
최근(2023.03)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research / Azure AI]
DeBERTa의 MLM을 RTD로 대체하고, 새로운 gradient-disentangled embedding sharing 방식을 적용.
multilingual 모델 mDeBERTaV3도 개발.
- 배경
지난 번에 소개한 모델 DeBERTa는 relative position을 더 잘 반영하는 disentangled attention과 absolute position을 반영하는 enhanced mask decoder(EMD)을 주요 특징으로 내세웠습니다.
본 논문에서 DeBERTa는 기존에 널리 사용되던 PLM(Pretrained Language Model), BERT의 사전 학습 방식인 MLM(Masked Language Modeling)을 취했는데, 이를 ELECTRA의 사전 학습 방식인 RTD(Replaced Token Detection)로 대체했습니다.
ELECTRA는 마치 GAN(Generative Adversarial Network)처럼 Generator(생성자)와 Discriminator(판별자)가 대립하는 구도로 사전학습 하게 됩니다.
그런데 본 논문에서는 generator와 discriminator는 embedding을 share하는데, 둘의 objective가 서로 반대이므로 이것이 효율적이지 않다고 지적합니다.
generator는 보다 ambiguous한 corruption을 만들기 위해 원래의 입력과 '유사도가 높은' token을 꺼내오도록 학습되고,
discriminator는 특정 토큰이 원래의 것인지 ambiguuous corruption인지 맞히는 이진 분류를 하도록 학습되기 때문에 다르다는 것입니다.
그래서 DeBERTaV3는 ELECTRA의 사전 학습 방식인 RTD를 새롭게 개선한 방식(GDES, Graident-Disentangled Embedding Sharing)을 사용하여 모델을 사전 학습 합니다.
- 특징
논문에서 설명되는 내용을 이해하기 위해 미리 알고 있으면 좋은 지식들이 여럿 있습니다.
구체적인 수식과 설명은 논문에 나와 있으니 이를 참고하시기 바랍니다.
아주 간단히 MLM(Masked Language Modeling)과 RTD(Replaced Token Detection)에 대해서만 설명하겠습니다.
MLM은 대량의 텍스트 데이터를 학습할 때, 따로 label을 annotation하지 않고도 바로 학습 가능한 방식입니다.
주어진 입력의 일부(15%)를 마스크로 가리고, 이것이 원래 무슨 토큰인지 예측하도록 하는 방식입니다.
이와 달리 RTD는 generator(생성자)와 discriminator(판별자)라는 개념을 사용합니다.
둘은 각각 '기존과 유사한 토큰으로 변형하기'와 '원래 토큰이 맞는지 확인하기'의 임무를 수행합니다.
대표적인 비유로 '위조 지폐를 만드는 범죄자'와 '이를 탐지하는 경찰'의 관계를 들 수 있습니다.
이 과정을 반복함으로써 모델은 입력에 대한 폭넓은 이해를 갖게 됩니다.
