최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
LLM에 대해 Prompting 기술을 활용하여 Optimization 하는 OPRO를 제안.
Linear Regression, Traveling Salesman Problem / GSM8K, Big-Bench Hard Task
- 배경
원래 optimization, 최적화라고 하면 주어진 문제를 풀기 위해 정의된 objective fuction에 대한 최적화를 뜻합니다.
목표로 설정한 함수를 최적화하는 것은 solution을 반복적으로 업데이트함으로써 달성됩니다.
지금까지는 어떤 방식으로 solution 업데이트할지에 대한 알고리즘들이 잘 알려져 있고 이를 활용하여 최적화가 진행되었습니다.
(예를 들어 Stochastic Gradienct Descent, Adam 등)
본 논문에서는 LLM의 general한 능력을 바탕으로 이를 optimizer로 활용하는 방법을 제안하고 있습니다.
지금 단계에서 이 방법론의 궁극적인 목표는 기존 알고리즘 기반의 optimizer들을 대체하거나 넘어서는 수준을 달성하는 것이 아니라,
주어진 목표(objective)가 있을 때, 알고리즘이 아닌 자연어(Natural Language)로 최적화가 가능하다는 것을 보여주는 것입니다.
따라서 아주 간단한 예제인 Linear Regression & Traveling Salesman Problem과 같은 알고리즘에 대한 최적화 성능과,
모델이 처리하기에 난이도가 아주 높은 것으로 알려진 두 Reasoning Task, GSM8K & BBH에 대한 최적화 성능을 확인합니다.
- 특징
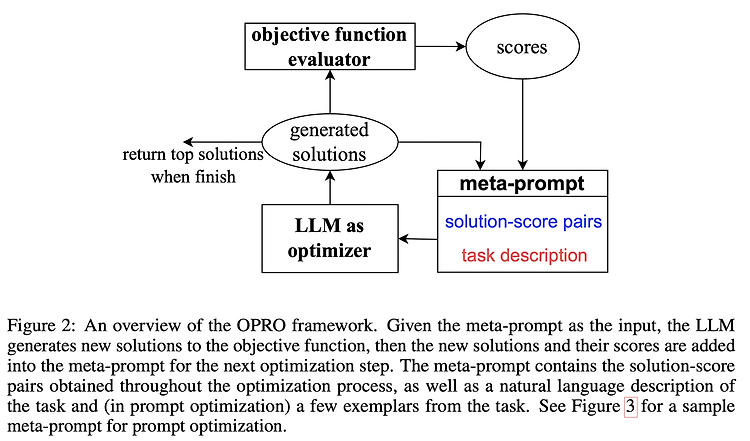
전체적인 구조는 생각보다 단순합니다.
- meta-prompt : 'solution-score 쌍'과 'task description'으로 구성됩니다.
- LLM as optimizer : meta-prompt를 입력으로 받아 새로운 solution을 생성합니다.(generated solutions)
- objective function evaluator : generated solution을 평가하여 score를 구합니다. 이때 평가자는 optimizer와는 다른 별개의 LLM입니다.
- score : evaluator를 통해 획득한 score를 generated solution과 쌍으로 묶어 meta-prompt로 만들고 과정을 반복합니다.
- 종료 시점은 더이상 높은 점수의 solution을 생성할 수 없거나 정해놓은 최적화 횟수 최대치에 다다랐을 때입니다.
Trading off exploration and exploitation
이미 어느 정도 괜찮은 solution이 발견된 상태에서는 exploration과 exploitation 둘 중 하나에 가중치를 더 주어야 합니다.
즉 cost를 더 들여서 남은 solution space를 탐색해 기존보다 더 좋은 solution을 찾을 것인지(exploration),
아니면 기존 solution을 그대로 이용할 것인지(exploitation)를 결정하게 됩니다.
이것이 optimization의 핵심이기 때문에, LLM은 이를 적절히 조절하고 판단할 수 있는 능력이 필요합니다.
Optimization trajectory
LLM은 in-context demonstration에서 패턴을 인지하고 학습할 수 있는 것으로 알려져 있습니다.
따라서 새로운 solution을 생성하기 위해 이전의 optimization 기록들을 input으로 제공합니다.
