
최근(2023.09)에 나온 논문을 읽어보고 간단히 정리했습니다.
혹시 부족하거나 잘못된 내용이 있다면 댓글 부탁드립니다 🙇♂️
[Qwen Team, Alibaba Group]
유사한 사이즈 모델 대비 우수한 성능을 보이는 Qwen model series를 공개.
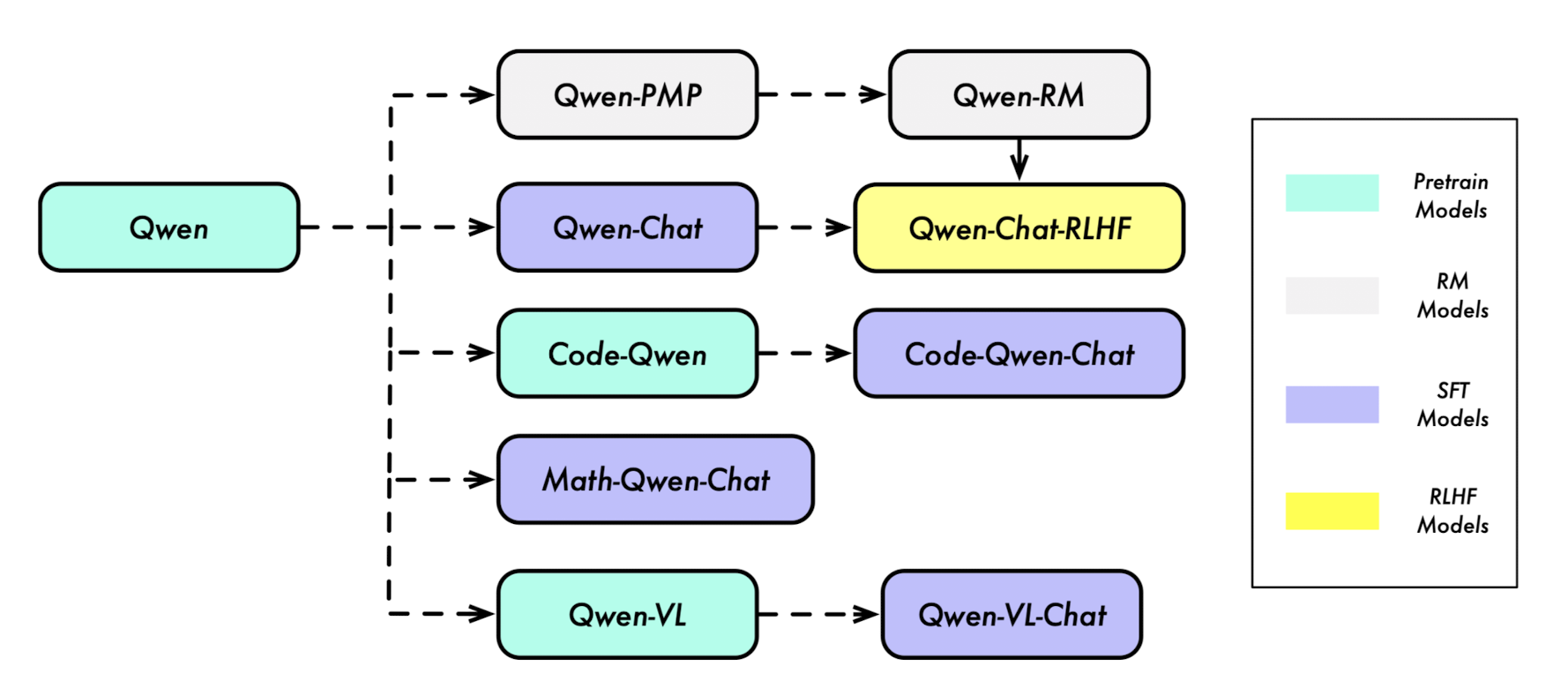
Qwen, Qwen-Chat, Code-Qwen, Code-Qwen-Chat, Math-Qwen-Chat
배경
최근 핫하게 떠오르는 Qwen 모델의 technical report가 있어 이를 살펴보고 간단히 정리해보고자 합니다.
Qwen은 Qianwen이라는 중국 구절에서 따온 것으로, 'thousands of prompts'라는 의미를 담고 있다고 합니다.
