
최근(2023.04)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft]
대량의 instruction data를 생성하는 방법론 Evol-Instruct을 제시.
이를 이용해 생성한 데이터셋으로 fine-tuning한 모델 WizardLM이 Alpaca, Vicuna를 압도.
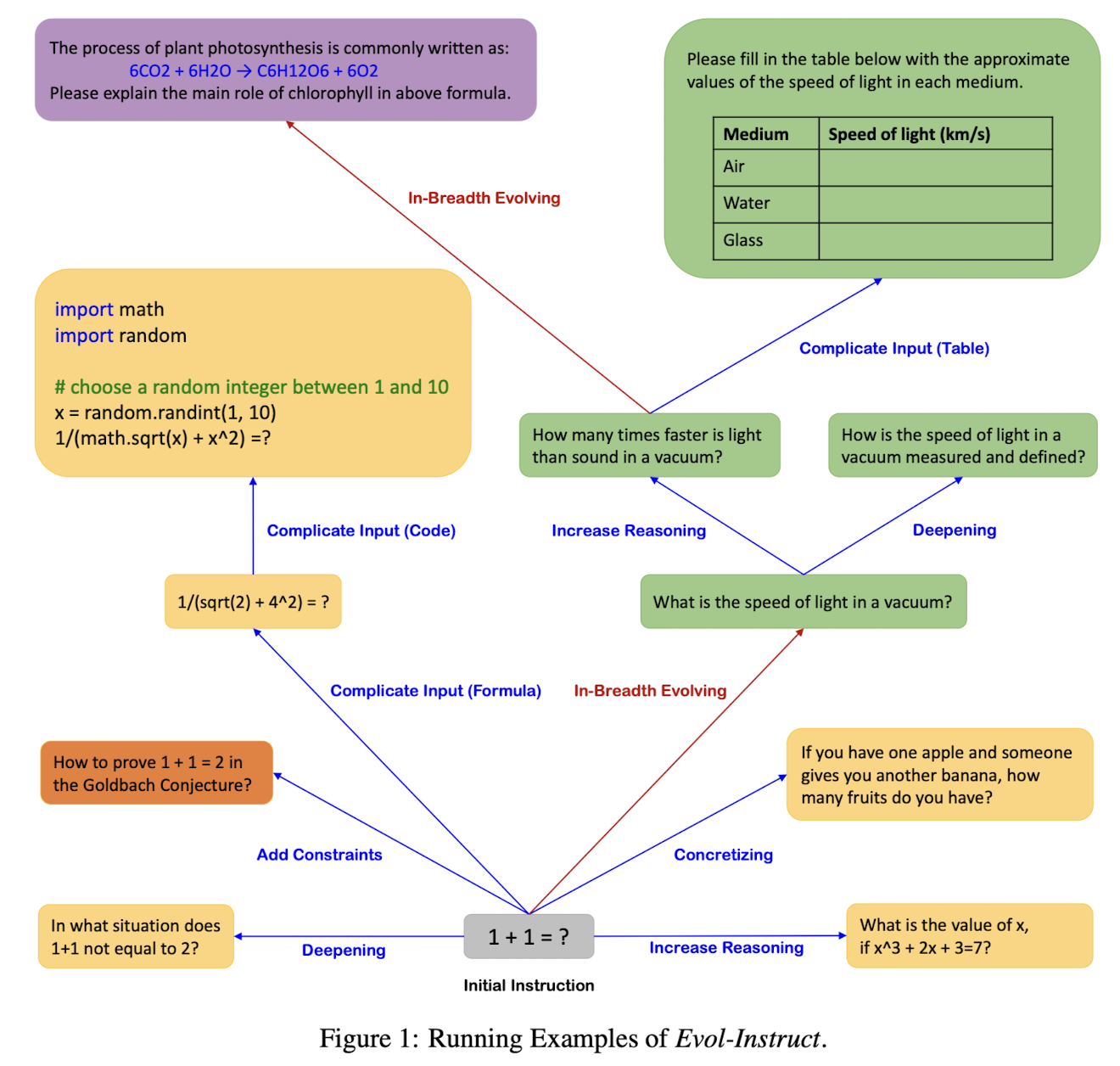
- 배경
LLM이 instruction data를 활용하는 경우, 그 성능이 눈에 띄게 좋아진다는 것은 잘 알려져 있습니다.
우리에게 익숙한 ChatGPT도 이를 적극적으로 잘 활용하여 학습된 모델이죠.
예전에는 instruction data라고 해봤자, 특정 도메인에 한정되고(closed-domain) 아주 간단한 수준의 태스크만 다루었고,
이를 엄청난 자본과 인력으로 커버한 대표적인 기업이 OpenAI죠.
