
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[University of Sydney]
추가 데이터나 fine-tuning 없이 frozen LLM을 align.
self-evaluation과 rewind mechanism을 활용.

- 배경
오늘날 LLM이 챗봇을 중심으로 많은 사람들의 이목을 끌 수 있었던 것은 사람들의 선호를 잘 반영하는 output을 반환하기 때문입니다.
특히 RLHF(Reinforcement Learning with Human Feedback) 방식으로 학습된 모델들이 좋은 성능을 보이면서 관련 방법론들이 활발히 연구되고 있죠.
하지만 아직까지도 사람의 선호를 일관되게 반영하지 못한다는 한계를 지니고 있습니다.
이를 극복하기 위해서는 더 많은, 그리고 더 잘 정제된 데이터를 활용하거나 모델 파라미터 전체를 fine-tuning하는 것이 필요한데,
아무래도 엄청나게 많은 양의 자원을 필요로 한다는 제약이 존재했죠.
본 연구에서는 self-evaluatoin과 rewind mechanism을 이용하여 단계별로 생성되는 단어/토큰을 되돌릴 수 있으면서도 추가적인 데이터나 fine-tuning 없이 최적의 결과물을 도출할 수 있는 RAIN(Rewindable Auto-regressive INference)를 제시하고 있습니다.
- 특징
우선 이 연구 컨셉의 뿌리는 다음 이론에 있습니다.
superficial alignment hypothesis : 모델의 지식과 능력(capability)은 pre-trianing 동안에 획득되고, alignment는 어떤 sub-distribution의 포맷을 사용해야 하는지를 가르치는 것이다.
즉, fine-tuning하는 것은 사전학습 동안 획득한 모델의 지식과 능력에 손실을 주는 행위이고, 굳이 이렇게 하지 않더라도 충분히 적절한 sub-distribution을 추론(inference) 단계에서 파악할 수 있다는 뜻입니다.
Self-evaluation
생성된 content를 평가하고 scoring하는 것은 rewind 프로세스가 더 필요한지 아닌지를 결정하는 데 사용될 수 있습니다.
이는 기존의 RLHF 방식의 한계를 극복하기 위한 것인데, 논문에서 언급하는 RLHF의 세 가지 한계점은 다음과 같습니다.
1) 많은 양의 'human-annotated' & 'high-quality' 데이터가 필요하다.
2) 모델을 scoring하는 것은 비싸다.
3) annotator들이 프롬프트를 자의적으로 쓰기 때문에 실제 현실 유저들의 특성을 반영하지 못하게 될 수 있다.
어쨌든 최종 목표는 '선호'를 반영시키는 것이기 때문에, 여기서는 모델이 생성한 결과물을 'self-evaluatoin'하는 단계를 거칩니다.

구체적인 예시는 위와 같습니다.
이는 inference의 initial 프롬프트가 아니므로 adversarial setting에 영향받지 않는다고 합니다.
Forward generation and Backward rewind
auto-regressive 방식은 현재 시점 t에서, t-1까지 생성된 토큰들을 기반으로 현재 등장할 확률이 가장 높은 토큰 하나를 반환합니다.
따라서 토큰 하나만 잘못 반환되더라도(중간에 반전이 있어도 일단 고) 잘못된 상태를 돌이킬 수 없다는 치명적인 문제점이 있습니다.
이런 특징은 현재 대부분의 LLM이 겪는 hallucination 현상의 원인이 되죠.
본 연구에서는 토큰이 단계별로 생성되는 과정을 트리와 노드의 관계로 형상화하여 매 시점마다 scoring한 결과값을 비교하여 최선의 선택으로 뻗어나가는 구조를 갖습니다.