위 모델 series 구성도에서 볼 수 있는 것처럼, pre-trained model, RM model, SFT model, RLHF model 등 그 구성이 다양합니다.
이정도의 다양한 모델을 한꺼번에 공개한 것은 Microsoft의 Wizard LM과 관련 모델 패밀리를 떠올리게 만드네요.
요약
- 베이스 언어 모델 QWEN은 다양한 텍스트와 코드로 구성된 3 trillion개의 토큰으로 학습되었다.
덕분에 비슷한 사이즈의 counterparts에 대해 우수한 downstream task performance를 보여줄 수 있다. - QWEN-CHAT 모델은 task, chat, tool use, agent, safety와 관련하여 정제된 데이터셋에 신중을 기하여 fine-tuned 되었다.
또한 RLHF를 적용하기 위해 human prefrerence를 반영하는 reward 모델을 학습시켰다.
RLHF로 학습된 QWEN-CHAT 모델은 뛰어난 성능을 보였지만, GPT-4에 비해서는 여전히 못미치는 수준이다. - Code-Qwen & Code-Qwen-Chat과 같은 specialized 모델들 또한 공개되었다.
Code-Qwen은 방대한 양의 코드 데이터에 대해 사전 학습된 후, code generation, debugging, interpretation와 관련된 대화에 대해 fine-tune 되었다. - 추가로 Math-Qwen-Chat이라는 모델은 수학적 문제를 다루기 위해 고안된 모델로, GSM8K와 같은 MWPS 벤치마크에서 GPT-3.5를 넘어서는 퍼포먼스를 보여주었다.
- visual and language instruction을 이해할 수 있는 능력을 갖춘 Qwen-VL, Qwen-VL-Chat 모델도 공개되었다.
이 모델들은 여러 태스크에서 현재 공개된 open-source vision-language 모델들 대비 우수한 성능을 보여주었다.
Pretraining
- Data : 모델 학습에 사용되는 데이터의 양이 모델 성능에 크게 영향을 준다는 것은 이미 잘 알려져 있습니다. 따라서 대규모의 고품질 데이터셋을 확보하기 위한 pre-processing, deduplication 등에 대한 내용이 report에 잘 기술되어 있습니다.
