
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft]
Evol-Instruct 데이터셋을 StarCoder 모델에 fine-tuning한 모델 WizardCoder.
모든 Open Source 모델을 압도, 여러 Closed Source 모델보다 우위.
먼저 읽으면 좋은 논문 : https://chanmuzi.tistory.com/378
- 배경
LLM이 학습하는데 도움을 주는 instruction dataset을 구축하기 위한 방법으로 제안된 Evol-Instruct를 Code 모델에 특화시키는 방식을 제안하고 있습니다.
위 링크의 요약을 확인해보시면 어떤 방식으로 instruction dataset을 구축했는지에 대해 이해할 수 있습니다.
이번 연구의 가장 큰 핵심적 기여는 여러 closed source 모델을 넘어서는 성능을 보여주었다는 것입니다.
모델의 아키텍쳐나 가중치가 공개되어 있는 오픈 소스 모델(예를 들어 LLaMA, 여기서는 StarCoder 등)들은 분명 좋은 성능을 보이지만,
대중에게 공개되지 않은 기업만의 기술로 발전된 모델들(예를 들어 GPT-4, PaLM-2 등)의 성능에 한참 미치지 못한다는 한계를 보이고 있습니다.
그도 그럴 것이 애초에 모델의 사이즈에서부터 엄청나게 큰 차이가 나고,
많은 오픈 소스 모델들이 closed source 모델의 API를 활용하는 등의 방법을 이용할 뿐이기 때문이죠.
따라서 여기에서의 성과는 단순히 open source 모델들 중에서 가장 좋은 성능을 보이는 모델을 개발했다는 것 뿐만 아니라,
일부 closed source 모델들(예를 들어 Anthropic의 Claude) 또한 유의미하게 넘어섰다는 것이라고 볼 수 있겠습니다.
- 방법론
backbone 모델로는 StarCoder를 활용했습니다.
여기에 Code Evol-Instruct 데이터셋을 학습 데이터로 삼습니다.
총 다섯 가지의 Evolution 방식을 이용했다고 언급이 되어 있고, 구체적인 예시는 아래 이미지와 같습니다.

추가로 prompt template은 기존 대비 굉장히 간소화하여 아래와 같이 사용했다고 합니다.

맨 처음 seed data는 Code Alpaca라고 불리는 20K의 instruction dataset입니다.
이를 반복적으로 확장하는데, 첫 round에서는 20K -> 38K가 되고, 두 번째 round에서는 38K -> 58K가 되고, 세 번째 round에서는 58K -> 78K가 된다고 합니다.
pass@1 score로 벤치마크를 테스트할 때, 78K의 instruction data를 갖는 것의 효율(성능)이 가장 좋다고 확인되어 이를 사용했다고 합니다.
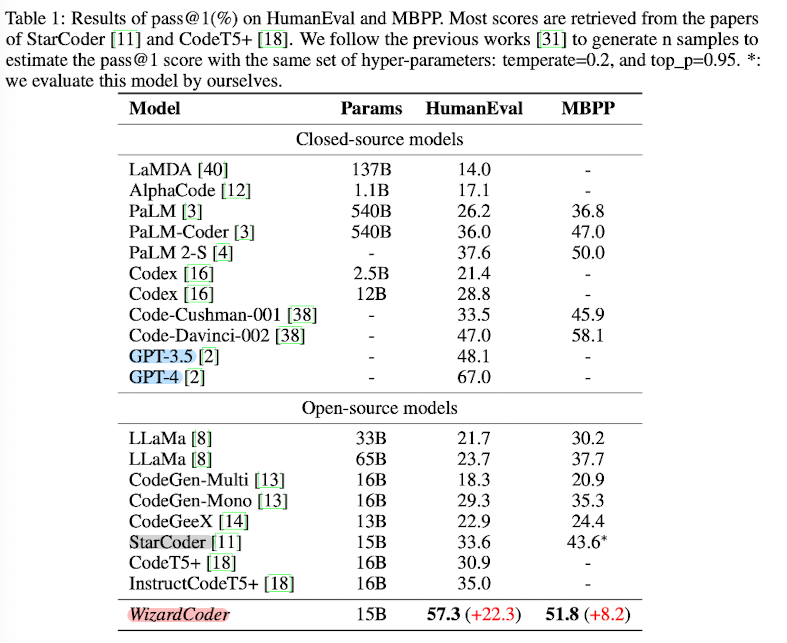
평가를 위한 벤치마크는 'HumanEval, HumanEval+, MBPP, DS-1000' 네 개를 사용했다고 합니다.
위 표는 네 개의 벤치마크 중에서 'HumanEval & MBPP'에 대한 평가 결과입니다.
위에서 언급했던 것처럼, Open-source model들은 전부 WizardCoder가 압도하는 반면, GPT-4에는 한참 못 미치는 성능을 보여줍니다.
그럼에도 불구하고 기존의 instruction 방식으로 학습된 모델들에 비해서도 더 좋은 성능을 보인다는 것이 주목할만한 점입니다.
- 개인적 감상
코드 데이터를 위주로 학습된 모델이 일반 모델들보다 대화 능력이 우수하다고 알려질 정도로,
LLM에게 코드를 학습시키는 것은 굉장히 재밌는 분야라는 생각이 듭니다.
개인적으로는 Vicuna에서 ShareGPT에 노출된 실제 사용자들의 데이터를 이용하여 학습한 것이 참 인상 깊었는데,
이를 넘어서는 고퀄리티의 데이터셋을 잘 만들고 학습에 활용한 훌륭한 사례라는 생각이 듭니다.
