
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
LLM의 hallucination을 줄이기 위한 방법으로 Chain-of-Verification, CoVe를 제안.
CoVe는 네 개의 단계로 구성됨.

- 배경
LLM이 사실이 아닌 것을 마치 사실처럼 표현하는 현상인 hallucination 문제가 심각하다는 것은 이미 잘 알려져 있습니다.
이 현상을 최소화하고자 하는 연구들도 많이 이뤄지고 있구요.
이러한 시도들을 크게 'training-time correction', 'generation-time correction', 'via augmentation'으로 구분할 수 있습니다.
특히 'augmentation' 같은 경우 최근에 'Retrieval Augmented Generation(RAG)'로 발전하여 아주 핫한 연구 주제이기도 합니다.
본 논문에서는 기존의 연구 중에서는 'generation-time correction'에 해당하는 방식을 제안하고 있습니다.
query에 대해 생성되는 답변을 평가함으로써 가장 적절한 답변을 반환할 수 있도록 하는 구조를 갖춥니다.
- 특징
Chain-of-Verification(CoVe)는 네 개의 core step으로 구성됩니다.
Step 1. Generate Baseline Response : query가 주어지면 LLM이 response를 생성합니다.
Step 2. Plan Verifications : query와 이를 바탕으로 생성된 response를 바탕으로 verification list를 생성합니다.
Step 3. Execute Verifications : verficiation list에 나타난 verification 질문에 답하며 response의 상태를 확인합니다.
Step 4. Generate Final Verified Response : 위에서 문제가 있는 response가 발견되었다면 개선된 response를 생성합니다. 이 단계에서는 주로 few-shot prompt가 사용됩니다.
Execute Verifications
- Joint : 한 개의 LLM 프롬프트를 사용하여 step 2 & 3 를 처리합니다. 여기에는 verification을 위한 question과 answer가 둘 다 포함됩니다.
- 2-Step : verification question과 verification answer를 순서대로 실행합니다. Joint 방식에서 우려되는 문제점은 base response를 반복하는 answer를 생성하게 되는 것인데, 이를 방지하기 위함입니다.
- Factored : prompt가 base response(Step 1)를 포함하지 않도록 합니다. 즉, verification의 answer를 생성할 때 base response에 의존하지 않고 독립적인 답변 생성이 가능하도록 하는 것입니다.
- Factor + Revise : implicitly, explicitly cross check 할 수 있도록 합니다. 이는 extrac LLM prompt를 이용하여 수행 가능합니다. 또한 이때는 baseline response, verificatoin question & answer가 모두 필요합니다.
Experiment
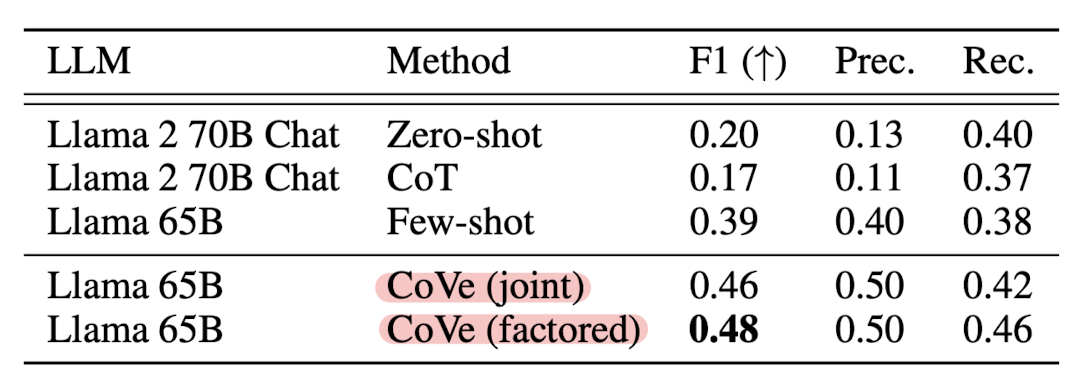
사용한 backbone 모델은 LLaMA 65B입니다.