위 구성 요소 중 solution-score pair가 여기에 해당합니다.
Instruction Positions
- Q_begin : original question 앞에 instruction을 붙이는 경우
- Q_end : original question 뒤에 instruction을 붙이는 경우
- A_begin : scorer LLM의 output 시작에 insturction을 붙이는 경우. instruction tuning 없이 QA 형태의 sequence에도 붙을 수 있음
instruction을 어느 위치에 삽입하는지에 따라 성능이 다른지에 대한 실험 결과도 존재합니다.

같은 모델을 사용하더라도 instruction이 삽입된 위치에 따라 다른 결과물이 나온다는 것을 알 수 있습니다.
위 실험 결과(BBH, 난이도가 아주 높은 reasoning benchmark) 외에도 다양한 성능 평가에 instruction 위치별 비교 결과가 포함됩니다.
결과적으로 instruction 위치에 따른 성능 변화는 큰 의미가 없습니다.
같은 맥락에서 가장 높은 성능을 보인 scorer(평가자) LLM과 학습을 진행하는 optimizer LLM도 실험 결과에 정리되어 있습니다.
QA pair가 없는 instruction을 사용할 때도 있어 다양한 상황이 존재하므로 논문 내용을 직접 확인해보시길 권장드립니다.
- 개인적 감상
솔직 담백한 논문이라는 생각이 들었습니다.
사실 지금까지 여러 논문들이 자신들의 아이디어를 제시할 때, 특정 태스크나 상황에서 다른 모델들에 비해 우월한 성능을 보여주기 바쁜 것에 비해, 이러한 기법을 적용하는 것의 목적과 한계를 명확히 밝혔다는 것이 더 설득력 있는 서술 방식이라고 느껴졌습니다.
어찌 보면 굉장히 간단한 태스크에 속하는 logistic regression에 대해서도 결국 기존 알고리즘을 대체할 만큼의 성능을 아직 보이지는 못했지만, LLM으로 optimizing을 한다는 것 자체가 굉장히 신선하게 느껴졌습니다.
대신 구체적으로 어떤 동작 원리를 가지는지에 대해서는 면밀히 살펴볼 필요가 있는 것 같습니다.
scorer와 optimizer에 대해 LLM을 각각 사용한다고 보면 결국 LLM을 tuning하는 것으로 보이지는 않기 때문입니다.
더욱 정교한 instruction을 만들고 발전해나가는 것으로 이해되긴 하지만, 실질적으로 parameter update가 일어나지 않는 것처럼 보입니다.
(줄여야하는 loss가 명시되어 있지 않습니다. 이를 학습이라고 볼 수 있을까요?)
출처 : https://arxiv.org/abs/2309.03409
Large Language Models as Optimizers
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google DeepMind]
LLM에 대해 Prompting 기술을 활용하여 Optimization 하는 OPRO를 제안.
Linear Regression, Traveling Salesman Problem / GSM8K, Big-Bench Hard Task
- 배경
원래 optimization, 최적화라고 하면 주어진 문제를 풀기 위해 정의된 objective fuction에 대한 최적화를 뜻합니다.
목표로 설정한 함수를 최적화하는 것은 solution을 반복적으로 업데이트함으로써 달성됩니다.
지금까지는 어떤 방식으로 solution 업데이트할지에 대한 알고리즘들이 잘 알려져 있고 이를 활용하여 최적화가 진행되었습니다.
(예를 들어 Stochastic Gradienct Descent, Adam 등)
본 논문에서는 LLM의 general한 능력을 바탕으로 이를 optimizer로 활용하는 방법을 제안하고 있습니다.
지금 단계에서 이 방법론의 궁극적인 목표는 기존 알고리즘 기반의 optimizer들을 대체하거나 넘어서는 수준을 달성하는 것이 아니라,
주어진 목표(objective)가 있을 때, 알고리즘이 아닌 자연어(Natural Language)로 최적화가 가능하다는 것을 보여주는 것입니다.
따라서 아주 간단한 예제인 Linear Regression & Traveling Salesman Problem과 같은 알고리즘에 대한 최적화 성능과,
모델이 처리하기에 난이도가 아주 높은 것으로 알려진 두 Reasoning Task, GSM8K & BBH에 대한 최적화 성능을 확인합니다.
