
이 글은 최근(2023.08)에 나온 논문의 요약본을 ChatGPT로 번역한 것입니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
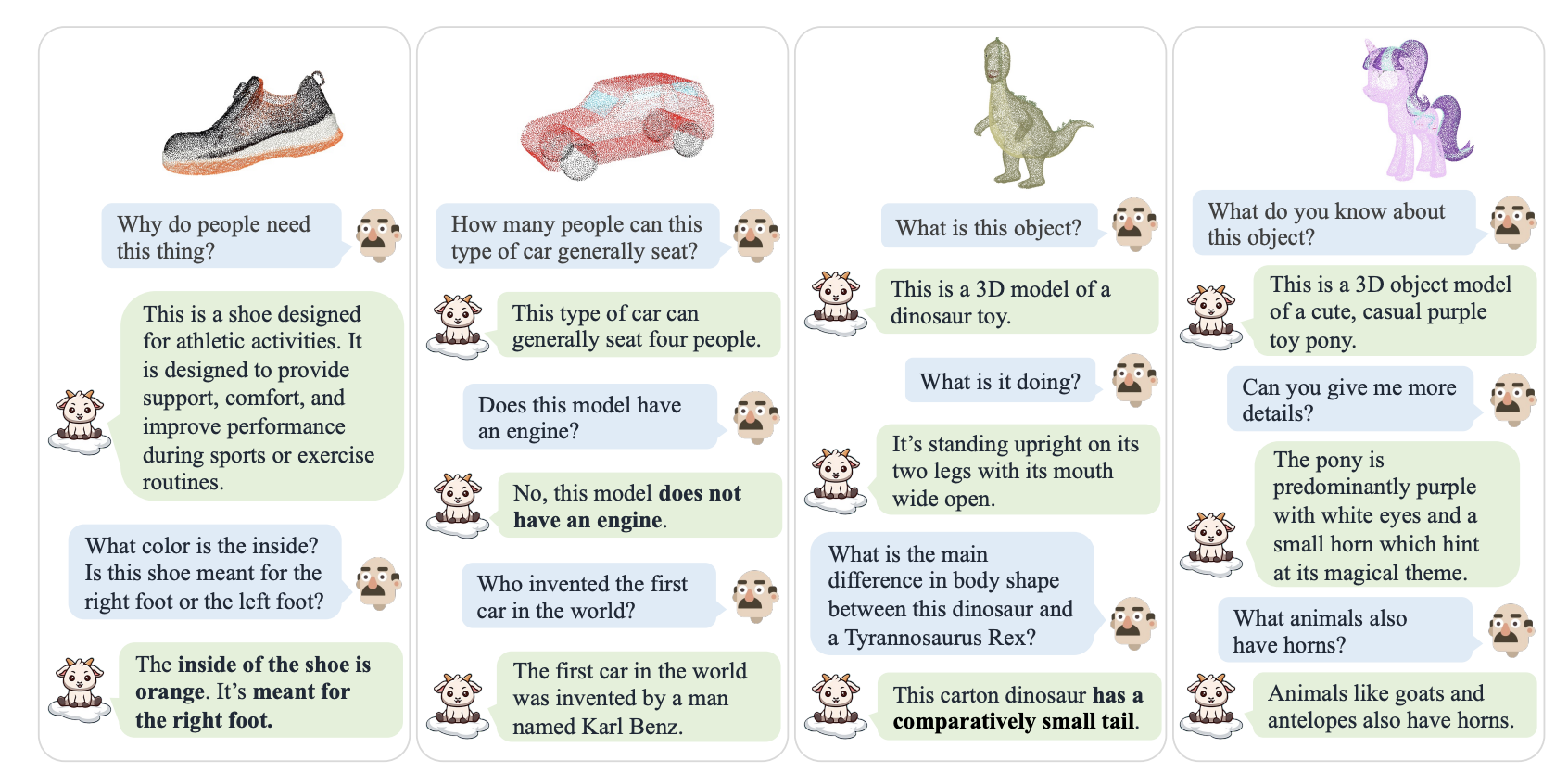
개요
이 논문은 대형 언어 모델(Large Language Models, LLMs)이 3D 포인트 클라우드를 이해할 수 있도록 확장하는 새로운 연구 방향을 제시합니다.
이로써, 2D 시각 데이터 이상의 새로운 연구 영역이 열립니다.
중심 문제
기존의 대형 언어 모델은 자연어 처리에는 능숙하지만, 3D 구조를 이해하는 능력은 부족합니다.
2D 이미지를 위한 LVLMs는 활발히 연구되고 있지만, 3D로 확장되지 않습니다.
이러한 한계는 3D 환경에서의 객체 인식 및 상호 작용과 같은 작업에 그 응용을 제한합니다.
또한, 3D와 텍스트가 쌍을 이루는 대규모 데이터셋이 없습니다.
제안된 해결책
저자들은 두 단계의 훈련 전략을 가능하게 하기 위해 660K의 단순한 포인트-텍스트 지침 쌍과 70K의 복잡한 지침 쌍으로 구성된 새로운 데이터셋을 수집했습니다.
모델의 지각 능력과 일반화 능력을 엄격하게 평가하기 위해, 두 가지 벤치마크를 설정했습니다: 생성적 3D 객체 분류와 3D 객체 캡션, 세 가지 다른 평가 방법을 통해 평가되었습니다.
사용된 방법론
데이터 수집
저자들은 Cap3D를 이용하여 Objaverse에서 3D 객체의 캡션을 생성, 660K의 간단한 설명 지침 데이터를 결과로 얻었습니다.
간단한 설명 이외에도, Cap3D는 GPT-4를 활성화하여 상세한 대화를 생성하도록 하였습니다.
