
예전(2020.10)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Reserach, Brain Team]
image patch의 sequence에 pure transformer를 적용하여 image classification을 수행.
타 모델 대비 적은 computational resource를 요하면서도 우월한 성능을 보임.
- 배경
transformer가 등장하며 NLP를 집어 삼키게 된 이후로, 이 아키텍쳐를 이미지 분야에 적용하고자 하는 여러 시도들이 있었습니다.
각 픽셀을 대상으로 self-attention을 적용하거나 지엽적으로 self-attention을 적용하는 등의 접근이 있었습니다.
하지만 기존 연구들의 가장 큰 한계는 결국 늘어나는 computational 비용 대비 낮은 성능이었습니다.
애초에 CNN 계열 모델들의 성능에 한참 미치지도 못했구요..
본 논문에서는 이미지를 여러 patch(PxP)로 쪼개고 각 patch를 하나의 token 단위로 취급하여 transformer encoder 모델에 입력으로 제공하는 방법을 제안하고 있습니다.
이런 구조는 다른 모델들에 비해 학습 가능한 파라미터의 수가 적습니다.
- 특징
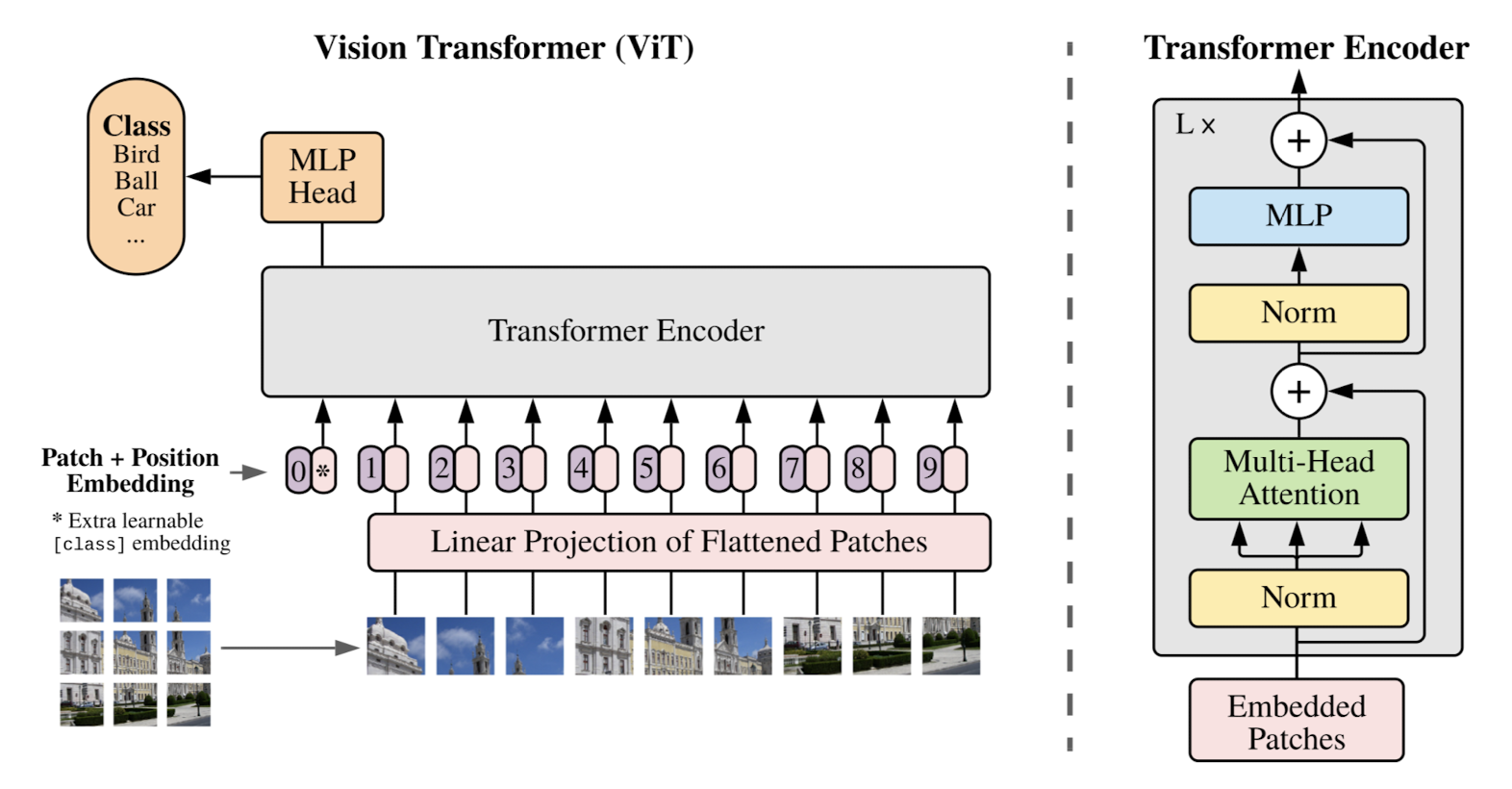
Architecture
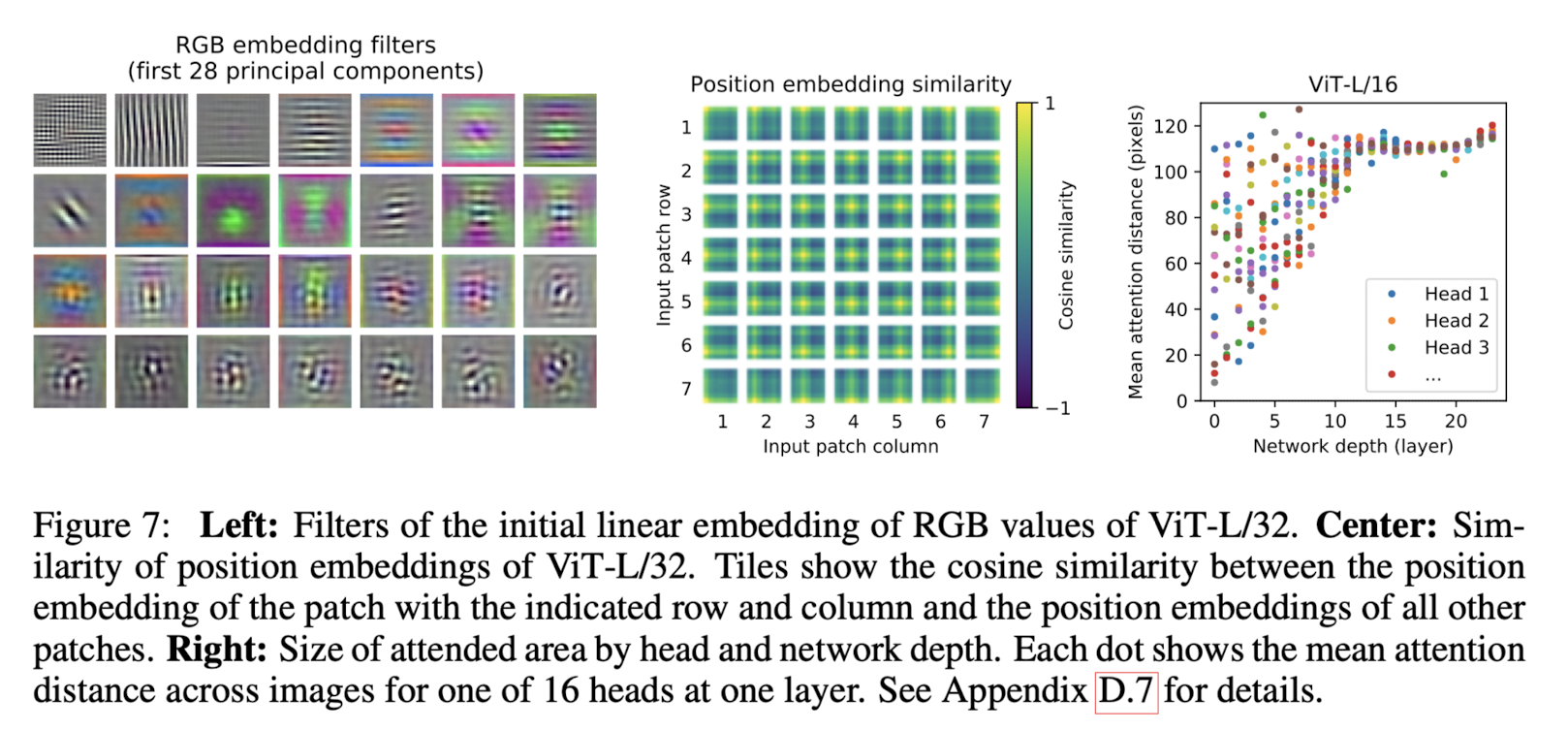
본 연구에서는 크게 세 개 사이즈의 모델을 만들고, 그 이름 뒤에는 패치 개수를 적습니다.
즉, 위 이미지는 ViT의 Large 모델이면서 패치는 32개를 사용한 모델의 실험 결과를 나타내고 있습니다.
왼쪽 이미지는 RGB값의 초기 linear embedding 필터를 나타냅니다.