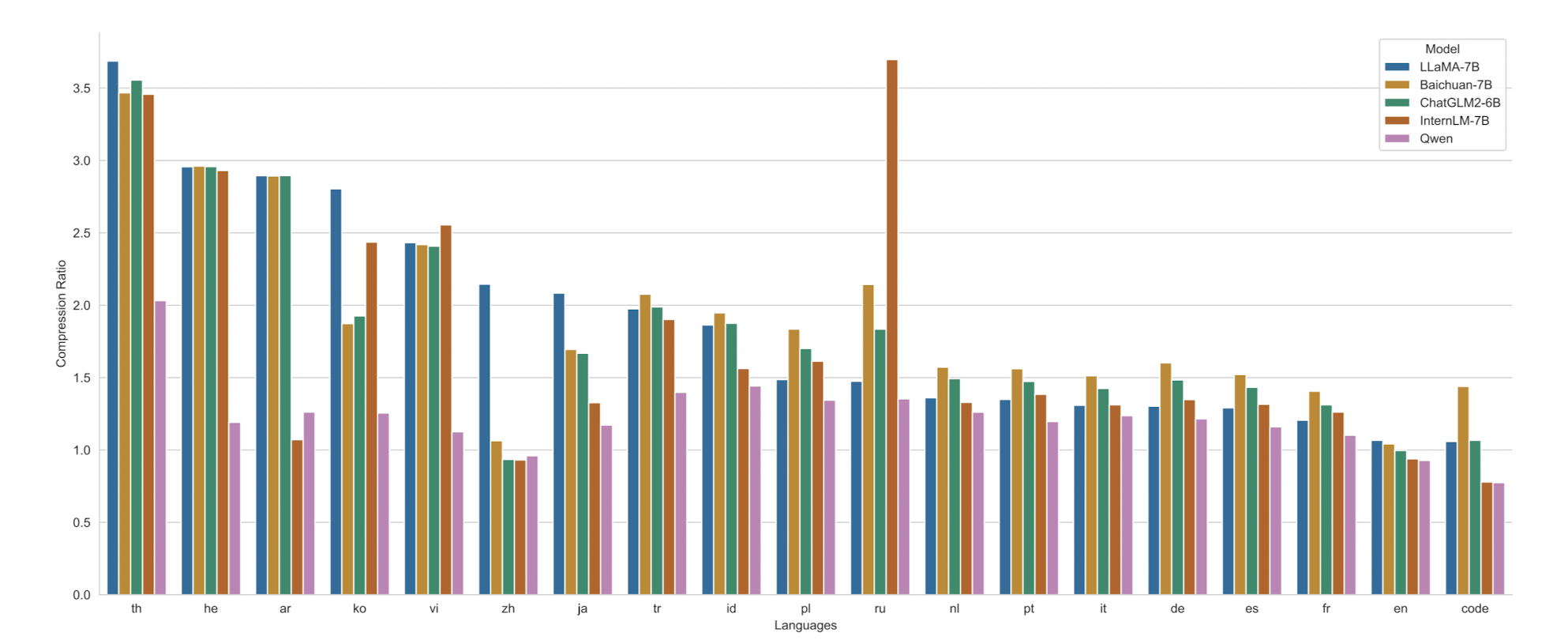
- Tokenization : byte pair encoding(BPE)를 사용했습니다. encoding compreesion 비율 그래프를 보면 다른 모델들 대비 긴 context를 잘 압축할 수 있다고 해석할 수 있습니다.
- Architecture : open-source LLM, LLaMA의 architecture를 채택했습니다. 변경 사항은 다음과 같습니다.
- Embedding and output projection : united embedding approach
- Positional embedding : RoPE (Rotary Positional Embedding), FP32 precision 사용
- Bias : QKV attention layer에 bias를 추가
- Pre-Norm & RMSNorm : 최근 가장 많이 사용되는 pre-normalizatoin 활용
- Activation function : Swish와 Gated Linear Unit을 결합한 SwiGLU 사용
- Training : 표준 autoregressive language modeling 방식을 따릅니다. 또한 학습 안정성을 위해 BFloat16 mixed precision을 사용합니다.
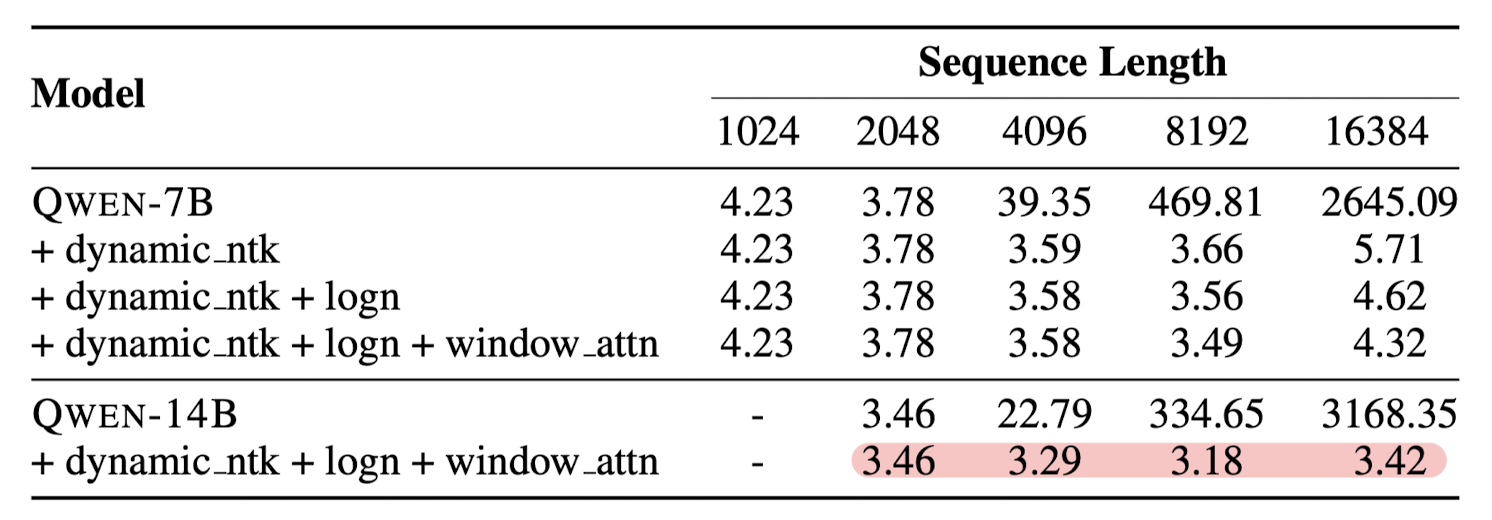
- Context Length Extension
- dynamic NTK-aware interpolation : chunck 단위로 scale을 dynamic하게 변경
- LogN-Scaling + window attention
- lower layer가 context length에 더욱 민감한 것이 확인됨 -> shorter windows for lower layers & longer windows for higher layers
Alignment
- Supvervised Finetuning
- Data : 다양한 스타일의 대화 데이터에 대해 annotation 수행. 고품질 데이터셋을 직접 확보
- Training : next-token prediction 방식으로 SFT. 단, system / user input에 대해서는 loss mask를 적용.