수많은 annotator를 고용하여 만든 데이터셋으로 학습된 모델이 세상에 알려지게 되었습니다.
하지만 이러한 방식은 너무나도 많은 자원과 시간을 요하기에 앞으로의 발전을 꾀하기에는 어려움이 있습니다.
본 논문에서는 이를 인지하고 고품질이면서도 다양성을 갖춘 instruction data를 언어 모델을 통해 생성하는 전략을 제시합니다.
- 특징
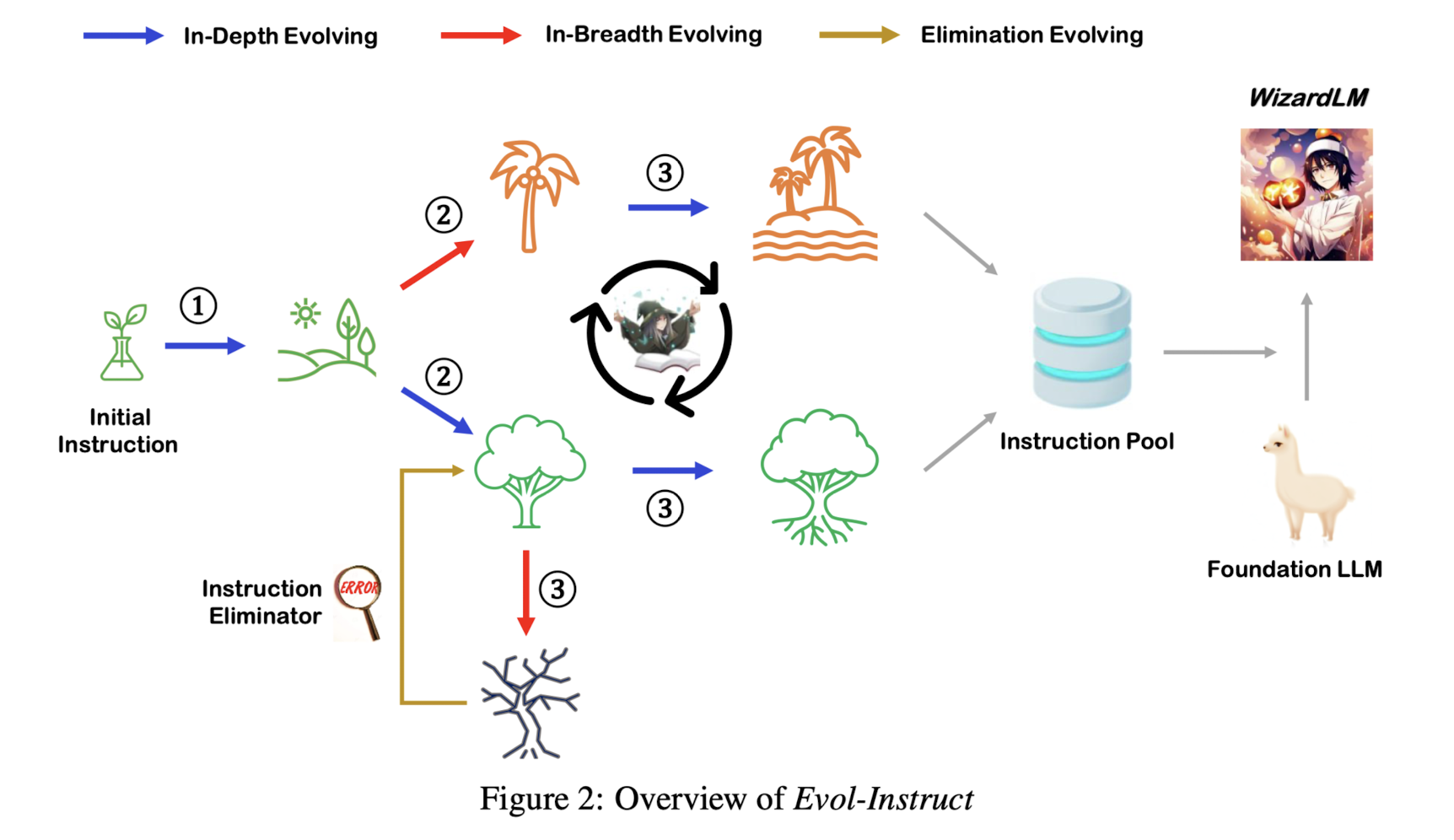
1) seed dataset
위에서 언급한 바와 같이, 예전에는 open-domain instruction의 성격이 강했습니다.
이와 달리 open-domain intruction dataset을 만드는 것을 목표로 하고 있는데, 여기에는 인터넷 상의 무수히 많은 데이터들을 이용하는 것이 중요합니다.