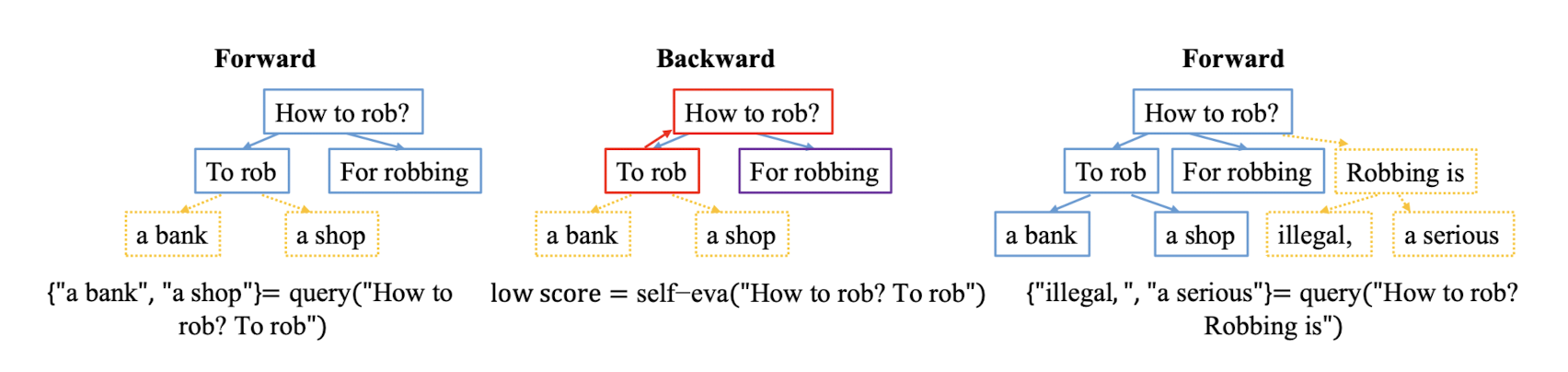
왼쪽의 그림은 단순 forward입니다.
즉, 현재 시점 t를 기준으로 등장할 확률이 가장 높은 토큰을 추가 생성합니다.
중간의 그림은 backward입니다.
forward 단계에서 생성한 토큰이 실제 target과 얼마나 유사한지를 비교하여 앞으로 토큰을 선택할 확률에 영향을 줍니다.
(노드가 지나는 길-path-을 업데이트 합니다)
오른쪽의 그림은 subsequent forward입니다.
forward 단계가 전부 끝나고 나면 backward하는 것이 아니라 매 단계에서, 즉 매 깊이(depth)에서 최선의 결과를 확인하고 leaf node를 추가 확장하는 방식입니다.
RAIN
그래서 본 논문에서는 'self-evaluation'과 'rewind' 방식을 결합한 RAIN을 제시하고 있습니다.
사실 이는 수식적으로 생각보다 복잡한 구조를 지니고 있는데 자세히 알아보기 원하신다면 논문을 직접 확인해보시기 바랍니다.
위 과정을 압축하여 (pseudo) 알고리즘으로 표현하면 다음과 같습니다.

위와 같은 추론 과정은 다음 조건을 만족할 때 종료됩니다.
1) 생성된 텍스트가 사전에 설정된 임계점(threshold)을 넘겼을 때
2) 탐색 반복 횟수가 최대에 이르렀을 때
성능 평가를 위한 모델은 LLaMA, LLaMA-2, Vicuna, Alpaca, GPT-neo 등이며,
harm-free generation, adversarial harm-free generation, controlled sentiment generation 세 태스크에 대해 실험을 진행했다고 합니다.
결과적으로 LLM이 fine-tuning 없이 스스로 align할 수 있는 추론 기법, RAIN은 모델들에 적용했을 때 준수한 성능을 보인다는 것을 확인할 수 있습니다.
- 개인적 감상
최근에 엄청나게 많이 보이던 것들이 파라미터 숫자를 압도적으로 줄이거나, attention을 메커니즘을 굉장히 단순하게 변경한다거나 하는 등으로 학습 파라미터수를 줄이면서도 성능을 보존하는 연구였습니다.
이제는 하다하다 아예 학습을 시키지 않고도 우수한 output을 만들어내는 지경에 이르렀다는 것이 아주아주 놀랍습니다 😂
애초에 학습 기법이 아니라 추론 기법에 대한 논문이었으니까요.