- Reinforcement Learning from Human Feedback
- fine-tuning 단계에서 Qwen 모델로부터 나온 response에 대한 human feedback을 바탕으로 reward model을 조정
- Qwen 모델과 동일한 사이즈의 사전 학습 모델을 reward 모델로 사용
- Preference Model Pretraining (PMP) vs Reward Model (RM)
- Proximal Policy Optimization (PPO) : the policy model, value model, reference model, reward model

- Automatic and Human Evaluation of Aligned Models
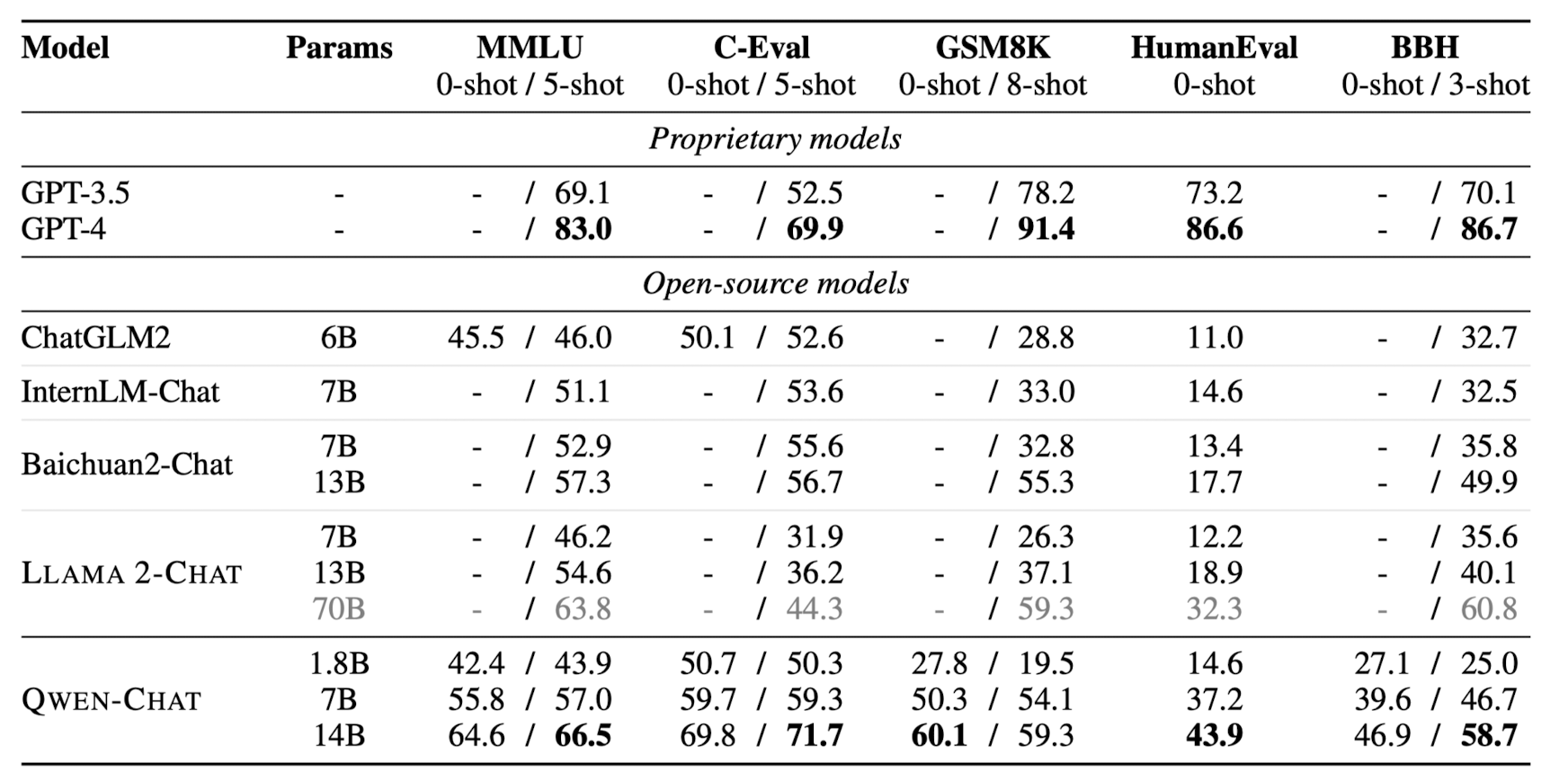
- zero / few shot 기준으로 모델 성능을 여러 벤치마크에 대해 평가
- 유사한 사이즈의 open-source 모델 대비 우월한 성능/퍼포먼스를 보여줌
- 하지만 GPT-3.5, GPT-4에 한참 미치지 못하는 성능