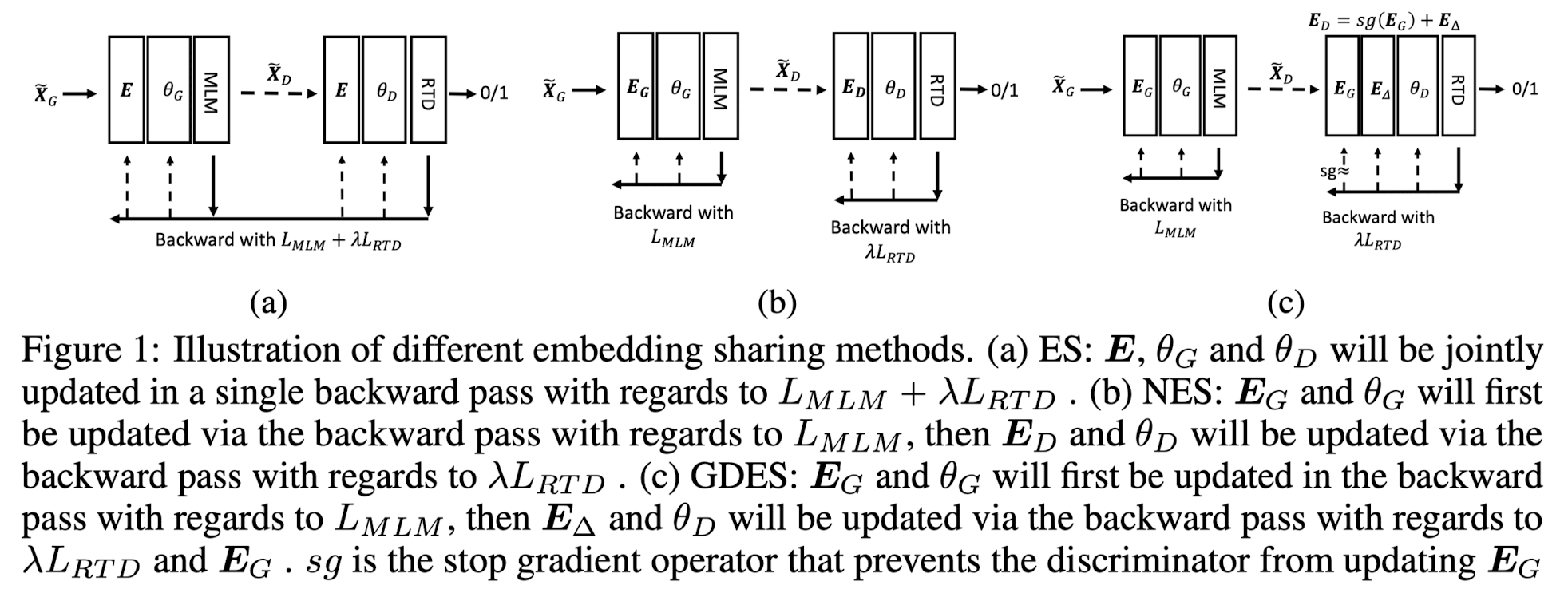
가장 핵심적인 내용인 Token Embedding에 대해 알아보겠습니다.
기존 ELECTRA에서 generator는 MLM을, discriminator는 RTD을 학습 기법으로 사용합니다.
그리고 둘은 같은 token embedding을 공유합니다.
즉, 어떤 입력이 들어왔을 때, 이를 벡터로 변환하는 임베딩 공간이 동일하다는 뜻입니다.
그리고 'MLM embedding에서의 loss'와 'RTD embedding에서의 loss에 가중치를 곱한 것'을 전체 loss로 정의합니다.
하지만 이런 방식은 위에서 언급한 것처럼 objective가 서로 다른 상황에 부적합한 방식이라는 것입니다.
이를 Embedding Sharing, ES라고 부릅니다.
이를 개선하기 위해 generator와 discriminator가 각각 다른 loss로 업데이트 되는 방식을 No Embedding Sharing(NES)라고 합니다.
즉, 각각 loss를 구해 각각 업데이트 되기 때문에 서로 영향을 주지도 않고, 처리 속도도 굉장히 빠릅니다.
결과적으로 두 개의 embedding model을 생성함으로써 ES 대비 훨씬 빠르게 학습하게 되는데, 성능적으로는 뚜렷한 개선이 없습니다.
이 둘의 장점을 취한 방식으로 제안된 것이 Gradient-Disentangled Embedding Sharing(GDES)입니다.
GDES는 generator와 discriminator가 embedding을 공유하기 때문에 두 모델이 동일한 토큰에 대해 풍부한 semantic information을 추출할 수 있게 됩니다.
하지만 GDES는 generator가 RTD loss의 개입 없이 MLM loss로만 업데이트되도록 함으로써 generator의 output이 일관성과 통일성을 유지할 수 있도록 합니다.
그리고 이 덕분에 converging 속도도 NES만큼이나 빠릅니다.