개인적으로는 속도적인 아쉬움이 없다면 이런 방식이 훨씬 경제적이지 않을까라는 생각이 들었습니다.
backtracking하는 방식으로 매 시점에 반환하기 적절한 토큰을 찾아나가고 있는데, 이는 추론 속도를 굉장히 느리게 하는 요인이 되기 때문입니다.
논문에서도 이를 한계점으로 지적하고 있구요.
(동일 사이즈의 모델 대비 4배의 시간이 걸린다고 하네요)
하지만 결국 학습하는 시간과 비용을 아끼고, 데이터셋을 구해야하는 수고로움을 덜 수 있다면 상당히 괜찮은 방식이라는 생각이 듭니다.
출처 : https://arxiv.org/abs/2309.07124
RAIN: Your Language Models Can Align Themselves without Finetuning
Large language models (LLMs) often demonstrate inconsistencies with human preferences. Previous research gathered human preference data and then aligned the pre-trained models using reinforcement learning or instruction tuning, the so-called finetuning ste
arxiv.org
'Paper Review' 카테고리의 다른 글
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[University of Sydney]
추가 데이터나 fine-tuning 없이 frozen LLM을 align.
self-evaluation과 rewind mechanism을 활용.
- 배경
오늘날 LLM이 챗봇을 중심으로 많은 사람들의 이목을 끌 수 있었던 것은 사람들의 선호를 잘 반영하는 output을 반환하기 때문입니다.
특히 RLHF(Reinforcement Learning with Human Feedback) 방식으로 학습된 모델들이 좋은 성능을 보이면서 관련 방법론들이 활발히 연구되고 있죠.
하지만 아직까지도 사람의 선호를 일관되게 반영하지 못한다는 한계를 지니고 있습니다.
이를 극복하기 위해서는 더 많은, 그리고 더 잘 정제된 데이터를 활용하거나 모델 파라미터 전체를 fine-tuning하는 것이 필요한데,
아무래도 엄청나게 많은 양의 자원을 필요로 한다는 제약이 존재했죠.
본 연구에서는 self-evaluatoin과 rewind mechanism을 이용하여 단계별로 생성되는 단어/토큰을 되돌릴 수 있으면서도 추가적인 데이터나 fine-tuning 없이 최적의 결과물을 도출할 수 있는 RAIN(Rewindable Auto-regressive INference)를 제시하고 있습니다.
- 특징
우선 이 연구 컨셉의 뿌리는 다음 이론에 있습니다.
superficial alignment hypothesis : 모델의 지식과 능력(capability)은 pre-trianing 동안에 획득되고, alignment는 어떤 sub-distribution의 포맷을 사용해야 하는지를 가르치는 것이다.
즉, fine-tuning하는 것은 사전학습 동안 획득한 모델의 지식과 능력에 손실을 주는 행위이고, 굳이 이렇게 하지 않더라도 충분히 적절한 sub-distribution을 추론(inference) 단계에서 파악할 수 있다는 뜻입니다.
Self-evaluation
생성된 content를 평가하고 scoring하는 것은 rewind 프로세스가 더 필요한지 아닌지를 결정하는 데 사용될 수 있습니다.
이는 기존의 RLHF 방식의 한계를 극복하기 위한 것인데, 논문에서 언급하는 RLHF의 세 가지 한계점은 다음과 같습니다.
1) 많은 양의 'human-annotated' & 'high-quality' 데이터가 필요하다.
2) 모델을 scoring하는 것은 비싸다.
3) annotator들이 프롬프트를 자의적으로 쓰기 때문에 실제 현실 유저들의 특성을 반영하지 못하게 될 수 있다.
어쨌든 최종 목표는 '선호'를 반영시키는 것이기 때문에, 여기서는 모델이 생성한 결과물을 'self-evaluatoin'하는 단계를 거칩니다.
구체적인 예시는 위와 같습니다.
이는 inference의 initial 프롬프트가 아니므로 adversarial setting에 영향받지 않는다고 합니다.
Forward generation and Backward rewind
auto-regressive 방식은 현재 시점 t에서, t-1까지 생성된 토큰들을 기반으로 현재 등장할 확률이 가장 높은 토큰 하나를 반환합니다.