본 연구에서는 alpaca를 학습하는데 사용된 50k instruction과, vicuna를 학습하는데 사용된 70k instruction(from ShareGPT)를 시드로 삼습니다.
2) Three steps: instruction evolving, response generation, elimination evolving
2-1) instruction evolving
in-depth evolving과 in-breadth evolving으로 나뉩니다.
더 복잡하고 어려운 문장을 생성하도록 유도하는 in-depth evolving에는 'add constraints, deepening, concretizing, increased reasoning steps, complicating input' 다섯 가지 방식이 포함됩니다.
한편 in-breadth는 더 다양하고 많은 주제를 다룰 수 있도록 유도하는 방식을 말합니다.
따라서 총 6개의 방법론이 매 단계에서 random하게 적용된다는 것으로 이해할 수 있습니다.
2-2) response generation
LLM을 이용하여 주어진 instruction에 대한 response를 생성합니다.
2-3) elimination evoling
다음과 같은 조건에 해당하는 instruction은 삭제합니다.
1. 기존의 instruction과 비교했을 때, 추가적인 정보를 제공하지 않는 경우
2. LLM이 response를 생성하기 어려워하는 instruction인 경우(sorry 등으로 답하는 경우)
3. LLM이 구두점과 불용어로만 reponse를 생성하는 경우
4. given prompt와 같은 시스템 메세지를 반환하는 경우
위 과정을 반복적으로 수행하여 수행 난이도는 높고 다양한 주제를 다룰 수 있는 instruciton dataset를 생성할 수 있습니다.
3) evaluation
Evol-Instruct로 학습한 모델은 WizardLM입니다.
이를 Alpaca, Vicuna, ChatGPT와 비교했습니다.
성능을 측정할 때는 Evol-Instruct의 testset과 Vicuna testset을 활용했습니다.
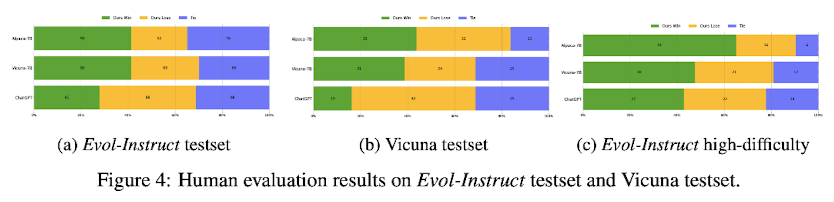
위 결과에서 볼 수 있는 것처럼, 두 testset에 대해서 WizardLM은 Alpaca, Vicuna에 비해 사람에거 더욱 선호되는 경향이 있고, ChatGPT에는 조금 못미치는 성능을 나타내고 있습니다.
특히 Evol-Instruct testset에서 난이도가 높은 것들에 대해서는 WizardLM이 ChatGPT보다 우월한 성능을 보여주었다는 것이 주목할만한 특징입니다.
이는 (Vicuna에서 도입했던 방식) 'GPT-4를 평가자'로 썼을 때의 결과와 동일합니다.
- 개인적 감상
날이 갈수록 고품질 데이터셋을 만드는 것(확보하는 것)의 중요성이 커지고 있는데,
이런 방법을 제안한 논문을 모르고 있었다는 것이 신기했습니다.
Instruction Dataset이 아니더라도 다양한 방식으로 LLM을 활용하여 데이터셋을 제작하고,
이를 학습 데이터로 이용하는 연구들이 많습니다.
개인적으로는 LIMA라는 논문이 가장 기억에 남는데 이런 식으로 고품질 데이터셋을 목적에 맞게끔 제작해보는 것도 좋은 경험이 될 것 같습니다.
다만 GPT-4와 Human annotator간 평가에서 차이가 존재한다는 점이 아쉽게 다가옵니다.
사실 인간에 가깝게, 인간에게 가장 선호되게끔 학습한 모델이 주목을 받고 성능이 좋은 것으로 인식되는데,
어찌보면 align이 잘 되지 않은 것으로 이해할수도 있겠다는 생각이 들었습니다.
출처 : https://arxiv.org/abs/2304.12244
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Training large language models (LLMs) with open-domain instruction following data brings colossal success. However, manually creating such instruction data is very time-consuming and labor-intensive. Moreover, humans may struggle to produce high-complexity
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.04)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft]
대량의 instruction data를 생성하는 방법론 Evol-Instruct을 제시.
이를 이용해 생성한 데이터셋으로 fine-tuning한 모델 WizardLM이 Alpaca, Vicuna를 압도.
- 배경
LLM이 instruction data를 활용하는 경우, 그 성능이 눈에 띄게 좋아진다는 것은 잘 알려져 있습니다.
우리에게 익숙한 ChatGPT도 이를 적극적으로 잘 활용하여 학습된 모델이죠.