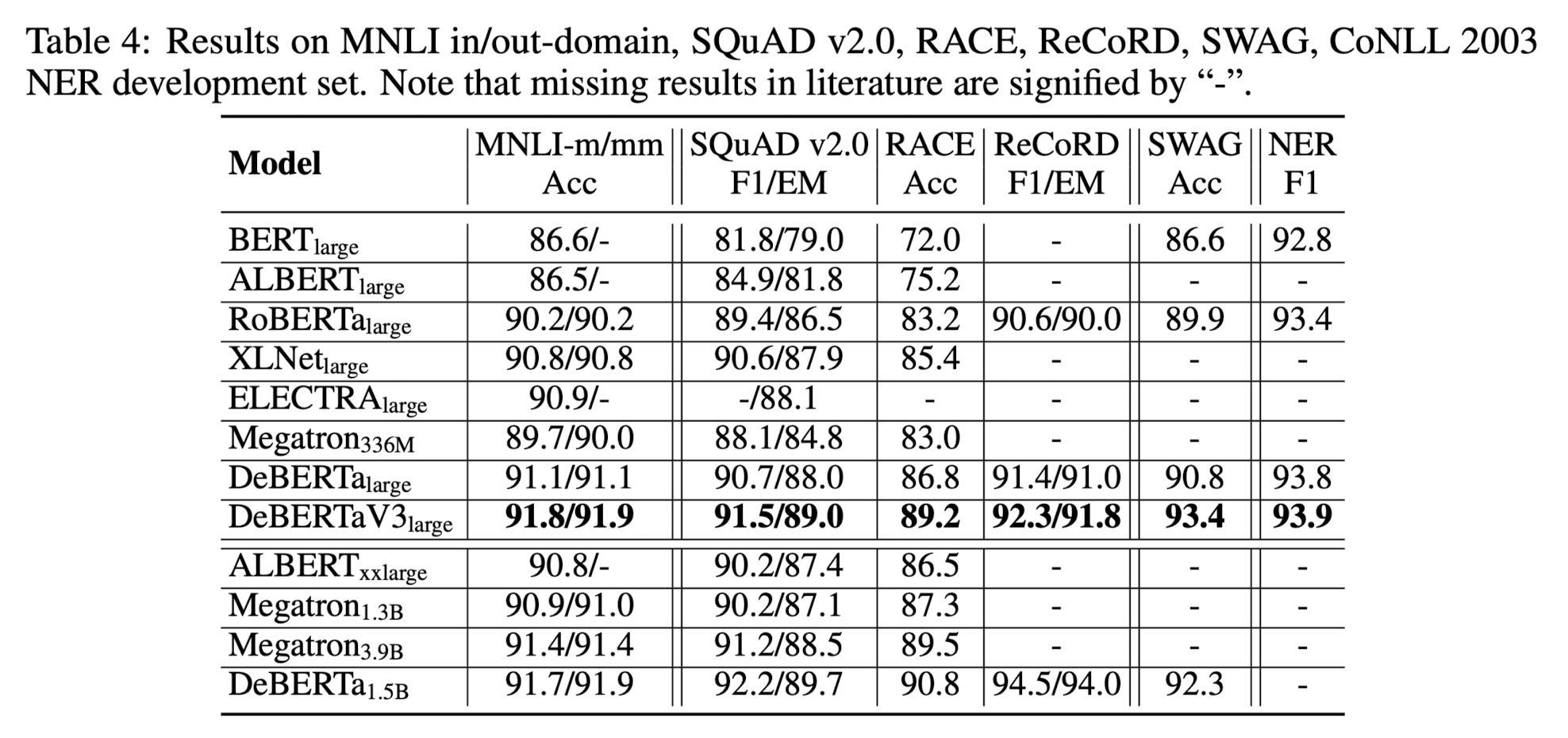
위의 표 외에도 다양한 실험 결과가 제시되어 있으니 궁금하신 분들은 논문을 직접 참고하시기 바랍니다.
마지막으로 하나만 더 언급하고 넘어가면 multi-lingual model, mDeBERTaV3 입니다.
XLM-R 모델이 학습할 때 사용한 2.5T CC100 multi-lingual dataset을 사용해서 학습했다고 언급되어 있는데,
multi-lingual 벤치마크에서 좋은 성능을 보였음이 확인됩니다.
따라서 이러한 학습 방식이 심지어 다국어에 대한 학습에 있어서도 유의미한 성능 향상으로 이어진다고 볼 수 있습니다.
