
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLM의 기반이 되는 Retentive Network (RETNET)을 제안.
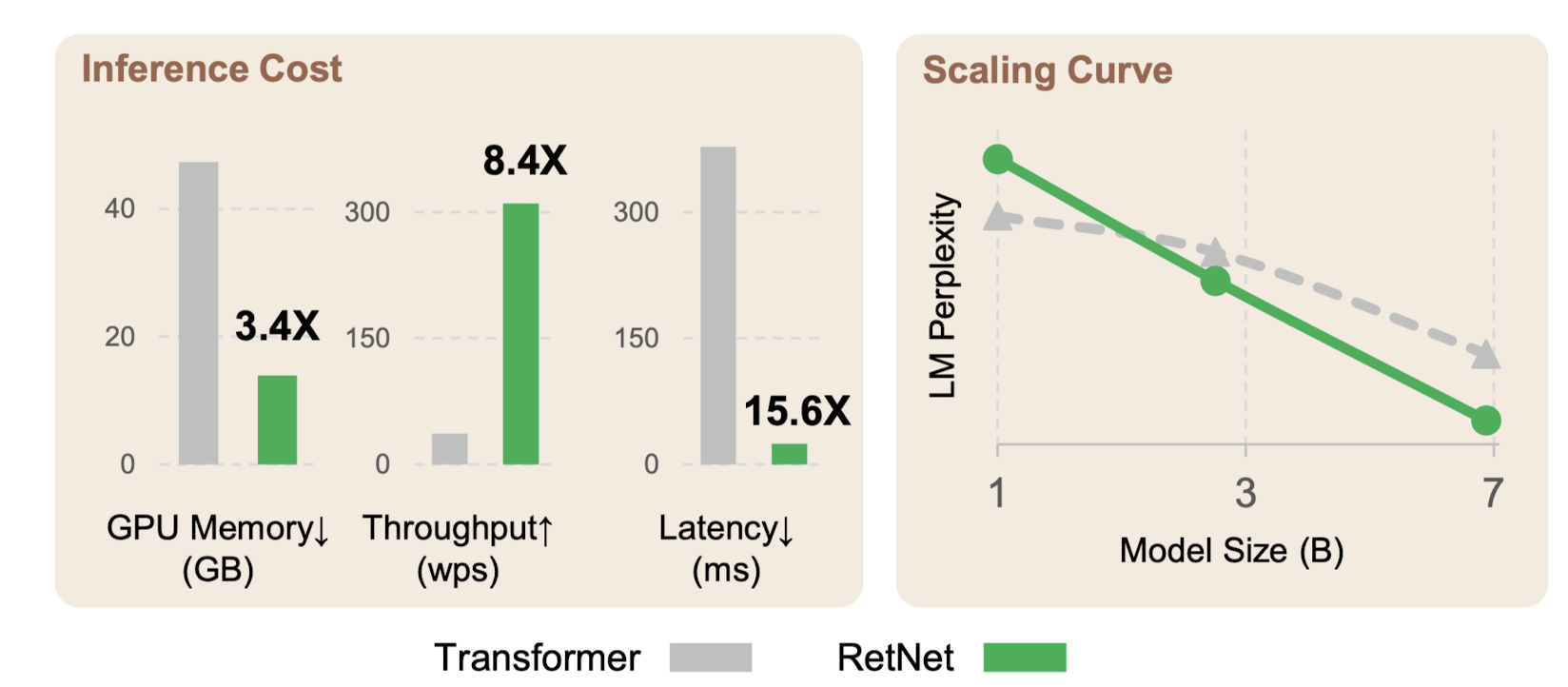
scaling results, parallel training, low-cost deployment, efficient inference를 달성했다고 주장.
- 배경
트랜스포머 기반의 모델들은 그 뛰어난 성능 덕분에 많은 분야를 집어 삼키고 있지만, 지나치게 많이 요구되는 메모리 사용량과 연산량으로 인해 사용에 제약이 많습니다.