- 특징
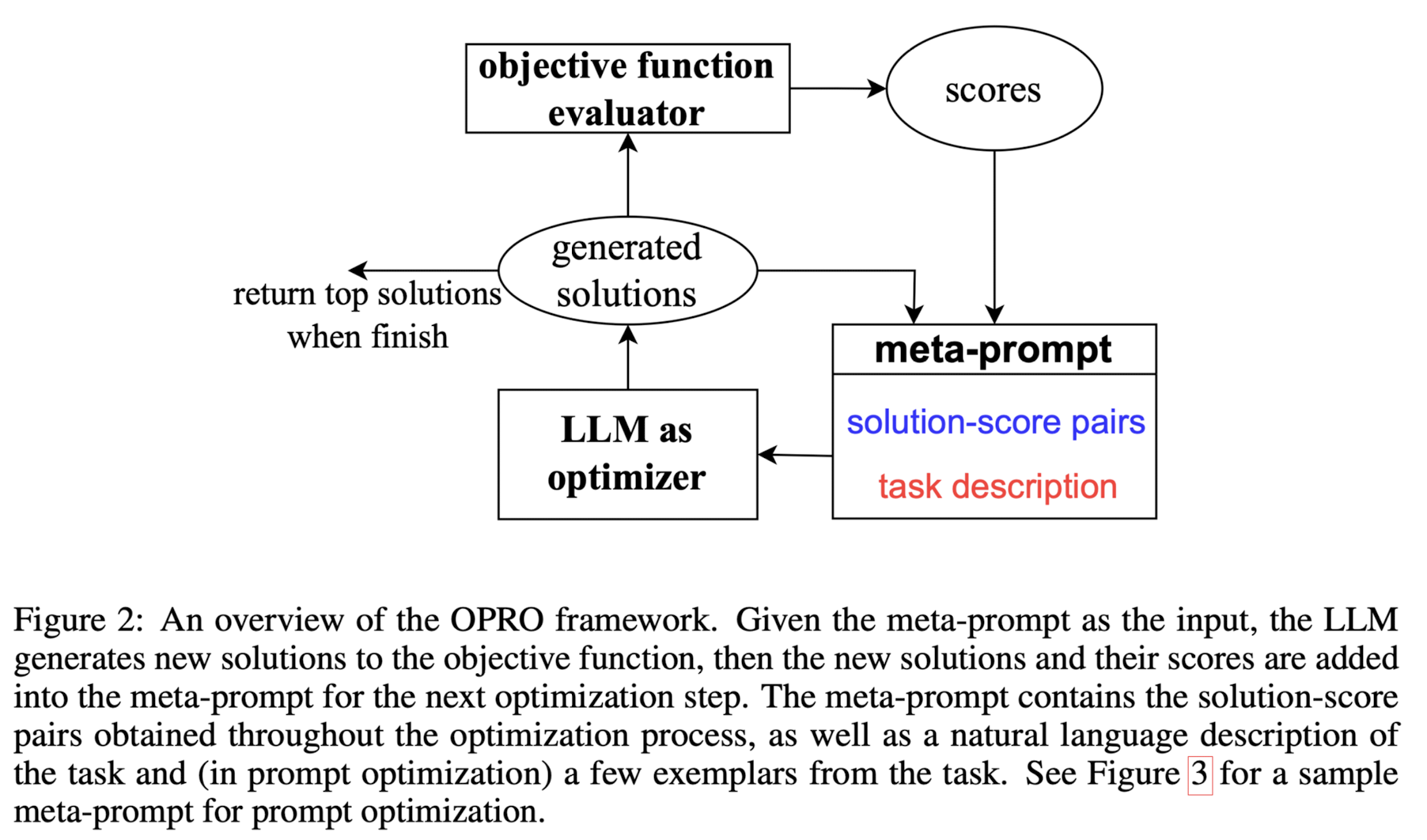
전체적인 구조는 생각보다 단순합니다.
- meta-prompt : 'solution-score 쌍'과 'task description'으로 구성됩니다.