- 개인적 감상
예전에 공부할 때 ELECTRA에 대해서도 본 적이 있는데, 그 내용을 지금에 와서 잘 이해할 수 있게 된 것 같습니다.
요즘에는 뭔가 사전학습하는 방식을 크게 바꾸는 모델이 주목을 받지 못하는 것 같은데,
이런 테크니컬한 변화가 눈에 띄는 성능 향상으로 이어졌다는 것이 참 흥미로운 것 같습니다.
하지만 이것 역시 개인적으로(논문에 대해서가 아니라) 조금 아쉬운 것은 수식과 코드에 대한 이해 부족입니다.
loss에 대한 정의가 어떤 것을 의미하는지 명확히 이해되지 않았고,
또한 GDES 방식이 코드로 어떻게 구현되었는지 확인하지 못한 상태라서 이해도가 부족한 듯 합니다.
결국 이해한 내용을 코드로 풀어내는 것은 별개의 노력을 필요로 하는 일이라서 빨리 공부하고 싶다는 생각이 들게 만드는 논문이었던 것 같습니다.
출처 : https://arxiv.org/abs/2111.09543
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
This paper presents a new pre-trained language model, DeBERTaV3, which improves the original DeBERTa model by replacing mask language modeling (MLM) with replaced token detection (RTD), a more sample-efficient pre-training task. Our analysis shows that van
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.03)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Microsoft Research / Azure AI]
DeBERTa의 MLM을 RTD로 대체하고, 새로운 gradient-disentangled embedding sharing 방식을 적용.
multilingual 모델 mDeBERTaV3도 개발.
- 배경
지난 번에 소개한 모델 DeBERTa는 relative position을 더 잘 반영하는 disentangled attention과 absolute position을 반영하는 enhanced mask decoder(EMD)을 주요 특징으로 내세웠습니다.
본 논문에서 DeBERTa는 기존에 널리 사용되던 PLM(Pretrained Language Model), BERT의 사전 학습 방식인 MLM(Masked Language Modeling)을 취했는데, 이를 ELECTRA의 사전 학습 방식인 RTD(Replaced Token Detection)로 대체했습니다.
ELECTRA는 마치 GAN(Generative Adversarial Network)처럼 Generator(생성자)와 Discriminator(판별자)가 대립하는 구도로 사전학습 하게 됩니다.
그런데 본 논문에서는 generator와 discriminator는 embedding을 share하는데, 둘의 objective가 서로 반대이므로 이것이 효율적이지 않다고 지적합니다.
generator는 보다 ambiguous한 corruption을 만들기 위해 원래의 입력과 '유사도가 높은' token을 꺼내오도록 학습되고,
discriminator는 특정 토큰이 원래의 것인지 ambiguuous corruption인지 맞히는 이진 분류를 하도록 학습되기 때문에 다르다는 것입니다.
그래서 DeBERTaV3는 ELECTRA의 사전 학습 방식인 RTD를 새롭게 개선한 방식(GDES, Graident-Disentangled Embedding Sharing)을 사용하여 모델을 사전 학습 합니다.
- 특징
논문에서 설명되는 내용을 이해하기 위해 미리 알고 있으면 좋은 지식들이 여럿 있습니다.
구체적인 수식과 설명은 논문에 나와 있으니 이를 참고하시기 바랍니다.
아주 간단히 MLM(Masked Language Modeling)과 RTD(Replaced Token Detection)에 대해서만 설명하겠습니다.
MLM은 대량의 텍스트 데이터를 학습할 때, 따로 label을 annotation하지 않고도 바로 학습 가능한 방식입니다.
주어진 입력의 일부(15%)를 마스크로 가리고, 이것이 원래 무슨 토큰인지 예측하도록 하는 방식입니다.
이와 달리 RTD는 generator(생성자)와 discriminator(판별자)라는 개념을 사용합니다.
둘은 각각 '기존과 유사한 토큰으로 변형하기'와 '원래 토큰이 맞는지 확인하기'의 임무를 수행합니다.