- Tool Use, Code Interpreter, and Agent
- 중국어 벤치마크에 대해 어느 정도의 성능을 보이는지 Qwen-Chat 모델과 GPT를 비교
- 여기에서는 GPT보다도 월등한 성능을 보여주었음
- unseen tools, Python code interpreter, Hugging Face's extensive collection 이용
- 마찬가지로 open-source 모델 대비 월등한 성능, but GPT 대비 열등한 성능
- 중국어 벤치마크에 대해 어느 정도의 성능을 보이는지 Qwen-Chat 모델과 GPT를 비교
기타
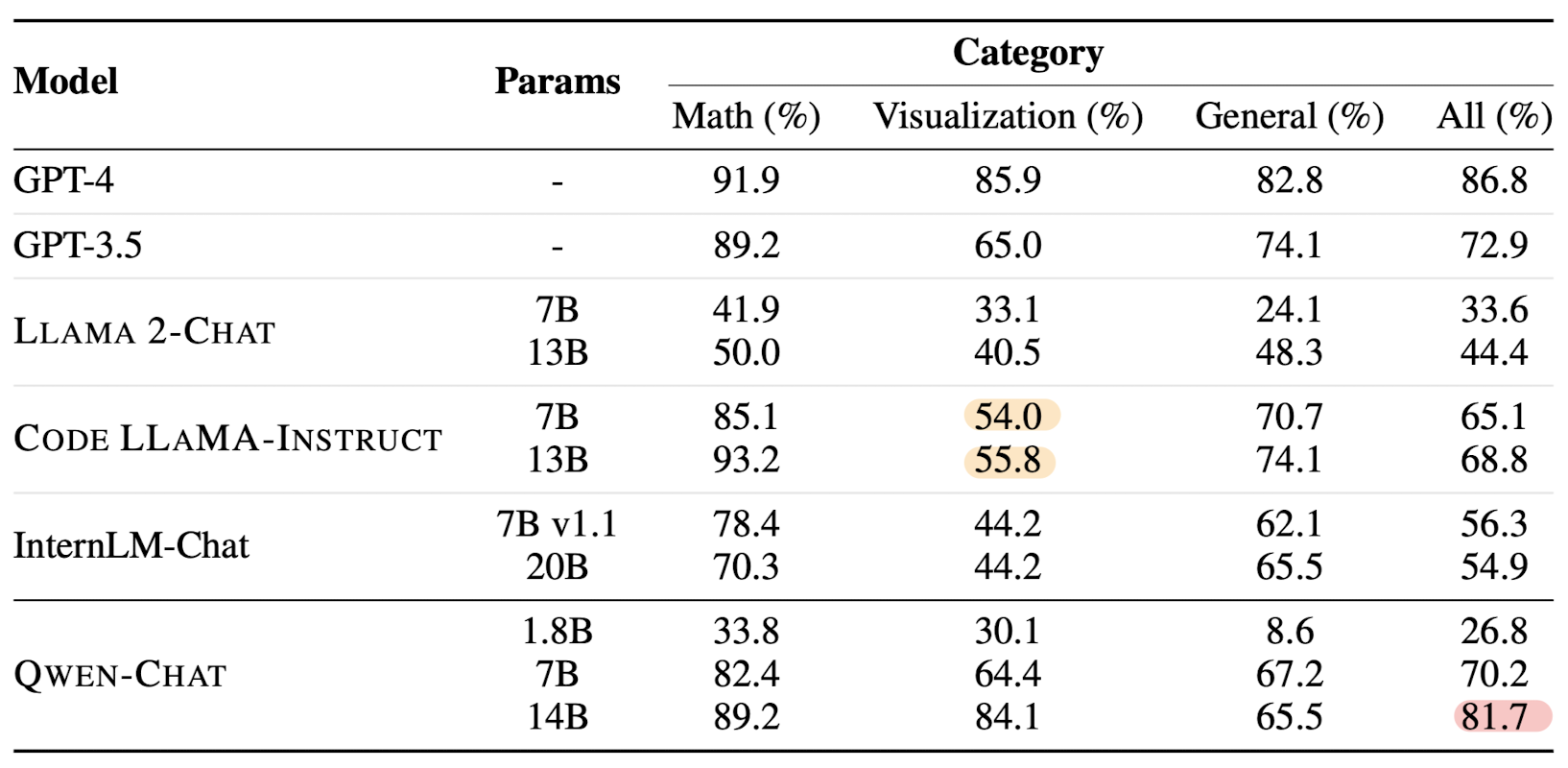
나머지 내용은 specialized model for specific tasks에 관한 내용입니다.
코드 관련 태스크를 수행하는데 특화된 모델을 fine-tuning 했거나, mathematics reasoning을 위한 fine-tuning 모델에 대한 설명이 정리되어 있습니다.
아주 간단히 요약하면,
