
[Microsoft Research]
dilated attention을 적용하여 computation complexity를 quadratic → linear 줄임.
엄청나게 긴 입력(1B token)을 처리할 수 있으면서도 성능을 잘 유지할 수 있는 모델 LONGNET을 제시.
- 배경
transformer 기반의 모델들이 좋은 성능을 보이는 것 이면에는, 엄청나게 많은 자원을 필요로 한다는 문제점이 존재하고 있습니다.
self-attention 방식을 생각해보면 하나의 Key가 모든 Query, Value와 연산을 수행하게 되면서 quadratic한 시간 복잡도를 갖게 되기 때문이죠.
(쉽게 표현하면 O(N^2)라고 할 수 있겠네요)
결국 모델이 처리할 수 있는 입력의 길이가 상당히 제한되고, 이것이 지금까지도 많은 연구자들이 극복하고자 하는 문제점입니다.
본 논문에서는 이런 문제점을 극복하고, 무려 최대 10억(1B) 개의 토큰을 한 번에 처리할 수 있는 모델을 개발했다고 합니다.
- 특징 : dilated attention
지금까지 attention 기법의 효율을 높이기 위해 여러 시도가 있었습니다.
가장 대표적으로는 sliding window를 적용하는 방식이 있는데요, 본 논문에서는 이것보다도 더 적은 시간복잡도로 연산을 수행하는 방식을 택했습니다.
수식적인 부분에 대해 깊은 이해가 필요하신 분들은 이 논문을 직접 한 번 공부해보시는 걸 추천드립니다.
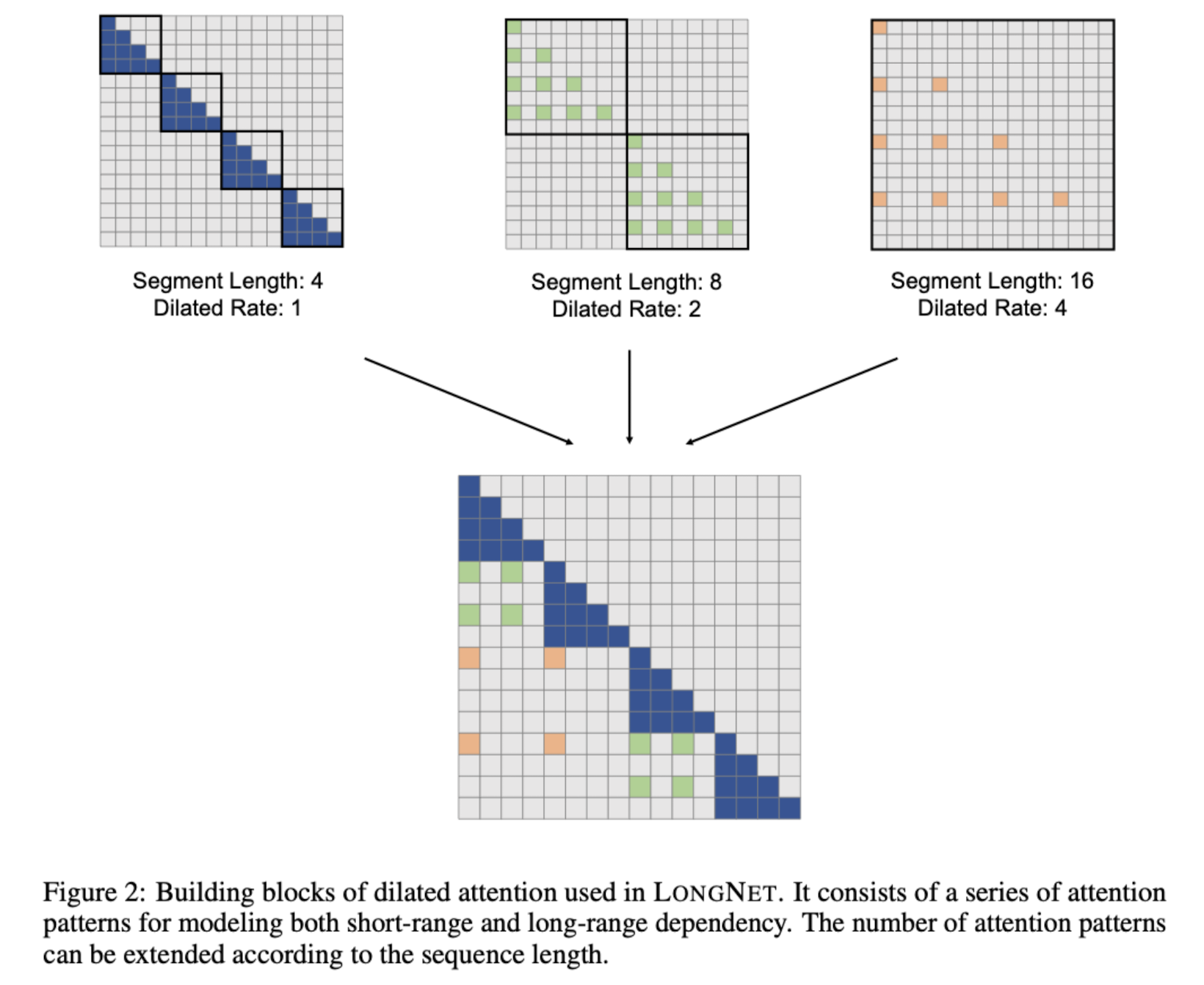
이미지를 보시면 dilated rate에 따라 연산을 수행하는 대상들의 간격이 넓어지고 있다는 것을 알 수 있습니다.