대표적인 비유로 '위조 지폐를 만드는 범죄자'와 '이를 탐지하는 경찰'의 관계를 들 수 있습니다.
이 과정을 반복함으로써 모델은 입력에 대한 폭넓은 이해를 갖게 됩니다.
가장 핵심적인 내용인 Token Embedding에 대해 알아보겠습니다.
기존 ELECTRA에서 generator는 MLM을, discriminator는 RTD을 학습 기법으로 사용합니다.
그리고 둘은 같은 token embedding을 공유합니다.
즉, 어떤 입력이 들어왔을 때, 이를 벡터로 변환하는 임베딩 공간이 동일하다는 뜻입니다.
그리고 'MLM embedding에서의 loss'와 'RTD embedding에서의 loss에 가중치를 곱한 것'을 전체 loss로 정의합니다.
하지만 이런 방식은 위에서 언급한 것처럼 objective가 서로 다른 상황에 부적합한 방식이라는 것입니다.
이를 Embedding Sharing, ES라고 부릅니다.
이를 개선하기 위해 generator와 discriminator가 각각 다른 loss로 업데이트 되는 방식을 No Embedding Sharing(NES)라고 합니다.
즉, 각각 loss를 구해 각각 업데이트 되기 때문에 서로 영향을 주지도 않고, 처리 속도도 굉장히 빠릅니다.
결과적으로 두 개의 embedding model을 생성함으로써 ES 대비 훨씬 빠르게 학습하게 되는데, 성능적으로는 뚜렷한 개선이 없습니다.
이 둘의 장점을 취한 방식으로 제안된 것이 Gradient-Disentangled Embedding Sharing(GDES)입니다.
GDES는 generator와 discriminator가 embedding을 공유하기 때문에 두 모델이 동일한 토큰에 대해 풍부한 semantic information을 추출할 수 있게 됩니다.
하지만 GDES는 generator가 RTD loss의 개입 없이 MLM loss로만 업데이트되도록 함으로써 generator의 output이 일관성과 통일성을 유지할 수 있도록 합니다.
그리고 이 덕분에 converging 속도도 NES만큼이나 빠릅니다.
위의 표 외에도 다양한 실험 결과가 제시되어 있으니 궁금하신 분들은 논문을 직접 참고하시기 바랍니다.
마지막으로 하나만 더 언급하고 넘어가면 multi-lingual model, mDeBERTaV3 입니다.
XLM-R 모델이 학습할 때 사용한 2.5T CC100 multi-lingual dataset을 사용해서 학습했다고 언급되어 있는데,
multi-lingual 벤치마크에서 좋은 성능을 보였음이 확인됩니다.
따라서 이러한 학습 방식이 심지어 다국어에 대한 학습에 있어서도 유의미한 성능 향상으로 이어진다고 볼 수 있습니다.
- 개인적 감상
예전에 공부할 때 ELECTRA에 대해서도 본 적이 있는데, 그 내용을 지금에 와서 잘 이해할 수 있게 된 것 같습니다.
요즘에는 뭔가 사전학습하는 방식을 크게 바꾸는 모델이 주목을 받지 못하는 것 같은데,
이런 테크니컬한 변화가 눈에 띄는 성능 향상으로 이어졌다는 것이 참 흥미로운 것 같습니다.
하지만 이것 역시 개인적으로(논문에 대해서가 아니라) 조금 아쉬운 것은 수식과 코드에 대한 이해 부족입니다.
loss에 대한 정의가 어떤 것을 의미하는지 명확히 이해되지 않았고,
또한 GDES 방식이 코드로 어떻게 구현되었는지 확인하지 못한 상태라서 이해도가 부족한 듯 합니다.
결국 이해한 내용을 코드로 풀어내는 것은 별개의 노력을 필요로 하는 일이라서 빨리 공부하고 싶다는 생각이 들게 만드는 논문이었던 것 같습니다.
출처 : https://arxiv.org/abs/2111.09543
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
This paper presents a new pre-trained language model, DeBERTaV3, which improves the original DeBERTa model by replacing mask language modeling (MLM) with replaced token detection (RTD), a more sample-efficient pre-training task. Our analysis shows that van
arxiv.org