따라서 빠른 속도로 연산이 가능하면서도 준수한 성능을 낼 수 있는 모델에 대한 연구는 다방면으로 이뤄지고 있습니다.
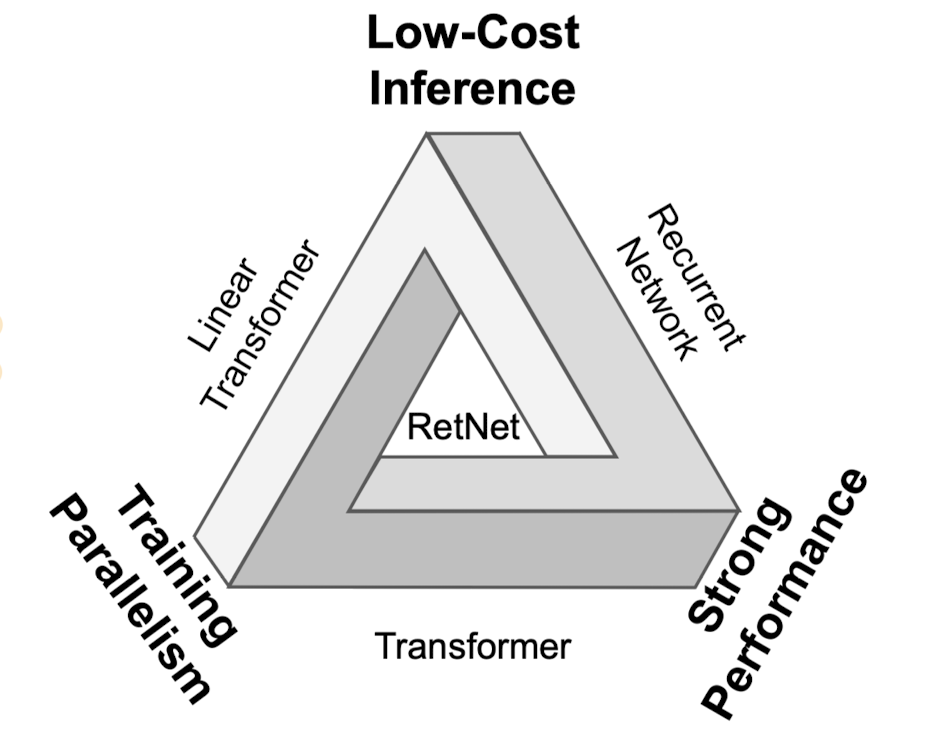
모델의 성능과 관련된 지표중에서, 일종의 trade-off 관계를 갖는 요소들을 ‘impossible triangle’로 표현하고 있습니다.
‘Low-Cost Inference, Training Parralelism, Strong Performance’가 세 요소이고 기존의 모델들은 이를 동시에 만족시킬 수 없었으나 ‘Retentive Network’가 이를 달성한 것을 본 연구의 성과로 제시합니다.