성능 확인을 위한 태스크는 WikiData, Wiki-Category List, MultiSpanQA, Longform Generation of Biographies 입니다.
다양한 실험 결과들을 정리해두었으니 논문을 직접 참고해보시기 바랍니다.
핵심 실험 결과만 리스트로 만들면 다음과 같습니다.
- CoVe는 리스트 기반 answer 태스크에서 precision 향상에 도움이 됩니다.
- CoVe는 closed book QA 태스크의 성능 향상에 도움이 됩니다.
- CoVe는 longform generation 태스크에서 성능 향상에 도움이 됩니다.
- Instruction-tuning과 CoT만으로는 hallucination을 줄일 수 없습니다.
- Factored & 2-step CoVe는 성능 향상에 도움이 됩니다.
- CoVe 기반의 Llama 모델은 심지어 InstructGPT, ChatGPT, Perplexity AI 모델보다 우수한 결과를 보여줍니다.
- 짧은 형태의 verificatoin question이 long from query보다 더욱 정확한 answer를 이끌어 낼 수 있습니다.
- LLM 기반의 verification question은 heuristics보다 월등합니다.
- Open verification question이 yes/no based question보다 효과적입니다.
- 개인적 감상
아무래도 이 방법론의 한계점에 눈이 더욱 많이 가는 것 같습니다.
물론 이런 방법을 적용한다고 해서 hallucination이 완벽히 사라질 것을 기대하는 것은 아닙니다.
하지만 논문에서 스스로 밝힌 바와 같이 hallucination은 사실 기반 QA 형태에서만 나타나는 것은 아닙니다.
가장 대표적으로는 reasoning step에서 발생하는 상황을 떠올릴 수가 있는데, 이런 부분을 개선하지 못한 것이 아쉽습니다.
아무래도 여러 문장을 이어서 생성하는 과정에서 어디서부터 이런 문제점이 시작되었는지 파악하기도 어렵고, 이와 같은 방식으로는 엄청난 비용이 초래될 수밖에 없다는 것이 큰 문제점으로 보입니다.
또한 모델의 의존도가 너무 높다는 것도 문제입니다.
그런데 이를 감안하면 어째서 LLaMA 2가 LLaMA에 비해 좋지 않은 결과를 보여주었는지에 대한 설명의 부재가 납득되지 않습니다.
애초에 Meta에서 실험한 내용인데 baseline 모델 선정 이유를 밝히지 않은 이유가 궁금합니다.
'Paper Review' 카테고리의 다른 글
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Meta AI]
LLM의 hallucination을 줄이기 위한 방법으로 Chain-of-Verification, CoVe를 제안.
CoVe는 네 개의 단계로 구성됨.
- 배경
LLM이 사실이 아닌 것을 마치 사실처럼 표현하는 현상인 hallucination 문제가 심각하다는 것은 이미 잘 알려져 있습니다.
이 현상을 최소화하고자 하는 연구들도 많이 이뤄지고 있구요.
이러한 시도들을 크게 'training-time correction', 'generation-time correction', 'via augmentation'으로 구분할 수 있습니다.
특히 'augmentation' 같은 경우 최근에 'Retrieval Augmented Generation(RAG)'로 발전하여 아주 핫한 연구 주제이기도 합니다.
본 논문에서는 기존의 연구 중에서는 'generation-time correction'에 해당하는 방식을 제안하고 있습니다.
query에 대해 생성되는 답변을 평가함으로써 가장 적절한 답변을 반환할 수 있도록 하는 구조를 갖춥니다.
- 특징
Chain-of-Verification(CoVe)는 네 개의 core step으로 구성됩니다.
Step 1. Generate Baseline Response : query가 주어지면 LLM이 response를 생성합니다.