예전에는 instruction data라고 해봤자, 특정 도메인에 한정되고(closed-domain) 아주 간단한 수준의 태스크만 다루었고,
이를 엄청난 자본과 인력으로 커버한 대표적인 기업이 OpenAI죠.
수많은 annotator를 고용하여 만든 데이터셋으로 학습된 모델이 세상에 알려지게 되었습니다.
하지만 이러한 방식은 너무나도 많은 자원과 시간을 요하기에 앞으로의 발전을 꾀하기에는 어려움이 있습니다.
본 논문에서는 이를 인지하고 고품질이면서도 다양성을 갖춘 instruction data를 언어 모델을 통해 생성하는 전략을 제시합니다.
- 특징
1) seed dataset
위에서 언급한 바와 같이, 예전에는 open-domain instruction의 성격이 강했습니다.
이와 달리 open-domain intruction dataset을 만드는 것을 목표로 하고 있는데, 여기에는 인터넷 상의 무수히 많은 데이터들을 이용하는 것이 중요합니다.
본 연구에서는 alpaca를 학습하는데 사용된 50k instruction과, vicuna를 학습하는데 사용된 70k instruction(from ShareGPT)를 시드로 삼습니다.
2) Three steps: instruction evolving, response generation, elimination evolving
2-1) instruction evolving
in-depth evolving과 in-breadth evolving으로 나뉩니다.
더 복잡하고 어려운 문장을 생성하도록 유도하는 in-depth evolving에는 'add constraints, deepening, concretizing, increased reasoning steps, complicating input' 다섯 가지 방식이 포함됩니다.
한편 in-breadth는 더 다양하고 많은 주제를 다룰 수 있도록 유도하는 방식을 말합니다.
따라서 총 6개의 방법론이 매 단계에서 random하게 적용된다는 것으로 이해할 수 있습니다.
2-2) response generation
LLM을 이용하여 주어진 instruction에 대한 response를 생성합니다.
2-3) elimination evoling
다음과 같은 조건에 해당하는 instruction은 삭제합니다.
1. 기존의 instruction과 비교했을 때, 추가적인 정보를 제공하지 않는 경우
2. LLM이 response를 생성하기 어려워하는 instruction인 경우(sorry 등으로 답하는 경우)
3. LLM이 구두점과 불용어로만 reponse를 생성하는 경우
4. given prompt와 같은 시스템 메세지를 반환하는 경우
위 과정을 반복적으로 수행하여 수행 난이도는 높고 다양한 주제를 다룰 수 있는 instruciton dataset를 생성할 수 있습니다.
3) evaluation
Evol-Instruct로 학습한 모델은 WizardLM입니다.
이를 Alpaca, Vicuna, ChatGPT와 비교했습니다.
성능을 측정할 때는 Evol-Instruct의 testset과 Vicuna testset을 활용했습니다.
위 결과에서 볼 수 있는 것처럼, 두 testset에 대해서 WizardLM은 Alpaca, Vicuna에 비해 사람에거 더욱 선호되는 경향이 있고, ChatGPT에는 조금 못미치는 성능을 나타내고 있습니다.
특히 Evol-Instruct testset에서 난이도가 높은 것들에 대해서는 WizardLM이 ChatGPT보다 우월한 성능을 보여주었다는 것이 주목할만한 특징입니다.
이는 (Vicuna에서 도입했던 방식) 'GPT-4를 평가자'로 썼을 때의 결과와 동일합니다.
- 개인적 감상
날이 갈수록 고품질 데이터셋을 만드는 것(확보하는 것)의 중요성이 커지고 있는데,
이런 방법을 제안한 논문을 모르고 있었다는 것이 신기했습니다.
Instruction Dataset이 아니더라도 다양한 방식으로 LLM을 활용하여 데이터셋을 제작하고,
이를 학습 데이터로 이용하는 연구들이 많습니다.
개인적으로는 LIMA라는 논문이 가장 기억에 남는데 이런 식으로 고품질 데이터셋을 목적에 맞게끔 제작해보는 것도 좋은 경험이 될 것 같습니다.
다만 GPT-4와 Human annotator간 평가에서 차이가 존재한다는 점이 아쉽게 다가옵니다.
사실 인간에 가깝게, 인간에게 가장 선호되게끔 학습한 모델이 주목을 받고 성능이 좋은 것으로 인식되는데,
어찌보면 align이 잘 되지 않은 것으로 이해할수도 있겠다는 생각이 들었습니다.
출처 : https://arxiv.org/abs/2304.12244
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Training large language models (LLMs) with open-domain instruction following data brings colossal success. However, manually creating such instruction data is very time-consuming and labor-intensive. Moreover, humans may struggle to produce high-complexity
arxiv.org