중간 이미지는 position embedding 간의 유사도를 나타냅니다.
오른쪽 이미지는 네트워크 깊이에 따른 평균 attention distance를 나타냅니다.
이를 통해 ViT 아키텍쳐가 이미지 patch 단위에 대해 유의미한 학습을 할 수 있는 구조라는 것을 알 수 있습니다.
- 개인적 감상
NLP 분야에 큰 혁신을 불러일으킨 transformer의 아키텍쳐가 이미지 분야에 적용되면서도 엄청나게 큰 영향을 주었다고 알고 있었고,
그래서 어떤 식으로 아키텍쳐를 적용했을지 항상 궁금했습니다.
그런데 생각했던 것보다 너무나도 간단한 방식이라 놀라웠습니다.
물론 지금에 이르러서야 patch 단위로 입력을 준다는 것이 간단해 보이는 것이긴 하지만 standard transformer 구조를 그대로 가져가며 마지막에 classifier만 추가하여 우수한 성능을 낼 수 있었다는 것이 굉장히 신기합니다.
진짜 이게.. 왜 잘 되지..? 하는 느낌이었어요 😂
그래도 분류 태스크 한정으로 좋은 성능을 냈다는 점이 한계로 지적되었습니다.
이미지 분야의 다른 태스크를 다루기엔 아쉬움이 많은 아키텍쳐인 것 같은데 다른 연구에서는 이를 어떻게 극복했는지에 대해서도 공부하면 좋을 것 같다고 생각했습니다.
출처 : https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
'Paper Review' 카테고리의 다른 글
예전(2020.10)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Google Reserach, Brain Team]
image patch의 sequence에 pure transformer를 적용하여 image classification을 수행.
타 모델 대비 적은 computational resource를 요하면서도 우월한 성능을 보임.
- 배경
transformer가 등장하며 NLP를 집어 삼키게 된 이후로, 이 아키텍쳐를 이미지 분야에 적용하고자 하는 여러 시도들이 있었습니다.
각 픽셀을 대상으로 self-attention을 적용하거나 지엽적으로 self-attention을 적용하는 등의 접근이 있었습니다.
하지만 기존 연구들의 가장 큰 한계는 결국 늘어나는 computational 비용 대비 낮은 성능이었습니다.
애초에 CNN 계열 모델들의 성능에 한참 미치지도 못했구요..
본 논문에서는 이미지를 여러 patch(PxP)로 쪼개고 각 patch를 하나의 token 단위로 취급하여 transformer encoder 모델에 입력으로 제공하는 방법을 제안하고 있습니다.
이런 구조는 다른 모델들에 비해 학습 가능한 파라미터의 수가 적습니다.
- 특징
Architecture
본 연구에서는 크게 세 개 사이즈의 모델을 만들고, 그 이름 뒤에는 패치 개수를 적습니다.
즉, 위 이미지는 ViT의 Large 모델이면서 패치는 32개를 사용한 모델의 실험 결과를 나타내고 있습니다.
왼쪽 이미지는 RGB값의 초기 linear embedding 필터를 나타냅니다.
중간 이미지는 position embedding 간의 유사도를 나타냅니다.
오른쪽 이미지는 네트워크 깊이에 따른 평균 attention distance를 나타냅니다.
이를 통해 ViT 아키텍쳐가 이미지 patch 단위에 대해 유의미한 학습을 할 수 있는 구조라는 것을 알 수 있습니다.
- 개인적 감상
NLP 분야에 큰 혁신을 불러일으킨 transformer의 아키텍쳐가 이미지 분야에 적용되면서도 엄청나게 큰 영향을 주었다고 알고 있었고,
그래서 어떤 식으로 아키텍쳐를 적용했을지 항상 궁금했습니다.
그런데 생각했던 것보다 너무나도 간단한 방식이라 놀라웠습니다.
물론 지금에 이르러서야 patch 단위로 입력을 준다는 것이 간단해 보이는 것이긴 하지만 standard transformer 구조를 그대로 가져가며 마지막에 classifier만 추가하여 우수한 성능을 낼 수 있었다는 것이 굉장히 신기합니다.
진짜 이게.. 왜 잘 되지..? 하는 느낌이었어요 😂
그래도 분류 태스크 한정으로 좋은 성능을 냈다는 점이 한계로 지적되었습니다.
이미지 분야의 다른 태스크를 다루기엔 아쉬움이 많은 아키텍쳐인 것 같은데 다른 연구에서는 이를 어떻게 극복했는지에 대해서도 공부하면 좋을 것 같다고 생각했습니다.
출처 : https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org