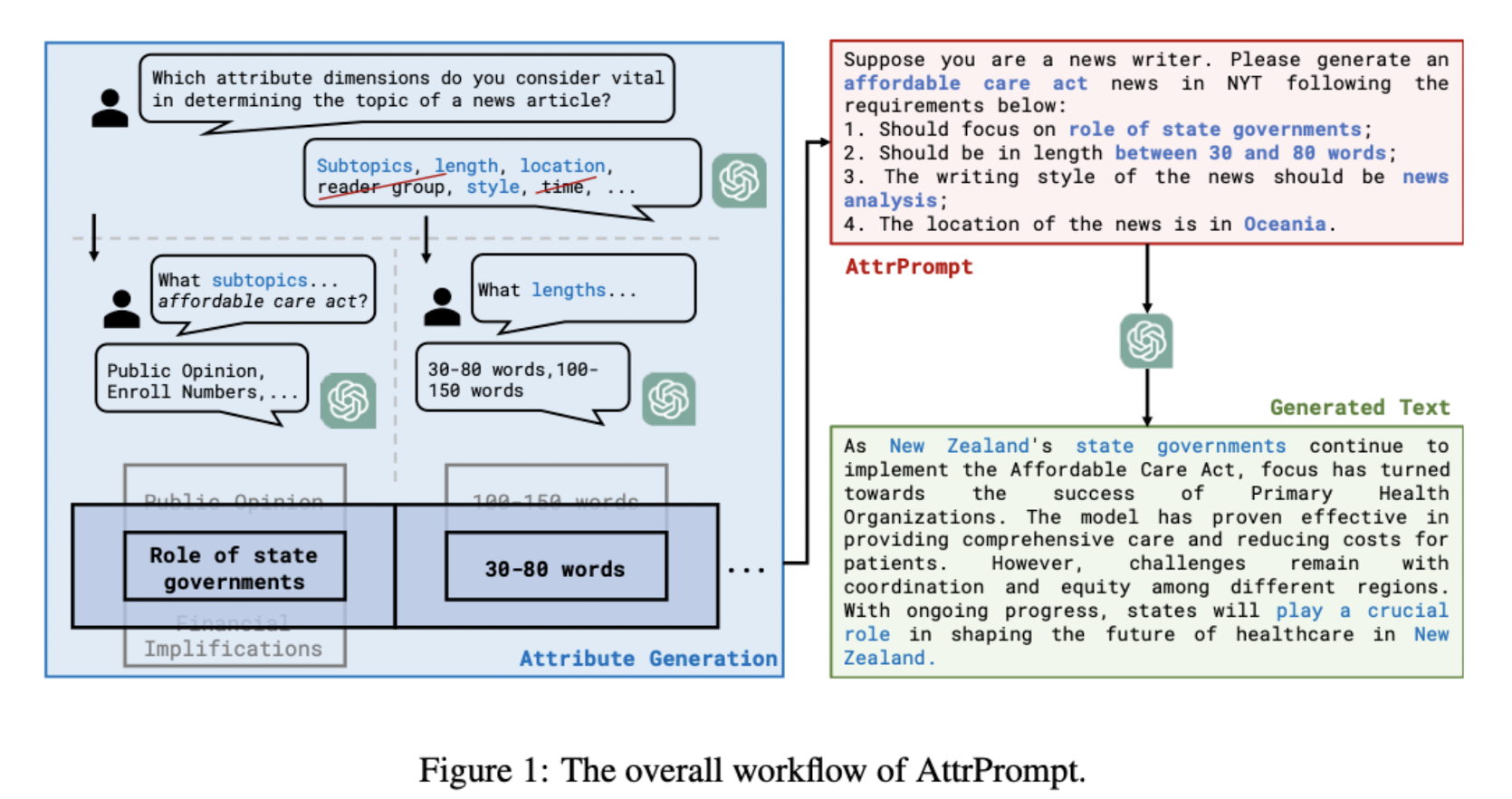
이러한 문제점을 해결하기 위해 ‘attribute’ 개념을 사용하며 이것이 다양한 텍스트 생성을 목표로 삼습니다.
이를 통해 LLM이 가질 수 있는 편향성을 큰 폭으로 줄이고, 모델을 fine-tuning 할 때도 더 좋은 퍼포먼스로 이어지는데 기여했다고 합니다.
- 특징
attribute라는 개념이 생소하게 느껴질 수 있지만 사실 들어보면 어려운 것은 아닙니다.
예를 들면 문장의 길이, 스타일 등이 있습니다.
attribute는 class-dependent vs class-independent한 것들로 나뉩니다.
방금 언급한 문장의 길이, 스타일 등은 클래스의 종류와 무관한 것들이지만, subtopic과 같은 attribute는 클래스에 따라 다른 의미를 지닐 수도 있습니다.
따라서 본 논문에서는 class-dependent value를 filtering함으로써 고품질의 데이터셋 생성에 힘을 보탰습니다.