- LLM as optimizer : meta-prompt를 입력으로 받아 새로운 solution을 생성합니다.(generated solutions)
- objective function evaluator : generated solution을 평가하여 score를 구합니다. 이때 평가자는 optimizer와는 다른 별개의 LLM입니다.
- score : evaluator를 통해 획득한 score를 generated solution과 쌍으로 묶어 meta-prompt로 만들고 과정을 반복합니다.
- 종료 시점은 더이상 높은 점수의 solution을 생성할 수 없거나 정해놓은 최적화 횟수 최대치에 다다랐을 때입니다.
Trading off exploration and exploitation
이미 어느 정도 괜찮은 solution이 발견된 상태에서는 exploration과 exploitation 둘 중 하나에 가중치를 더 주어야 합니다.
즉 cost를 더 들여서 남은 solution space를 탐색해 기존보다 더 좋은 solution을 찾을 것인지(exploration),
아니면 기존 solution을 그대로 이용할 것인지(exploitation)를 결정하게 됩니다.
이것이 optimization의 핵심이기 때문에, LLM은 이를 적절히 조절하고 판단할 수 있는 능력이 필요합니다.
Optimization trajectory
LLM은 in-context demonstration에서 패턴을 인지하고 학습할 수 있는 것으로 알려져 있습니다.
따라서 새로운 solution을 생성하기 위해 이전의 optimization 기록들을 input으로 제공합니다.
위 구성 요소 중 solution-score pair가 여기에 해당합니다.
Instruction Positions
- Q_begin : original question 앞에 instruction을 붙이는 경우
- Q_end : original question 뒤에 instruction을 붙이는 경우
- A_begin : scorer LLM의 output 시작에 insturction을 붙이는 경우. instruction tuning 없이 QA 형태의 sequence에도 붙을 수 있음
instruction을 어느 위치에 삽입하는지에 따라 성능이 다른지에 대한 실험 결과도 존재합니다.
같은 모델을 사용하더라도 instruction이 삽입된 위치에 따라 다른 결과물이 나온다는 것을 알 수 있습니다.
위 실험 결과(BBH, 난이도가 아주 높은 reasoning benchmark) 외에도 다양한 성능 평가에 instruction 위치별 비교 결과가 포함됩니다.
결과적으로 instruction 위치에 따른 성능 변화는 큰 의미가 없습니다.
같은 맥락에서 가장 높은 성능을 보인 scorer(평가자) LLM과 학습을 진행하는 optimizer LLM도 실험 결과에 정리되어 있습니다.
QA pair가 없는 instruction을 사용할 때도 있어 다양한 상황이 존재하므로 논문 내용을 직접 확인해보시길 권장드립니다.
- 개인적 감상
솔직 담백한 논문이라는 생각이 들었습니다.
사실 지금까지 여러 논문들이 자신들의 아이디어를 제시할 때, 특정 태스크나 상황에서 다른 모델들에 비해 우월한 성능을 보여주기 바쁜 것에 비해, 이러한 기법을 적용하는 것의 목적과 한계를 명확히 밝혔다는 것이 더 설득력 있는 서술 방식이라고 느껴졌습니다.
어찌 보면 굉장히 간단한 태스크에 속하는 logistic regression에 대해서도 결국 기존 알고리즘을 대체할 만큼의 성능을 아직 보이지는 못했지만, LLM으로 optimizing을 한다는 것 자체가 굉장히 신선하게 느껴졌습니다.
대신 구체적으로 어떤 동작 원리를 가지는지에 대해서는 면밀히 살펴볼 필요가 있는 것 같습니다.
scorer와 optimizer에 대해 LLM을 각각 사용한다고 보면 결국 LLM을 tuning하는 것으로 보이지는 않기 때문입니다.
더욱 정교한 instruction을 만들고 발전해나가는 것으로 이해되긴 하지만, 실질적으로 parameter update가 일어나지 않는 것처럼 보입니다.
(줄여야하는 loss가 명시되어 있지 않습니다. 이를 학습이라고 볼 수 있을까요?)
출처 : https://arxiv.org/abs/2309.03409
Large Language Models as Optimizers
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and
arxiv.org