- 특징
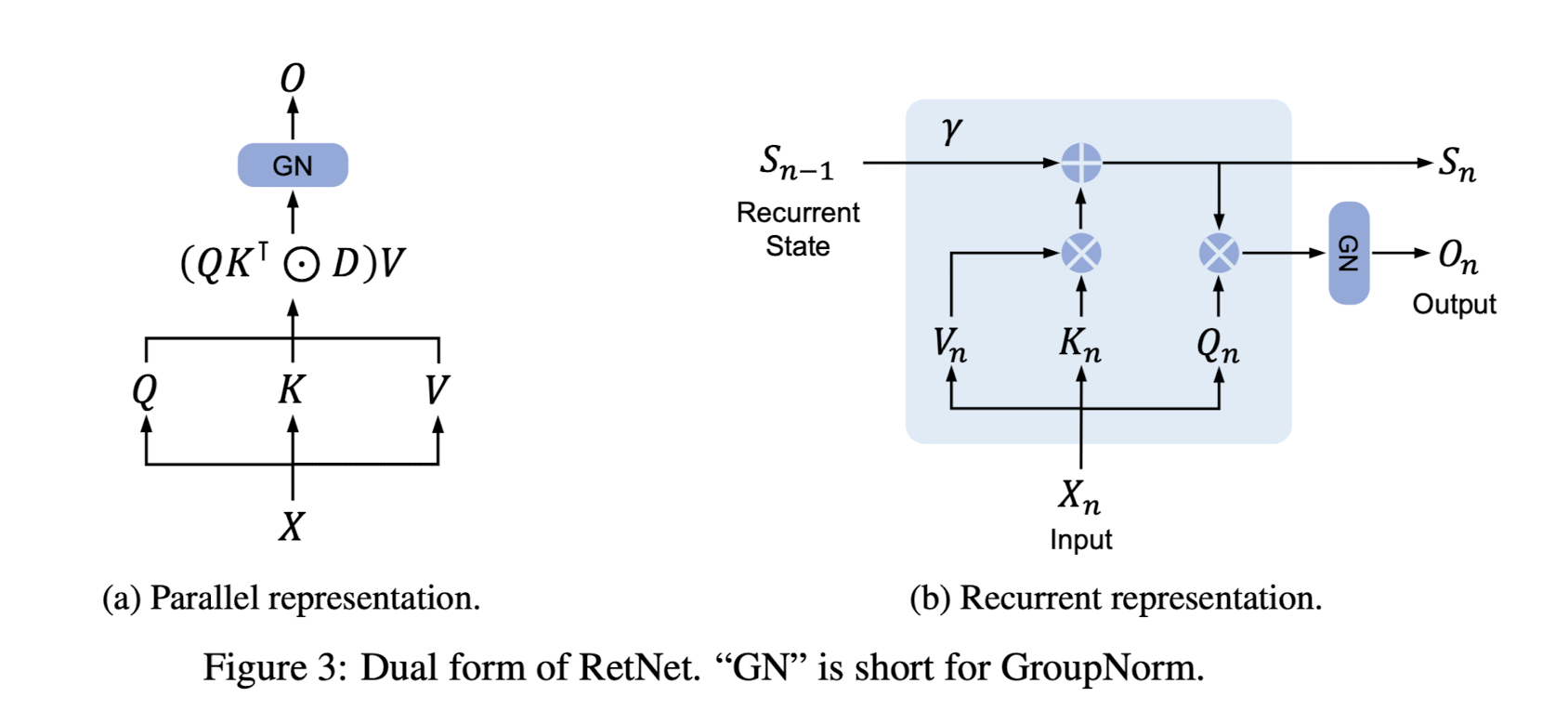
마치 transformer의 아키텍쳐에서 attention만 똑 떼어온 듯한 식이 보입니다.
이는 본 모델에서 사용되는 retention이라는 구조로, 수식적인 유도를 파악하고 이해하기 원하시는 분들은 논문(p.4)을 직접 살펴보시길 추천드립니다.
어쨌든 위 그림이 시사하는 바는 추론 속도에 강점이 있는 RNN representation을 갖는다는 것입니다.
(두 그림은 동일한 구조를 나타내고 있고, 이해를 돕기 위해 각 단계를 기준으로 펼쳐놓은 것이 오른쪽 그림입니다)
또한 논문에서는 ‘Chunkwise Recurrent Representation of Retention’이라는 개념을 제시하고 있는데, 학습 속도를 빠르게 만들어주는 요소입니다.
(마찬가지로 자세한 수식은 논문 p.4를 참고해주세요)
이런 구조는 병렬화에 특화되어 있어 GPU로 연산을 수행할 때 그 연산 속도를 크게 높일 수 있습니다.