데이터를 생성할 때는 configuration을 매번 random하게 설정함으로써 diversity를 보장하고자 했습니다.
재밌는 것은 LLM의 bias를 줄이기 위해 직접 annotation을 수행했다는 것입니다.
예를 들어 location과 같은 attribute가 North America에 지나치게 편향되어 있다는 문제점을 해결하기 위해, 모든 지역 분류에 대해 고른 분포의 데이터셋을 구성했습니다.
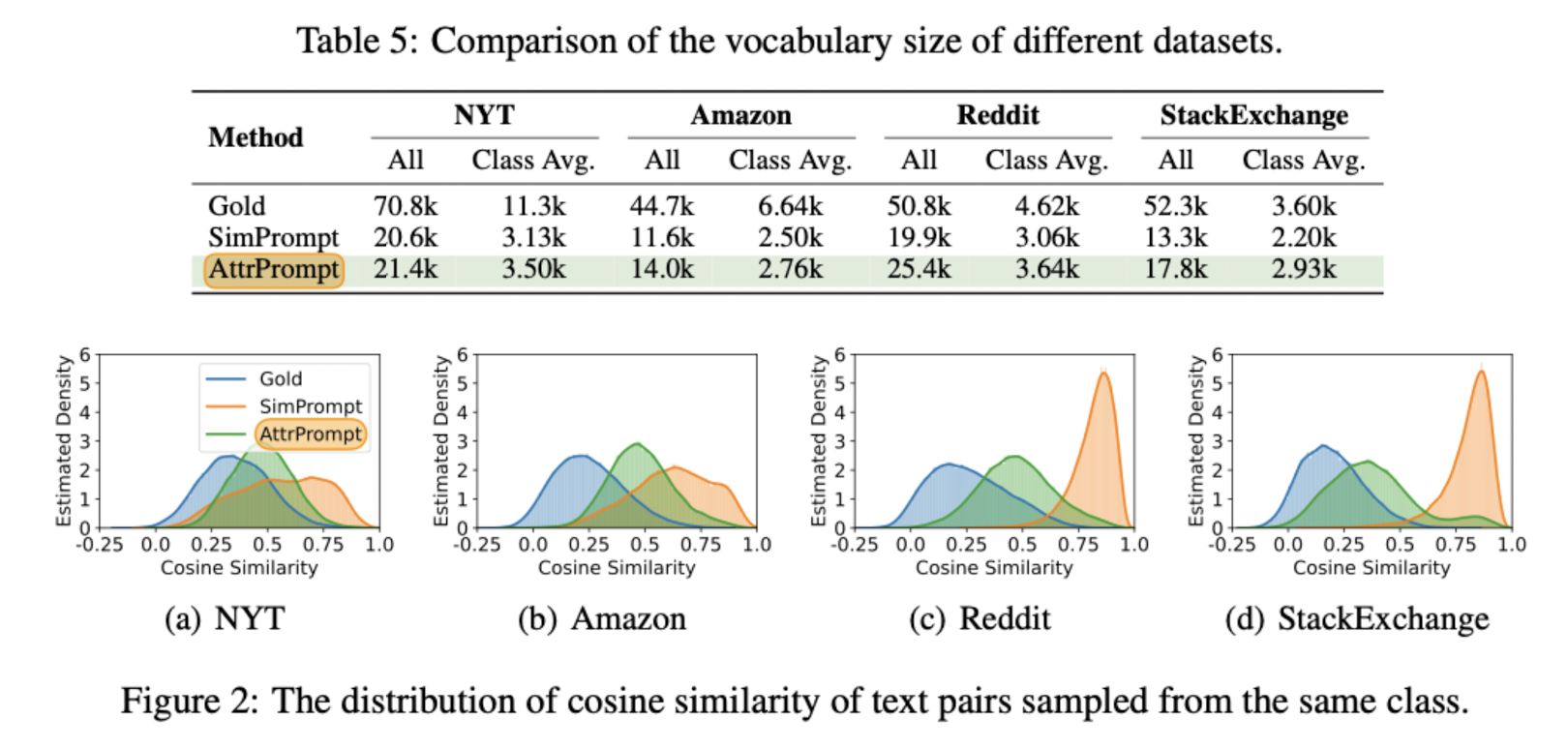
뿐만 아니라 Gold 데이터셋의 vocab size와 본 논문의 데이터셋 AttrPrompt, 그리고 비교군인 SimPrompt의 vocab size를 비교하여 어휘의 다양성도 확인했습니다.
- 개인적 감상
논문 저자가 스스로 언급하기도 했지만, 이 연구의 한계라면 굉장히 specific한 태스크에 한정된 방식이라는 점입니다.
즉, annotation 비용을 획기적으로 줄이면서도 고품질의 데이터셋을 확보하는 데 LLM을 활용하는 이 방식은, NLP의 분류 태스크에만 적합한 것이죠.