덕분에 모델의 사이즈를 키울수록 모델 성능이 지속적으로 상승하는 결과를 확인할 수 있습니다.
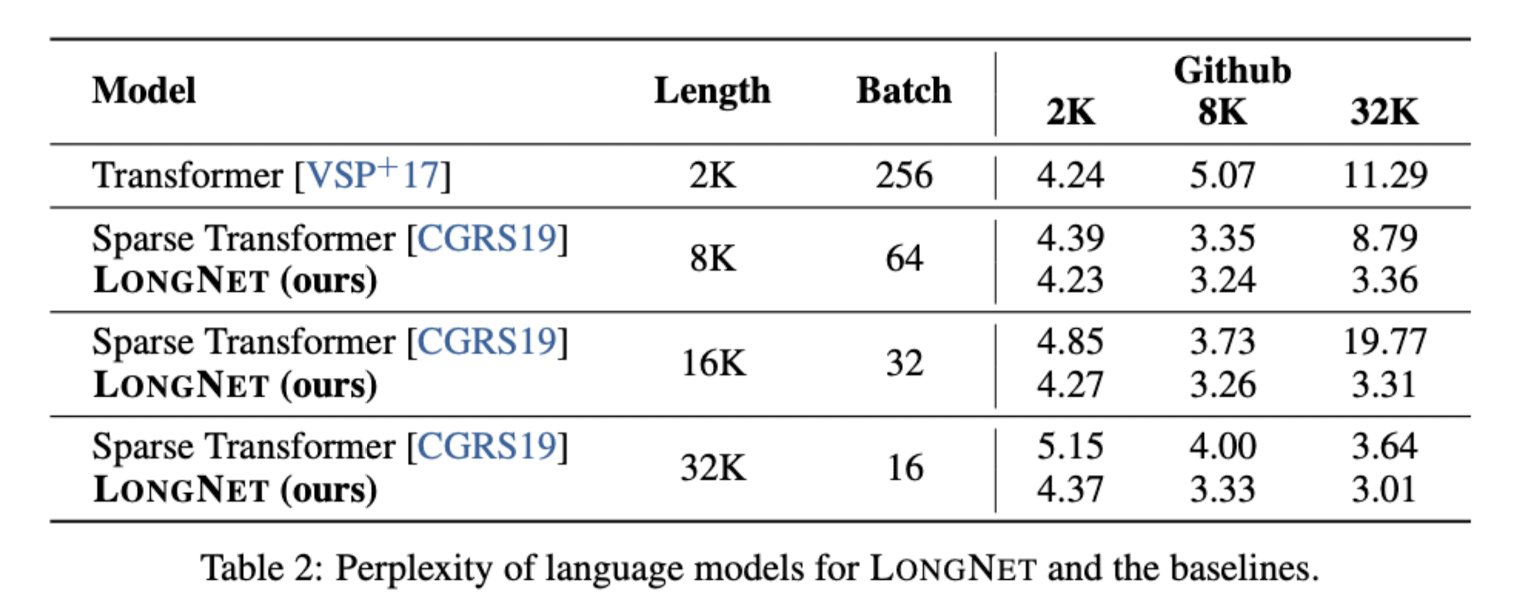
Sparse Transformer와 비교했을 때, Sparse Transformer는 사이즈와 perplexity의 반비례 관계가 유지되지 않습니다.
(scaling law)
- 개인적 감상
ChatGPT, GPT API가 엄청난 인기를 끌게 되면서 항상 아쉽게 느껴지는 것이 입력 길이의 제한일 것입니다.
저도 논문을 자주 읽으면서 이런 논문을 깔끔하게 정리하고 요약해줄 수 있는 방식에 대해 고민을 해본 적이 있는데 입력 길이 제한 때문에 뭘 제대로 하기가 어려웠거든요.
이 논문 뿐만 아니라 여러 연구자분들이 모델 입력 길이 제한을 기존 대비 향상시킬 수 있는 방법에 대해 많이 연구중인 것으로 알고 있는데 시의 적절한 연구 결과라는 생각이 들었습니다.