그럼에도 참 아쉬운 것은 GPT-4에 성능이 한참 미치지 못한다는 것입니다.
그만큼 GPT-4가 우수한 성능을 보이는 강력한 모델이라는 증거이기도 하겠지만 이를 넘어서기에 한참 부족하다는 것이 참 안타깝습니다.
언제쯤 오픈 소스 모델들이 단순히 '가성비가 좋은 모델'의 입장을 벗어날 수 있을지 궁금합니다.
출처 : https://arxiv.org/abs/2306.08568
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
Code Large Language Models (Code LLMs), such as StarCoder, have demonstrated exceptional performance in code-related tasks. However, most existing models are solely pre-trained on extensive raw code data without instruction fine-tuning. In this paper, we i
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.06)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft]
Evol-Instruct 데이터셋을 StarCoder 모델에 fine-tuning한 모델 WizardCoder.
모든 Open Source 모델을 압도, 여러 Closed Source 모델보다 우위.
먼저 읽으면 좋은 논문 : https://chanmuzi.tistory.com/378
- 배경
LLM이 학습하는데 도움을 주는 instruction dataset을 구축하기 위한 방법으로 제안된 Evol-Instruct를 Code 모델에 특화시키는 방식을 제안하고 있습니다.
위 링크의 요약을 확인해보시면 어떤 방식으로 instruction dataset을 구축했는지에 대해 이해할 수 있습니다.
이번 연구의 가장 큰 핵심적 기여는 여러 closed source 모델을 넘어서는 성능을 보여주었다는 것입니다.
모델의 아키텍쳐나 가중치가 공개되어 있는 오픈 소스 모델(예를 들어 LLaMA, 여기서는 StarCoder 등)들은 분명 좋은 성능을 보이지만,
대중에게 공개되지 않은 기업만의 기술로 발전된 모델들(예를 들어 GPT-4, PaLM-2 등)의 성능에 한참 미치지 못한다는 한계를 보이고 있습니다.
그도 그럴 것이 애초에 모델의 사이즈에서부터 엄청나게 큰 차이가 나고,
많은 오픈 소스 모델들이 closed source 모델의 API를 활용하는 등의 방법을 이용할 뿐이기 때문이죠.
따라서 여기에서의 성과는 단순히 open source 모델들 중에서 가장 좋은 성능을 보이는 모델을 개발했다는 것 뿐만 아니라,
일부 closed source 모델들(예를 들어 Anthropic의 Claude) 또한 유의미하게 넘어섰다는 것이라고 볼 수 있겠습니다.
- 방법론
backbone 모델로는 StarCoder를 활용했습니다.
여기에 Code Evol-Instruct 데이터셋을 학습 데이터로 삼습니다.
총 다섯 가지의 Evolution 방식을 이용했다고 언급이 되어 있고, 구체적인 예시는 아래 이미지와 같습니다.
추가로 prompt template은 기존 대비 굉장히 간소화하여 아래와 같이 사용했다고 합니다.
맨 처음 seed data는 Code Alpaca라고 불리는 20K의 instruction dataset입니다.
이를 반복적으로 확장하는데, 첫 round에서는 20K -> 38K가 되고, 두 번째 round에서는 38K -> 58K가 되고, 세 번째 round에서는 58K -> 78K가 된다고 합니다.
pass@1 score로 벤치마크를 테스트할 때, 78K의 instruction data를 갖는 것의 효율(성능)이 가장 좋다고 확인되어 이를 사용했다고 합니다.
평가를 위한 벤치마크는 'HumanEval, HumanEval+, MBPP, DS-1000' 네 개를 사용했다고 합니다.
위 표는 네 개의 벤치마크 중에서 'HumanEval & MBPP'에 대한 평가 결과입니다.
위에서 언급했던 것처럼, Open-source model들은 전부 WizardCoder가 압도하는 반면, GPT-4에는 한참 못 미치는 성능을 보여줍니다.
그럼에도 불구하고 기존의 instruction 방식으로 학습된 모델들에 비해서도 더 좋은 성능을 보인다는 것이 주목할만한 점입니다.
- 개인적 감상
코드 데이터를 위주로 학습된 모델이 일반 모델들보다 대화 능력이 우수하다고 알려질 정도로,
LLM에게 코드를 학습시키는 것은 굉장히 재밌는 분야라는 생각이 듭니다.
개인적으로는 Vicuna에서 ShareGPT에 노출된 실제 사용자들의 데이터를 이용하여 학습한 것이 참 인상 깊었는데,
이를 넘어서는 고퀄리티의 데이터셋을 잘 만들고 학습에 활용한 훌륭한 사례라는 생각이 듭니다.
그럼에도 참 아쉬운 것은 GPT-4에 성능이 한참 미치지 못한다는 것입니다.
그만큼 GPT-4가 우수한 성능을 보이는 강력한 모델이라는 증거이기도 하겠지만 이를 넘어서기에 한참 부족하다는 것이 참 안타깝습니다.
언제쯤 오픈 소스 모델들이 단순히 '가성비가 좋은 모델'의 입장을 벗어날 수 있을지 궁금합니다.
출처 : https://arxiv.org/abs/2306.08568
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
Code Large Language Models (Code LLMs), such as StarCoder, have demonstrated exceptional performance in code-related tasks. However, most existing models are solely pre-trained on extensive raw code data without instruction fine-tuning. In this paper, we i
arxiv.org