필터링을 통해, 70K의 복잡한 지침 샘플을 수집하였습니다.
모델 아키텍처 & 훈련
포인트 클라우드 인코더로는 Point-BERT가 사용되었으며, Objaverse 데이터셋에서 ULIP-2 목표로 사전 훈련되었습니다.
기반으로 사용되는 LLM은 LLaMa이며, 이에는 7B와 13B의 Vicuna 체크포인트가 있습니다.
포인트 클라우드 인코더와 LLM은 잠재 공간에서 정렬되며, 이는 두 단계 훈련 전략의 일부입니다.
두 번째 훈련 단계에서는, 포인트 클라우드 인코더는 고정되고 선형 투사기와 LLM이 공동으로 훈련됩니다.
결과
PointLLM은 기존의 2D 기준인 Instruct-BLIP에 비해 훨씬 더 높은 성능을 보입니다.
인간이 평가한 객체 캡션 작업에서는 50% 이상의 샘플에서 인간 주석자보다 더 나은 성능을 보였습니다.
저자들은 추가로 두 가지 벤치마크를 설정했습니다:
1) 생성적 3D 객체 분류를 위한 폐쇄 집합 제로샷 설정,
2) 3D 객체 캡션.
이러한 벤치마크에는 인간과 LLMs로부터의 평가뿐만 아니라 전통적인 지표도 포함되어 있습니다.
이렇게 함으로써, PointLLM은 3D 환경에서의 언어 모델의 가능성을 크게 확장하는 중요한 한 걸음을 내딛게 됩니다.
출처 : https://arxiv.org/abs/2308.16911
PointLLM: Empowering Large Language Models to Understand Point Clouds
The unprecedented advancements in Large Language Models (LLMs) have created a profound impact on natural language processing but are yet to fully embrace the realm of 3D understanding. This paper introduces PointLLM, a preliminary effort to fill this gap,
arxiv.org
'Paper Review' 카테고리의 다른 글
이 글은 최근(2023.08)에 나온 논문의 요약본을 ChatGPT로 번역한 것입니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
개요
이 논문은 대형 언어 모델(Large Language Models, LLMs)이 3D 포인트 클라우드를 이해할 수 있도록 확장하는 새로운 연구 방향을 제시합니다.
이로써, 2D 시각 데이터 이상의 새로운 연구 영역이 열립니다.
중심 문제
기존의 대형 언어 모델은 자연어 처리에는 능숙하지만, 3D 구조를 이해하는 능력은 부족합니다.
2D 이미지를 위한 LVLMs는 활발히 연구되고 있지만, 3D로 확장되지 않습니다.
이러한 한계는 3D 환경에서의 객체 인식 및 상호 작용과 같은 작업에 그 응용을 제한합니다.
또한, 3D와 텍스트가 쌍을 이루는 대규모 데이터셋이 없습니다.
제안된 해결책
저자들은 두 단계의 훈련 전략을 가능하게 하기 위해 660K의 단순한 포인트-텍스트 지침 쌍과 70K의 복잡한 지침 쌍으로 구성된 새로운 데이터셋을 수집했습니다.
모델의 지각 능력과 일반화 능력을 엄격하게 평가하기 위해, 두 가지 벤치마크를 설정했습니다: 생성적 3D 객체 분류와 3D 객체 캡션, 세 가지 다른 평가 방법을 통해 평가되었습니다.
사용된 방법론
데이터 수집
저자들은 Cap3D를 이용하여 Objaverse에서 3D 객체의 캡션을 생성, 660K의 간단한 설명 지침 데이터를 결과로 얻었습니다.
간단한 설명 이외에도, Cap3D는 GPT-4를 활성화하여 상세한 대화를 생성하도록 하였습니다.
필터링을 통해, 70K의 복잡한 지침 샘플을 수집하였습니다.
모델 아키텍처 & 훈련
포인트 클라우드 인코더로는 Point-BERT가 사용되었으며, Objaverse 데이터셋에서 ULIP-2 목표로 사전 훈련되었습니다.
기반으로 사용되는 LLM은 LLaMa이며, 이에는 7B와 13B의 Vicuna 체크포인트가 있습니다.
포인트 클라우드 인코더와 LLM은 잠재 공간에서 정렬되며, 이는 두 단계 훈련 전략의 일부입니다.
두 번째 훈련 단계에서는, 포인트 클라우드 인코더는 고정되고 선형 투사기와 LLM이 공동으로 훈련됩니다.
결과
PointLLM은 기존의 2D 기준인 Instruct-BLIP에 비해 훨씬 더 높은 성능을 보입니다.
인간이 평가한 객체 캡션 작업에서는 50% 이상의 샘플에서 인간 주석자보다 더 나은 성능을 보였습니다.
저자들은 추가로 두 가지 벤치마크를 설정했습니다:
1) 생성적 3D 객체 분류를 위한 폐쇄 집합 제로샷 설정,
2) 3D 객체 캡션.
이러한 벤치마크에는 인간과 LLMs로부터의 평가뿐만 아니라 전통적인 지표도 포함되어 있습니다.
이렇게 함으로써, PointLLM은 3D 환경에서의 언어 모델의 가능성을 크게 확장하는 중요한 한 걸음을 내딛게 됩니다.
출처 : https://arxiv.org/abs/2308.16911
PointLLM: Empowering Large Language Models to Understand Point Clouds
The unprecedented advancements in Large Language Models (LLMs) have created a profound impact on natural language processing but are yet to fully embrace the realm of 3D understanding. This paper introduces PointLLM, a preliminary effort to fill this gap,
arxiv.org