전체적인 아키텍쳐는 MSR(Multi-Scale Retention)과 FFN(Feed-Forward Network)를 결합한 형태가 됩니다.
각 레이어의 입력을 Score Normalize하여 MSR을 적용한 것을 기존 입력과 합치고, 그 결과를 또 Score Normalize하여 FFN의 입력으로 제공합니다.
이때 적용하는 normalize로 인해 입력에 대해 상수를 곱하더라도 그 출력과 미분 계수가 동일하게 구해집니다.
즉, scale-invariant한 특징을 갖게 되는 것입니다.
- 개인적 감상
transformer 구조에 최대한 종속되지 않고자 하는 연구는 참 대단한 것 같습니다.
사실 좋은 성능을 보이는 방식을 활용하거나 기존 흐름에 편승하는 것도 쉽지 않은 일인데 말이죠.
한편 본 논문에서 주장하는 바와 같이 Retention 기법을 이용한 모델이 transformer 기반의 모델을 넘어서는 성능을 가지면서도 Flash Attention보다도 빠른 추론 속도를 갖는지에 대해서는 추가적인 검증이 필요한 것으로 보이긴 합니다.
또한 배치 사이즈에 대한 실험 내용도 있었는데, 그 비교가 굉장히 부적절하다는 생각이 들었습니다.
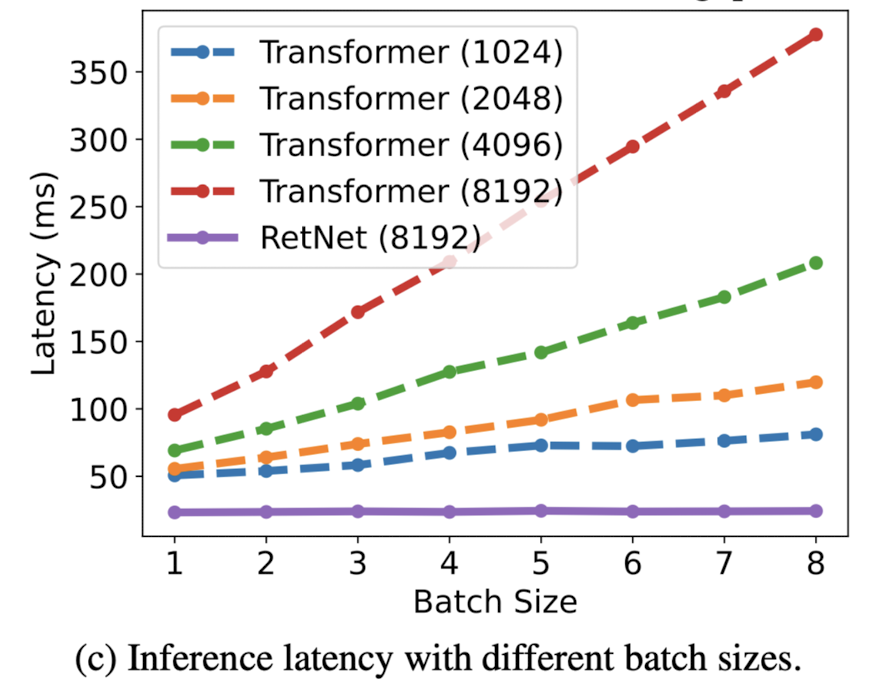
transformer 기반의 모델들은 보통 훨씬 더 큰 배치사이즈를 사용하여 학습하는 것으로 알려져 있는데, 최대 8까지의 비교가 어떤 의미를 갖는지 잘 모르겠습니다.
자원상의 한계로 인해 위와 같은 실험을 한 것으로 언급했는데, 본 연구에서 가장 아쉬운 점으로 느껴집니다.
출처 : https://arxiv.org/abs/2307.0862
Retentive Network: A Successor to Transformer for Large Language Models
In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence a
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.07)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
LLM의 기반이 되는 Retentive Network (RETNET)을 제안.
scaling results, parallel training, low-cost deployment, efficient inference를 달성했다고 주장.