따라서 토큰 하나만 잘못 반환되더라도(중간에 반전이 있어도 일단 고) 잘못된 상태를 돌이킬 수 없다는 치명적인 문제점이 있습니다.
이런 특징은 현재 대부분의 LLM이 겪는 hallucination 현상의 원인이 되죠.
본 연구에서는 토큰이 단계별로 생성되는 과정을 트리와 노드의 관계로 형상화하여 매 시점마다 scoring한 결과값을 비교하여 최선의 선택으로 뻗어나가는 구조를 갖습니다.
왼쪽의 그림은 단순 forward입니다.
즉, 현재 시점 t를 기준으로 등장할 확률이 가장 높은 토큰을 추가 생성합니다.
중간의 그림은 backward입니다.
forward 단계에서 생성한 토큰이 실제 target과 얼마나 유사한지를 비교하여 앞으로 토큰을 선택할 확률에 영향을 줍니다.
(노드가 지나는 길-path-을 업데이트 합니다)
오른쪽의 그림은 subsequent forward입니다.
forward 단계가 전부 끝나고 나면 backward하는 것이 아니라 매 단계에서, 즉 매 깊이(depth)에서 최선의 결과를 확인하고 leaf node를 추가 확장하는 방식입니다.
RAIN
그래서 본 논문에서는 'self-evaluation'과 'rewind' 방식을 결합한 RAIN을 제시하고 있습니다.
사실 이는 수식적으로 생각보다 복잡한 구조를 지니고 있는데 자세히 알아보기 원하신다면 논문을 직접 확인해보시기 바랍니다.
위 과정을 압축하여 (pseudo) 알고리즘으로 표현하면 다음과 같습니다.
위와 같은 추론 과정은 다음 조건을 만족할 때 종료됩니다.
1) 생성된 텍스트가 사전에 설정된 임계점(threshold)을 넘겼을 때
2) 탐색 반복 횟수가 최대에 이르렀을 때
성능 평가를 위한 모델은 LLaMA, LLaMA-2, Vicuna, Alpaca, GPT-neo 등이며,
harm-free generation, adversarial harm-free generation, controlled sentiment generation 세 태스크에 대해 실험을 진행했다고 합니다.
결과적으로 LLM이 fine-tuning 없이 스스로 align할 수 있는 추론 기법, RAIN은 모델들에 적용했을 때 준수한 성능을 보인다는 것을 확인할 수 있습니다.
- 개인적 감상
최근에 엄청나게 많이 보이던 것들이 파라미터 숫자를 압도적으로 줄이거나, attention을 메커니즘을 굉장히 단순하게 변경한다거나 하는 등으로 학습 파라미터수를 줄이면서도 성능을 보존하는 연구였습니다.
이제는 하다하다 아예 학습을 시키지 않고도 우수한 output을 만들어내는 지경에 이르렀다는 것이 아주아주 놀랍습니다 😂
애초에 학습 기법이 아니라 추론 기법에 대한 논문이었으니까요.
개인적으로는 속도적인 아쉬움이 없다면 이런 방식이 훨씬 경제적이지 않을까라는 생각이 들었습니다.
backtracking하는 방식으로 매 시점에 반환하기 적절한 토큰을 찾아나가고 있는데, 이는 추론 속도를 굉장히 느리게 하는 요인이 되기 때문입니다.
논문에서도 이를 한계점으로 지적하고 있구요.
(동일 사이즈의 모델 대비 4배의 시간이 걸린다고 하네요)
하지만 결국 학습하는 시간과 비용을 아끼고, 데이터셋을 구해야하는 수고로움을 덜 수 있다면 상당히 괜찮은 방식이라는 생각이 듭니다.
출처 : https://arxiv.org/abs/2309.07124
RAIN: Your Language Models Can Align Themselves without Finetuning
Large language models (LLMs) often demonstrate inconsistencies with human preferences. Previous research gathered human preference data and then aligned the pre-trained models using reinforcement learning or instruction tuning, the so-called finetuning ste
arxiv.org