그러나 모델 성능을 검증하는 방식에 대해 의문이 듭니다.
결국 실질적으로 활용되었을 때 10억 개나 되는 토큰을 입력으로 받아 명령을 제대로 수행할 수 있을지에 대해서는 의문이 듭니다.
단순히 perplexity(PPL)이 감소했다고 해서 우리가 일반적으로 생각할 수 있는 태스크들에 대해서 문제를 잘 처리할 수 있을지는 잘 모르겠습니다.
문장을 입력으로 받는다면 텍스트에 대해 전부 살펴보는 방식과 그렇지 않은 것은 분명 성능에서 차이를 보일 수 밖에 없는데 말이죠.
따라서 실질적인 모델 성능에 대한 연구 결과도 함께 제시되었다면 정말 좋았을 것 같습니다.
출처 : https://arxiv.org/abs//2307.02486
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Scaling sequence length has become a critical demand in the era of large language models. However, existing methods struggle with either computational complexity or model expressivity, rendering the maximum sequence length restricted. In this work, we intr
arxiv.org
'Paper Review' 카테고리의 다른 글
[Microsoft Research]
dilated attention을 적용하여 computation complexity를 quadratic → linear 줄임.
엄청나게 긴 입력(1B token)을 처리할 수 있으면서도 성능을 잘 유지할 수 있는 모델 LONGNET을 제시.
- 배경
transformer 기반의 모델들이 좋은 성능을 보이는 것 이면에는, 엄청나게 많은 자원을 필요로 한다는 문제점이 존재하고 있습니다.
self-attention 방식을 생각해보면 하나의 Key가 모든 Query, Value와 연산을 수행하게 되면서 quadratic한 시간 복잡도를 갖게 되기 때문이죠.
(쉽게 표현하면 O(N^2)라고 할 수 있겠네요)
결국 모델이 처리할 수 있는 입력의 길이가 상당히 제한되고, 이것이 지금까지도 많은 연구자들이 극복하고자 하는 문제점입니다.
본 논문에서는 이런 문제점을 극복하고, 무려 최대 10억(1B) 개의 토큰을 한 번에 처리할 수 있는 모델을 개발했다고 합니다.
- 특징 : dilated attention
지금까지 attention 기법의 효율을 높이기 위해 여러 시도가 있었습니다.
가장 대표적으로는 sliding window를 적용하는 방식이 있는데요, 본 논문에서는 이것보다도 더 적은 시간복잡도로 연산을 수행하는 방식을 택했습니다.
수식적인 부분에 대해 깊은 이해가 필요하신 분들은 이 논문을 직접 한 번 공부해보시는 걸 추천드립니다.
이미지를 보시면 dilated rate에 따라 연산을 수행하는 대상들의 간격이 넓어지고 있다는 것을 알 수 있습니다.
덕분에 모델의 사이즈를 키울수록 모델 성능이 지속적으로 상승하는 결과를 확인할 수 있습니다.
Sparse Transformer와 비교했을 때, Sparse Transformer는 사이즈와 perplexity의 반비례 관계가 유지되지 않습니다.
(scaling law)
- 개인적 감상
ChatGPT, GPT API가 엄청난 인기를 끌게 되면서 항상 아쉽게 느껴지는 것이 입력 길이의 제한일 것입니다.
저도 논문을 자주 읽으면서 이런 논문을 깔끔하게 정리하고 요약해줄 수 있는 방식에 대해 고민을 해본 적이 있는데 입력 길이 제한 때문에 뭘 제대로 하기가 어려웠거든요.
이 논문 뿐만 아니라 여러 연구자분들이 모델 입력 길이 제한을 기존 대비 향상시킬 수 있는 방법에 대해 많이 연구중인 것으로 알고 있는데 시의 적절한 연구 결과라는 생각이 들었습니다.
그러나 모델 성능을 검증하는 방식에 대해 의문이 듭니다.
결국 실질적으로 활용되었을 때 10억 개나 되는 토큰을 입력으로 받아 명령을 제대로 수행할 수 있을지에 대해서는 의문이 듭니다.
단순히 perplexity(PPL)이 감소했다고 해서 우리가 일반적으로 생각할 수 있는 태스크들에 대해서 문제를 잘 처리할 수 있을지는 잘 모르겠습니다.
문장을 입력으로 받는다면 텍스트에 대해 전부 살펴보는 방식과 그렇지 않은 것은 분명 성능에서 차이를 보일 수 밖에 없는데 말이죠.
따라서 실질적인 모델 성능에 대한 연구 결과도 함께 제시되었다면 정말 좋았을 것 같습니다.
출처 : https://arxiv.org/abs//2307.02486
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Scaling sequence length has become a critical demand in the era of large language models. However, existing methods struggle with either computational complexity or model expressivity, rendering the maximum sequence length restricted. In this work, we intr
arxiv.org