코드 뿐만 아니라 범용적인 텍스트 데이터와 대화 또는 설명에 특화된 데이터를 고루 학습(fine-tuning)하는 것이 모델 성능 향상에 도움이 된다는 내용입니다.(너무 뻔한 내용 😓)
맨 처음 모델 가족도에서 확인할 수 있는 것이긴 하지만 상당히 흥미로운 것은 이러한 specialized model은 전부 CHAT 모델이라는 것입니다.
Code-Qwen-Chat, Math-Qwen-Chat, Qwen-VL-Chat. 이 세 모델은 각각 code, mathematical reasoning, visual and language 특화 모델들입니다.
사람이 주는 명령어(prompt)에 대해 대화형 챗봇처럼 잘 반응할 수 있도록 fine-tuning 되었다고 볼 수 있습니다.
개인적 감상
- 그래서 뭐가 다르지..?
성능적인 평가는 차치하고서라도 어떤 차별점이 있는 것인지 솔직히 알아차리기 어려운 것 같습니다.
맨 처음에도 MS사의 Wizard LM이 떠올랐다고 말씀드렸는데요, 더 생각해보자면 OpenAI의 GPT 모델 종류도 엄청나게 많단 말이죠.. 🧐
OpenAI API를 사용하려고 하면 수많은 모델 종류에 당황하게 되고, 각 모델이 어디에 적합한지 알아보는 것도 일인데요..