정확히는 이것에 대해서만 적합하다기보다는 아직 다른 분야로 활용하기엔 여러 장벽이 존재하는 것으로 보입니다.
예를 들어 이미지 분류의 경우 이러한 방식을 그대로 적용하기는 어려울 것입니다.
(멀티 모달 모델이 충분히 좋은 성능을 보인다면 가능할 것이라는 생각이 들긴 합니다)
그럼에도 불구하고 엄청난 양의 데이터를 필요로 하는 딥러닝 모델의 학습에 충분히 기여할 수 있을만한 방식이라는 생각이 듭니다.
특히 GPT-4 API가 일반 대중이 활용할 수 있도록 딱 오늘 풀렸는데요(2023.07.07), 이를 활용한 연구들이 또 쏟아져 나오면서 많은 성과들이 나타나지 않을까 기대가 됩니다.
Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias
Large language models (LLMs) have been recently leveraged as training data generators for various natural language processing (NLP) tasks. While previous research has explored different approaches to training models using generated data, they generally rel
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
다양한 특성을 반영할 수 있는 프롬프트를 이용해 LLM으로 NLP task를 위한 데이터 생성하기
- 배경
LLM이 활용되는 여러 분야 중 하나는 데이터 생성(generator)입니다.
문장 단위의 텍스트를 생성하는 능력이 워낙 탁월하고 그 품질이 사실상 보장된 것이기 때문에 적은 비용으로 고품질 데이터를 생성할 수 있음이 알려졌습니다.
그러나 기존의 연구들은 단순히 class-conditional prompt에 의존하고 있을 뿐이라고 지적합니다.
이에 의해 생성되는 데이터의 다양성이 보장되지도 않고 텍스트를 생성하는 LLM의 편향을 그대로 상속하는 문제점이 있다고 지적합니다.
이러한 문제점을 해결하기 위해 ‘attribute’ 개념을 사용하며 이것이 다양한 텍스트 생성을 목표로 삼습니다.
이를 통해 LLM이 가질 수 있는 편향성을 큰 폭으로 줄이고, 모델을 fine-tuning 할 때도 더 좋은 퍼포먼스로 이어지는데 기여했다고 합니다.
- 특징
attribute라는 개념이 생소하게 느껴질 수 있지만 사실 들어보면 어려운 것은 아닙니다.
예를 들면 문장의 길이, 스타일 등이 있습니다.
attribute는 class-dependent vs class-independent한 것들로 나뉩니다.
방금 언급한 문장의 길이, 스타일 등은 클래스의 종류와 무관한 것들이지만, subtopic과 같은 attribute는 클래스에 따라 다른 의미를 지닐 수도 있습니다.
따라서 본 논문에서는 class-dependent value를 filtering함으로써 고품질의 데이터셋 생성에 힘을 보탰습니다.
데이터를 생성할 때는 configuration을 매번 random하게 설정함으로써 diversity를 보장하고자 했습니다.
재밌는 것은 LLM의 bias를 줄이기 위해 직접 annotation을 수행했다는 것입니다.
예를 들어 location과 같은 attribute가 North America에 지나치게 편향되어 있다는 문제점을 해결하기 위해, 모든 지역 분류에 대해 고른 분포의 데이터셋을 구성했습니다.
뿐만 아니라 Gold 데이터셋의 vocab size와 본 논문의 데이터셋 AttrPrompt, 그리고 비교군인 SimPrompt의 vocab size를 비교하여 어휘의 다양성도 확인했습니다.
- 개인적 감상
논문 저자가 스스로 언급하기도 했지만, 이 연구의 한계라면 굉장히 specific한 태스크에 한정된 방식이라는 점입니다.
즉, annotation 비용을 획기적으로 줄이면서도 고품질의 데이터셋을 확보하는 데 LLM을 활용하는 이 방식은, NLP의 분류 태스크에만 적합한 것이죠.
정확히는 이것에 대해서만 적합하다기보다는 아직 다른 분야로 활용하기엔 여러 장벽이 존재하는 것으로 보입니다.
예를 들어 이미지 분류의 경우 이러한 방식을 그대로 적용하기는 어려울 것입니다.
(멀티 모달 모델이 충분히 좋은 성능을 보인다면 가능할 것이라는 생각이 들긴 합니다)
그럼에도 불구하고 엄청난 양의 데이터를 필요로 하는 딥러닝 모델의 학습에 충분히 기여할 수 있을만한 방식이라는 생각이 듭니다.
특히 GPT-4 API가 일반 대중이 활용할 수 있도록 딱 오늘 풀렸는데요(2023.07.07), 이를 활용한 연구들이 또 쏟아져 나오면서 많은 성과들이 나타나지 않을까 기대가 됩니다.
Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias
Large language models (LLMs) have been recently leveraged as training data generators for various natural language processing (NLP) tasks. While previous research has explored different approaches to training models using generated data, they generally rel
arxiv.org