- 배경
트랜스포머 기반의 모델들은 그 뛰어난 성능 덕분에 많은 분야를 집어 삼키고 있지만, 지나치게 많이 요구되는 메모리 사용량과 연산량으로 인해 사용에 제약이 많습니다.
따라서 빠른 속도로 연산이 가능하면서도 준수한 성능을 낼 수 있는 모델에 대한 연구는 다방면으로 이뤄지고 있습니다.
모델의 성능과 관련된 지표중에서, 일종의 trade-off 관계를 갖는 요소들을 ‘impossible triangle’로 표현하고 있습니다.
‘Low-Cost Inference, Training Parralelism, Strong Performance’가 세 요소이고 기존의 모델들은 이를 동시에 만족시킬 수 없었으나 ‘Retentive Network’가 이를 달성한 것을 본 연구의 성과로 제시합니다.
- 특징
마치 transformer의 아키텍쳐에서 attention만 똑 떼어온 듯한 식이 보입니다.
이는 본 모델에서 사용되는 retention이라는 구조로, 수식적인 유도를 파악하고 이해하기 원하시는 분들은 논문(p.4)을 직접 살펴보시길 추천드립니다.
어쨌든 위 그림이 시사하는 바는 추론 속도에 강점이 있는 RNN representation을 갖는다는 것입니다.
(두 그림은 동일한 구조를 나타내고 있고, 이해를 돕기 위해 각 단계를 기준으로 펼쳐놓은 것이 오른쪽 그림입니다)
또한 논문에서는 ‘Chunkwise Recurrent Representation of Retention’이라는 개념을 제시하고 있는데, 학습 속도를 빠르게 만들어주는 요소입니다.
(마찬가지로 자세한 수식은 논문 p.4를 참고해주세요)
이런 구조는 병렬화에 특화되어 있어 GPU로 연산을 수행할 때 그 연산 속도를 크게 높일 수 있습니다.
전체적인 아키텍쳐는 MSR(Multi-Scale Retention)과 FFN(Feed-Forward Network)를 결합한 형태가 됩니다.
각 레이어의 입력을 Score Normalize하여 MSR을 적용한 것을 기존 입력과 합치고, 그 결과를 또 Score Normalize하여 FFN의 입력으로 제공합니다.
이때 적용하는 normalize로 인해 입력에 대해 상수를 곱하더라도 그 출력과 미분 계수가 동일하게 구해집니다.
즉, scale-invariant한 특징을 갖게 되는 것입니다.
- 개인적 감상
transformer 구조에 최대한 종속되지 않고자 하는 연구는 참 대단한 것 같습니다.
사실 좋은 성능을 보이는 방식을 활용하거나 기존 흐름에 편승하는 것도 쉽지 않은 일인데 말이죠.
한편 본 논문에서 주장하는 바와 같이 Retention 기법을 이용한 모델이 transformer 기반의 모델을 넘어서는 성능을 가지면서도 Flash Attention보다도 빠른 추론 속도를 갖는지에 대해서는 추가적인 검증이 필요한 것으로 보이긴 합니다.
또한 배치 사이즈에 대한 실험 내용도 있었는데, 그 비교가 굉장히 부적절하다는 생각이 들었습니다.
transformer 기반의 모델들은 보통 훨씬 더 큰 배치사이즈를 사용하여 학습하는 것으로 알려져 있는데, 최대 8까지의 비교가 어떤 의미를 갖는지 잘 모르겠습니다.
자원상의 한계로 인해 위와 같은 실험을 한 것으로 언급했는데, 본 연구에서 가장 아쉬운 점으로 느껴집니다.
출처 : https://arxiv.org/abs/2307.0862
Retentive Network: A Successor to Transformer for Large Language Models
In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence a
arxiv.org