Step 2. Plan Verifications : query와 이를 바탕으로 생성된 response를 바탕으로 verification list를 생성합니다.
Step 3. Execute Verifications : verficiation list에 나타난 verification 질문에 답하며 response의 상태를 확인합니다.
Step 4. Generate Final Verified Response : 위에서 문제가 있는 response가 발견되었다면 개선된 response를 생성합니다. 이 단계에서는 주로 few-shot prompt가 사용됩니다.
Execute Verifications
- Joint : 한 개의 LLM 프롬프트를 사용하여 step 2 & 3 를 처리합니다. 여기에는 verification을 위한 question과 answer가 둘 다 포함됩니다.
- 2-Step : verification question과 verification answer를 순서대로 실행합니다. Joint 방식에서 우려되는 문제점은 base response를 반복하는 answer를 생성하게 되는 것인데, 이를 방지하기 위함입니다.
- Factored : prompt가 base response(Step 1)를 포함하지 않도록 합니다. 즉, verification의 answer를 생성할 때 base response에 의존하지 않고 독립적인 답변 생성이 가능하도록 하는 것입니다.
- Factor + Revise : implicitly, explicitly cross check 할 수 있도록 합니다. 이는 extrac LLM prompt를 이용하여 수행 가능합니다. 또한 이때는 baseline response, verificatoin question & answer가 모두 필요합니다.
Experiment
사용한 backbone 모델은 LLaMA 65B입니다.
성능 확인을 위한 태스크는 WikiData, Wiki-Category List, MultiSpanQA, Longform Generation of Biographies 입니다.
다양한 실험 결과들을 정리해두었으니 논문을 직접 참고해보시기 바랍니다.
핵심 실험 결과만 리스트로 만들면 다음과 같습니다.
- CoVe는 리스트 기반 answer 태스크에서 precision 향상에 도움이 됩니다.
- CoVe는 closed book QA 태스크의 성능 향상에 도움이 됩니다.
- CoVe는 longform generation 태스크에서 성능 향상에 도움이 됩니다.
- Instruction-tuning과 CoT만으로는 hallucination을 줄일 수 없습니다.
- Factored & 2-step CoVe는 성능 향상에 도움이 됩니다.
- CoVe 기반의 Llama 모델은 심지어 InstructGPT, ChatGPT, Perplexity AI 모델보다 우수한 결과를 보여줍니다.
- 짧은 형태의 verificatoin question이 long from query보다 더욱 정확한 answer를 이끌어 낼 수 있습니다.
- LLM 기반의 verification question은 heuristics보다 월등합니다.
- Open verification question이 yes/no based question보다 효과적입니다.
- 개인적 감상
아무래도 이 방법론의 한계점에 눈이 더욱 많이 가는 것 같습니다.
물론 이런 방법을 적용한다고 해서 hallucination이 완벽히 사라질 것을 기대하는 것은 아닙니다.
하지만 논문에서 스스로 밝힌 바와 같이 hallucination은 사실 기반 QA 형태에서만 나타나는 것은 아닙니다.
가장 대표적으로는 reasoning step에서 발생하는 상황을 떠올릴 수가 있는데, 이런 부분을 개선하지 못한 것이 아쉽습니다.
아무래도 여러 문장을 이어서 생성하는 과정에서 어디서부터 이런 문제점이 시작되었는지 파악하기도 어렵고, 이와 같은 방식으로는 엄청난 비용이 초래될 수밖에 없다는 것이 큰 문제점으로 보입니다.
또한 모델의 의존도가 너무 높다는 것도 문제입니다.
그런데 이를 감안하면 어째서 LLaMA 2가 LLaMA에 비해 좋지 않은 결과를 보여주었는지에 대한 설명의 부재가 납득되지 않습니다.
애초에 Meta에서 실험한 내용인데 baseline 모델 선정 이유를 밝히지 않은 이유가 궁금합니다.