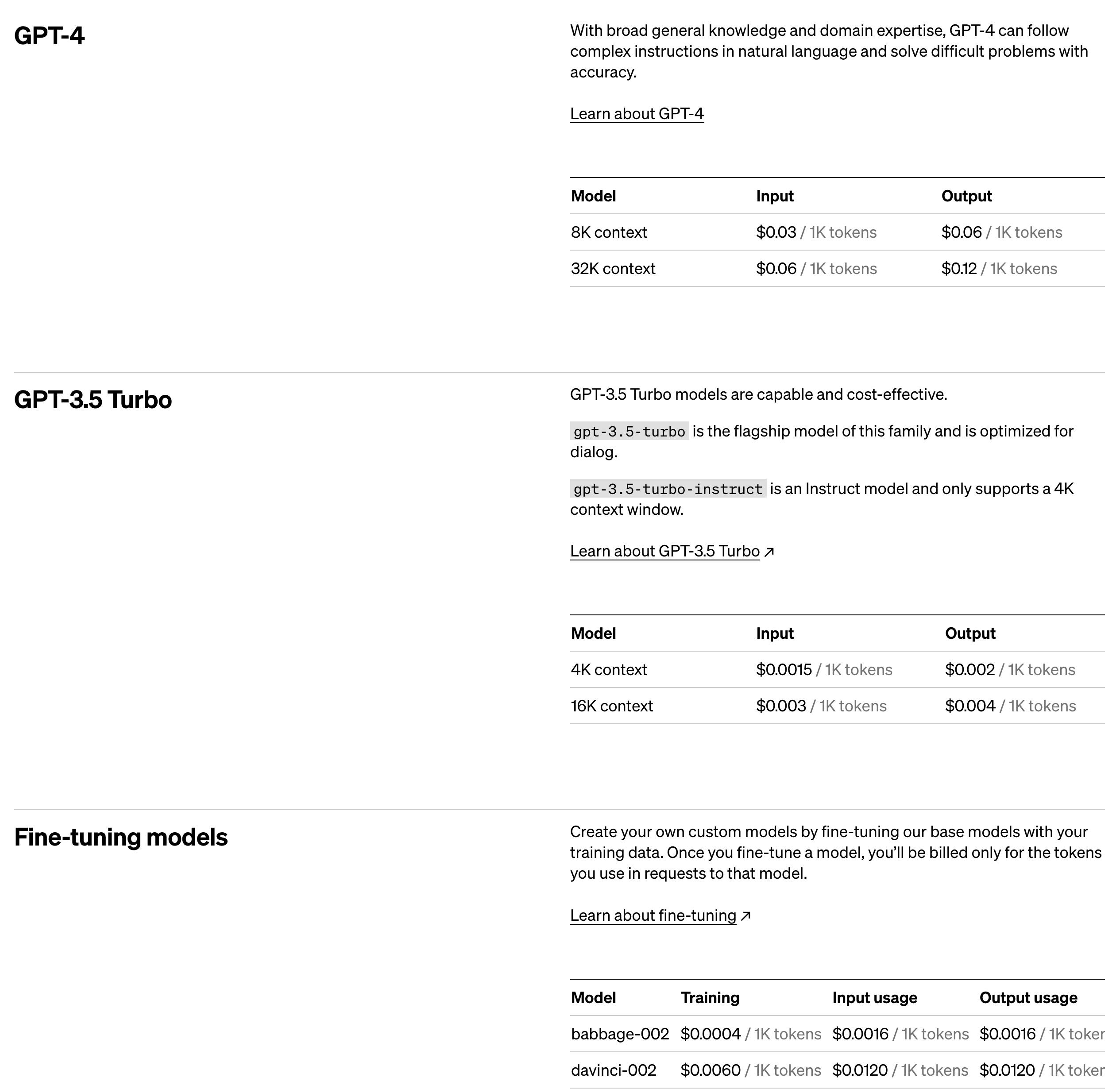
이것만 봐도 엄청나게 많은 모델 종류가 있는데(더 있습니다..), 학습된 여러 모델을 한꺼번에 출시했다는 것을 강점으로 내세운 걸까 싶기는 했습니다.
- 결국 open-source model 간의 경쟁인가?
최근 떠오르는 논문/모델들을 보면 죄다 open-source 모델 중 최강자라는 것을 contribution으로 내세우는 것 같습니다.
이미 GPT-3.5나 GPT-4 모델 정도만 되어도 엄청난 성능을 보여주기도 하고, 이것을 학습시키는데 들어간 자원량이 어마무시하게 많아서 그런지 이를 넘어서기 위한 연구나 실험은 이뤄지는 것이 지금 시점에서는 불가능한 것인가 싶기도 합니다.
더 많은 시간과 자원을 들여(윤리 문제.. 환경 문제 등 말이 많았죠) 더 거대한 모델이 태어나는 것 아니냐는 이야기도 무성했는데 그런 걱정은 좀 사그라든 분위기인 것으로 느껴집니다.
출처 : https://arxiv.org/abs/2309.16609
Qwen Technical Report
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large la
arxiv.org